3문제 챌린지
"파이썬 알고리즘 인터뷰"책의 문제들을 하루에 3문제씩 풀어보려고 한다.
6장 문자열 조작
Q1. 유효한 팰린드롬(LeetCode 125)
주어진 문자열이 팰린드롬인지 확인하라. 대소문자를 구분하지 않으며, 영문자와 숫자만을 대상으로 한다.
시행착오
팰린드롬 확인 시 문자열 시작과 끝, 양쪽에서 확인하려고 하였다.
이 경우 'race a car'을 비교하는 과정에서(공백 제외)
3,4번째 index를 비교하는 과정에서 false가 발생할 것이라고 예상했다.
사용한 풀이
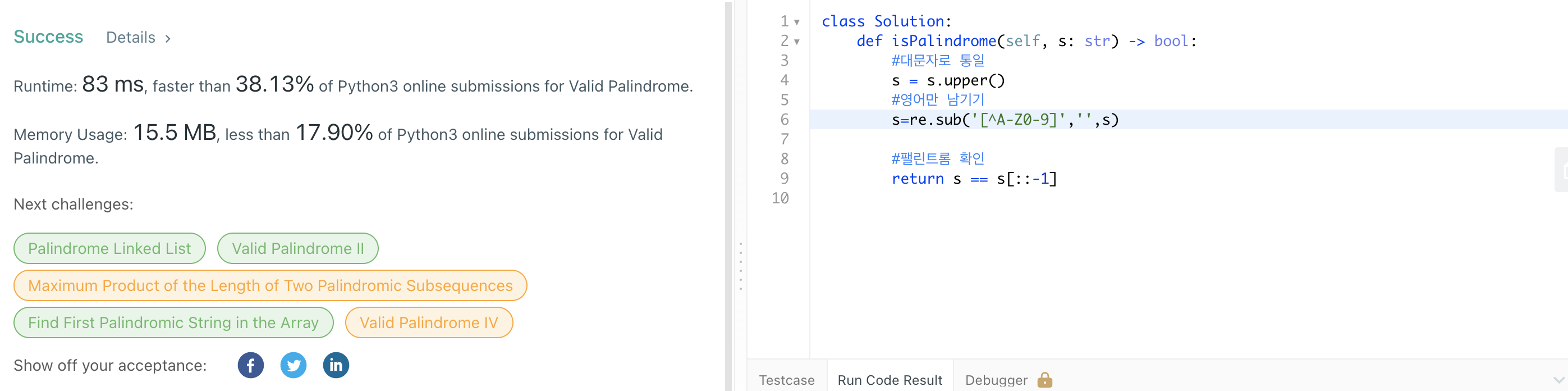
✔️ 불필요한 문자 제거
#문자열 통일을 위한 대문자화
s = s.upper()
#정규식으로 문자 필터링
s = re.sub('^A-Z0-9', '', s)re.sub(s1, s2, s)
s라는 문자열에서 s1을 s2로 변환한다.
^: 뒤에 적힌 문자들을 제외한 모든 문자
따라서 현재 사용한 구문을 해석해보면,
'^A-Z0-9'(대문자와 숫자)를 제외한 모든 문자들을 삭제하게 된다.
✔️ 팰린드롬 확인
s == s[::-1]Extend Slicing: 사용한 코드의 경우, -1번째 부터 시작하는 문자열이다.
즉, reverse 시킨 문자열이다.
파이썬을 사용할 때 가장 유용하게 사용하는 기능 중 하나다.
책에 적힌 3개의 풀이 중에서도 실행 속도가 36ms로, 가장 좋은 성능을 보였다.
최종 코드 & 제출 결과
책에 나온 풀이
풀이 2: 데크 자료형을 이용한 최적화
- 데크(Deque): 양방향 큐
양방향에서 element를 추가하거나, 삭제할 수 있다.#자료형 데크로 선언 strs: Deque = collections.deque() for char in s: if char.isalnum(): strs.append(char.lower()) while len(strs) > 1: if strs.popleft() != strs.pop(): return False return True리스트 변환 후, for문을 사용했던 책의 풀이 1(304ms) 대비
실행속도 64ms로, 속도를 5배 높일 수 있다.
