What? 무엇을 진행하나요?
Redis에 대해 알아보겠습니다.
Redis의 특징에 대해 알아보겠습니다.
- MySQL과 다르게 relation이 없습니다.
- NoSQL 데이터베이스의 특성 중 하나인 key-value 형태로
데이터를 저장합니다.
- 캐시로 사용하여 굉장히 빠른 속도로 접근이 가능합니다.
Redis의 자료구조에 대해 알아보겠습니다.
- String
- 모든 종류의 문자열 저장이 가능합니다.
- HTML 조각이나 페이지의 캐싱 등에 사용할 수 있습니다.
- Hash
- key와 subkey를 통해 값을 저장합니다.
- 하나의 객체에 여러 개의 변수를 담는 구조라고 생각하면 됩니다.
- Sorted set
- 기본적으로 set이므로 key값의 중복을 허용하지 않습니다.
- value에 저장된 형태로 값을 저장합니다.
캐시(Cache)
데이터의 원래 소스보다 더 빠르고 효율적으로 접근할 수 있는 임시 데이터 저장소입니다.
[Cache] Write-through VS Write-around
- Write-through
CPU가 데이터를 사용하면 캐시에 저장되게 되는데, 이와 동시에 백업 저장소로의 저장도 진행하는 방법입니다.
장점 : 캐시와 백업 저장소에 업데이트를 같이 하여, 데이터 일관성을 유지할 수 있어서 안정적입니다.
단점 : 속도가 느린 주기억장치 또는 보조기억장치에 데이터를 기록할 때, CPU가 대기하는 시간이 필요하기 때문에 성능이 떨어집니다.
- 데이터 유실이 발생하면 안 되는 상황에서는 Write Through를 사용하는 것이 좋습니다.
- Write-around
데이터를 쓸 때 백업 저장소에는 쓰지 않고 캐시에만 업데이트를 하는 방법입니다. 필요할 때에만 주기억장치나 보조기억장치에 기록합니다.
장점 : Write Through보다 훨씬 빠릅니다.
단점 : 속도가 빠르지만 캐시에 업데이트하고 보조 기억장치에는 바로 업데이트 하지 않기 때문에, 캐시와 보조메모리의 값이 서로 다른 경우가 발생할 수 있습니다.
- 빠른 서비스를 요하는 상황에서는 Write Back을 사용하는 것이 좋습니다.
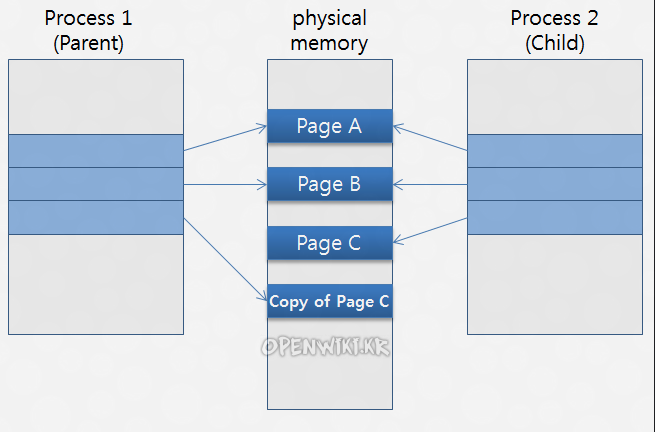
Copy-on-Write
Linux(Unix)에서는 자식 프로세스(child process)를 생성(fork)하면 같은 메모리 공간을 공유하게 됩니다.
그런데 부모 프로세스가 데이터를 새로 넣거나, 수정하거나, 지우게 되면 같은 메모리 공간을 공유할 수 없게 됩니다.
이때 부모 프로세스는 해당 페이지를 복사한 다음 수정합니다.
이것을 Copy-on-Write(COW)라고 합니다.
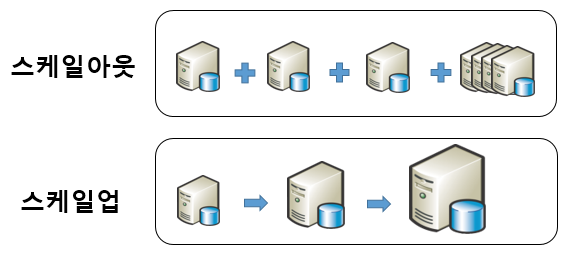
Scale out VS Scale up
- Scale out
- 접속된 서버의 대수를 늘려 처리 능력을 향상 시키는 것입니다.
- 개개의 처리는 비교적 단순하지만 다수의 처리를 동시 병행적으로 실시하지 않으면 안 되는 경우에 적합합니다.
- 웹서버나 검색엔진 데이터 분석 처리 등에 적용할 수 있습니다.
- Scale up
- 서버 그 자체를 증강하는 것에 의해 처리 능력을 향상시키는 것입니다.
- 정합성 유지가 어려운 데이터 베이스 서버에서 적합합니다.
- 온라인 트랜잭션 처리에 적용할 수 있습니다.
AOP VS RDB
- AOP
- Append Only File 방식으로 명령이 실행될 때마다 해당 명령이 파일에 기록됩니다.
- 데이터 손실이 거의 없습니다.
(거의라고 표현한 이유는 명령이 실행되면 바로 작성하는 것이 아니라, 버퍼에 두었다가 주기적으로 파일에 쓰는 방식이기 때문입니다.)
- RDB
- SAVE 혹은 BGSAVE 명령어로 RDB를 저장합니다.
- AOP 방식과 다르게 모든 명령어를 저장하지 않고, 데이터의 스냅샷을 저장합니다.
