목차
1. Stack
2. Queue
3. Stack과 Queue차이점
4. Array
5. Linked List
6. Array와 Linked List의 차이점
1. Stack이란
목차로이동
FILO(First-In-Last-Out) 으로 이루어진 자료구조로
영어 그래도 처음 들어간것은 마지막에 나온다 이다.
말로 설명하기 보다는 그림으로 보는게 쉽다.
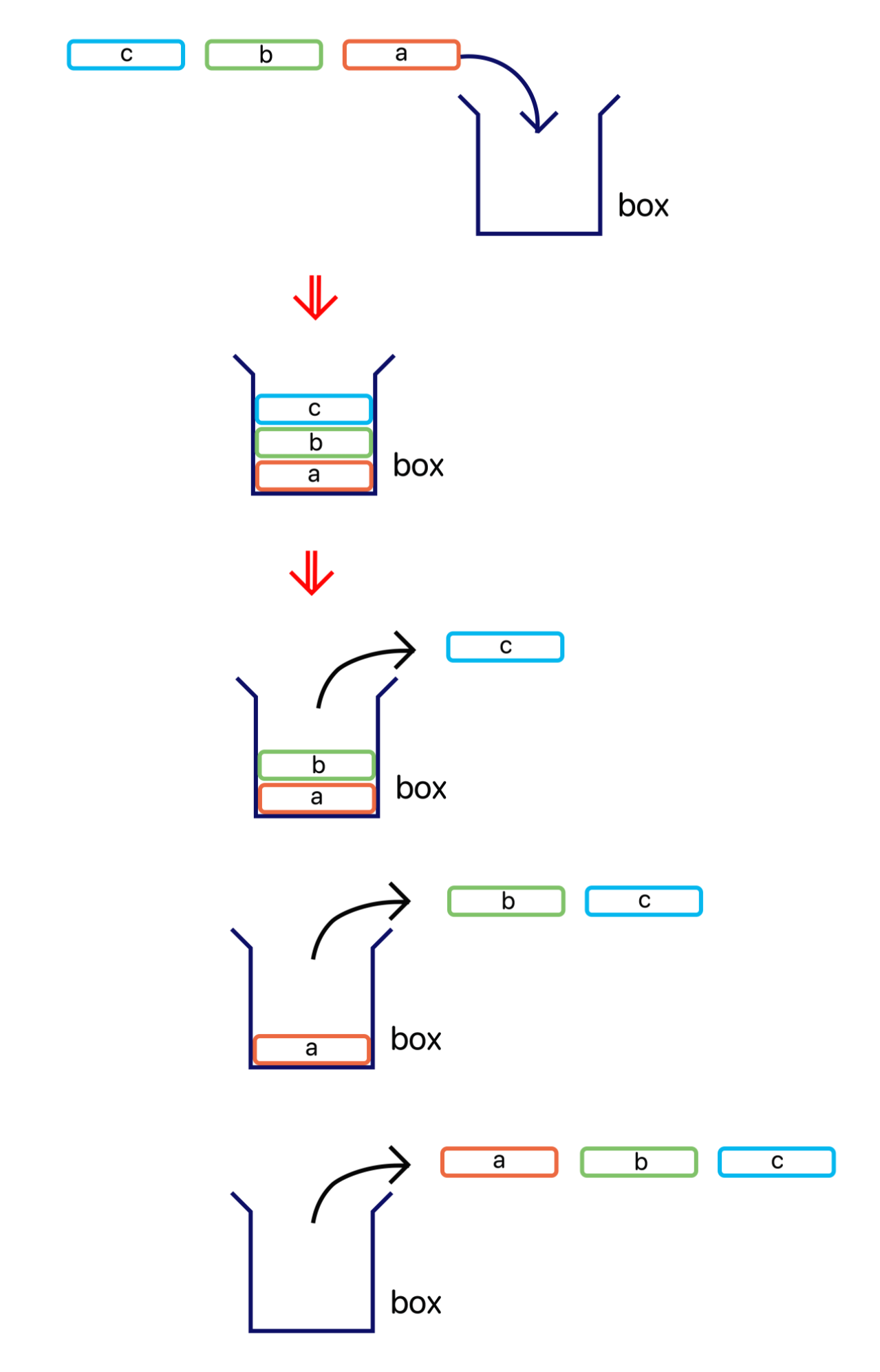
위에 그림을 보면 a부터 a -> b -> c 순으로 상자 안에 들어간다. 하지만 나오는 순서는 c -> b -> a 순으로 나온다.