리스트의 pop(0)이 O(n)인데 비해, 데크의 popleft()는 O(1)이기 때문이다.
총 구현 시간을 비교하면,
리스트 구현은 O(n^2), 데크 구현은 O(n)으로 성능 차이가 크다.
- 성능이 Extend Slicing보단 나빴지만, 새로 접하는 자료형이기 때문에 공부할 필요성을 느꼈다.
- 리스트를 사용하는 문제에서 적절하게 활용하면 좋을 것 같다.
Q2. 문자열 뒤집기(Leet Code 344)
문자열을 뒤집는 함수를 작성하라. 입력값은 문자 배열이며, 리턴 없이 리스트 내부를 직접 조작하라.
시행착오
for문을 활용하여 뒤집기
하지만 이 방법을 사용할 경우, 비효율의 극치일 것이라고 생각했다.
사용한 풀이
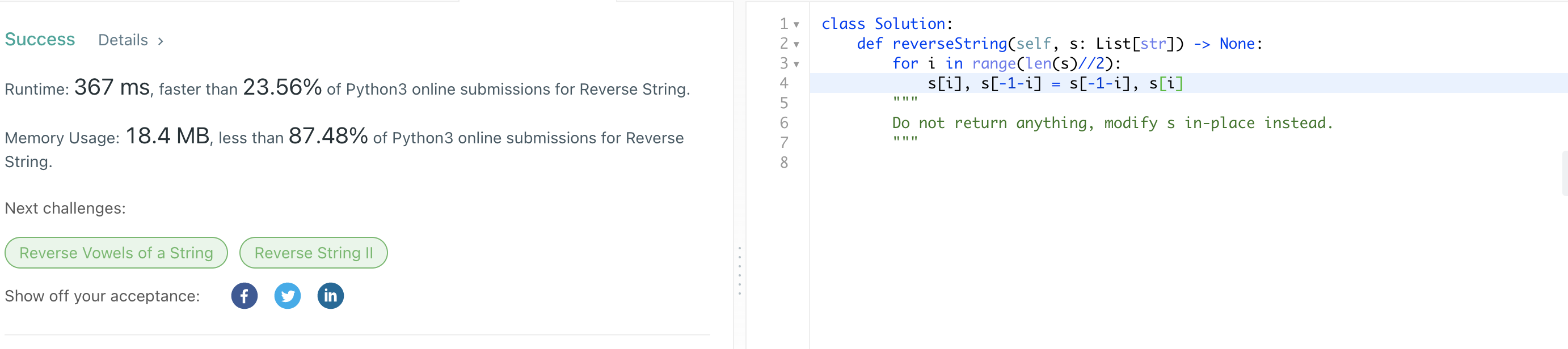
✔️ 새로운 idea:
좀 더 효율적으로, 파이썬의 장점을 살릴 수 있는 방법은 없을까 고민했다.
그렇게 서치 끝에 발견한 구문이다.
a,b = b,ctemp라는 변수를 사용하지 않고 바로 swap 할 수 있다는 것.
최종 코드 & 제출 결과
책에 나온 풀이
더 효율적인 코드를 알아보자.
- s.reverse(): List에서만 적용되는 함수.
문자열일 경우 Slice사용.(Slice는 list, 문자열 모두 가능)단, 이 문제의 경우 단순 Slicing이 먹히지 않는다.
문제가 공간 복잡도를 O(1)으로 제한했기 때문.
따라서 s[:] = s[::-1]로 사용해야함.
Q3. 로그 파일 재정렬(LeetCode 937)
로그를 재정렬하라. 기준은 다음과 같다.
1. 로그의 가장 앞 부분은 식별자다.
2. 문자로 구성된 로그가 숫자 로그보다 앞에 온다.
3. 식별자는 순서에 영향을 끼치지 않지만, 문자가 동일할 경우 식별자 순으로 한다.
4. 숫자 로그는 입력 순서대로 한다.
아이디어
어려운 문제였기 때문에, 큰 문제를 작은 문제로 나누는 과정부터 거쳤다.
- 로그와 식별자 구분
- 문자와 숫자 비교
- 숫자의 인덱스 기억 및 순서대로 정렬
사용한 풀이
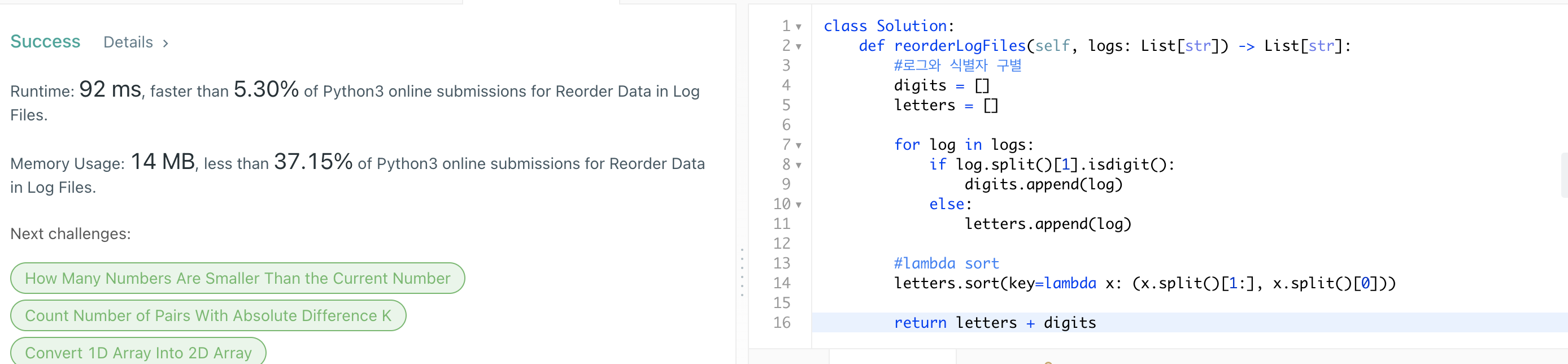
✔️ 로그와 식별자 구분
#식별자
identifier = log.split[0]
#식별자를 제외한 로그
log_only = log.split[1:]Slicing을 통해 로그를 식별자/로그 only로 구분하였다.
✔️ 문자와 숫자 비교
letters = [] #문자 로그
digits = [] #숫자 로그
#로그 첫글자로 문자, 숫자 로그 구분하여 저장
for log in logs:
if log.split[1].isdigit():
digits.append(log)
else:
letters.append(log)위에서 식별자와 로그를 구분해냈으니, 로그의 시작을 통해 문자/숫자 로그를 구분할 수 있다.
✔️ 숫자의 인덱스 기억 및 순서대로 정리
letters, digits라는 리스트로 문자/숫자 로그들을 구분하여 저장하였다.
따라서 순서대로 정렬하는 일만 남았는데, 이와 관련된 아이디어는 책을 통해 얻었다.
책에서 얻은 아이디어
람다(Lambda) 정렬: 기준이 되는 key를 통해 원하는 방식으로 정렬이 가능.letters.sort(key=lambda x: (x.split()[1:], x.split()[0]))변수.sort(key=lambda x: (x1, x2)
x1을 기준으로 정렬하고, x1이 동일할 경우, x2를 기준으로 후순위 정렬한다.
최종 코드 & 제출 결과
새로 배운 개념
- Slicing으로 reverse하기
- Deque 자료형
- 파이썬 swap 방법
- Split 사용법
- Lambda Sort