작은 크기부터 넣어서 큰 것부터 확인 한다거나 앞에서 부터 넣고 뒤에서 부터 빼면서 확인해야하는 알고리즘을 짤때 좋은것이 스택이다.
자바에서는 최상위 객체인 Object를 이용하여 구현하여 제공한다. 그로인해 모든 것이 들어갈 수 있어 제네릭 사용이 가능하다.
구현체로는 ArrayList로 구현하는게 좋다.
스택의 활용 예시 (후입선출)
1.웹 브라우저 방문기록 (뒤로 가기) : 가장 나중에 열린 페이지부터 다시 보여준다.
2.역순 문자열 만들기 : 가장 나중에 입력된 문자부터 출력한다.
3.실행 취소 (undo) : 가장 나중에 실행된 것부터 실행을 취소한다.
4.수식의 괄호 검사 (연산자 우선순위 표현을 위한 괄호 검사)
2. Queue
목차로이동
FIFO(Frist-In-Frist-Out) 처음들어간게 가장 먼저 빠져 나간다인데 구현하는 것에 따라서 달라 질수도있다.
컬렉션 큐를 쓴다면 처음들어가는 것을 처음 나가겠지만 말이다.
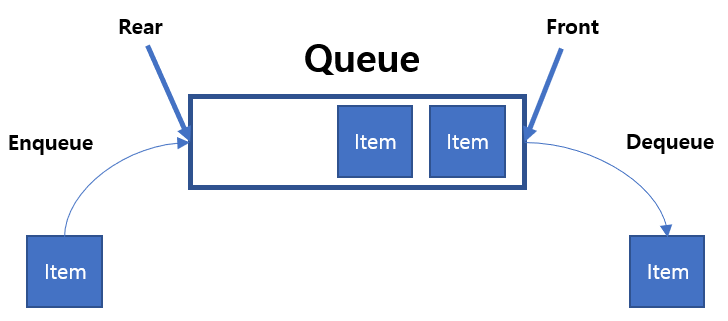
Enqueue : 큐 맨 뒤에 데이터를 추가
Dequeue : 큐 맨 앞쪽의 데이터를 삭제
그래프 넓이 우선 탐색(BFS)에서 사용된다.
컴퓨터 버퍼에서 주로 사용, 마구 입력이 되었으나 처리를 하지 못할 때, 버퍼(큐)를 만들어 대기 시킨다. 먼저 들어온 입력먼저 처리
구현체로는 LinkedList로 구현하는게 좋다.
어째서인가 큐는 항상 첫 번재 저장된 데이터를 삭제하므로, ArrayList와 같은 배열 기반의 자료구조를 사용하게 되면 빈공간을 채우기 위해서 데이터의 복사가 발생하므로 매우 비효율적입니다.
큐의 형태로 원형큐(Circular Queue)와 Deque가 있는데
원형큐의 경우 범위를 정해놓고 키우지 않고
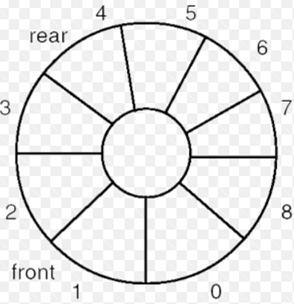
이런형태로 범위들이 동작하도록 만들었다.
뒷부분(Rear) 8번인데 앞부분(Front)가 3번에 있다 그리고 삽입이 들어왔다하면 0번으로 뒷부분이 바뀌면서 삽입되는 것이다.
구현체로는 ArrayList가 있다.
Deque의 경우 앞에서 삭제 뒤에서 삽입만 되는 큐와는 다르게 앞에서 삭제와 삽입이 그리고 뒤에서도 삽입과 삭제가 가능하다. 구현체로는 ArrayList와 LinkedList가 있다.
큐의 활용 예시 (선입선출)
1.우선순위가 같은 작업 예약 (프린터의 인쇄 대기열)
2.은행 업무
3.콜센터 고객 대기시간
4.캐시(Cache) 구현
3. Stack과 Queue차이점
목차로이동
1. 스택은 맨뒤에서만 부터 삽입 삭제를 하기때문에 Array로 하는것이 언제나 O(1)이기 때문에 그렇고 큐의 경우 삽입이 뒤에 삭제가 앞부분이라 삽입 삭제가 빠른 LinkedList를 사용한다.
2. 스택은 하나의 형태가 있으나 큐는 구현 하는 방식에 따라 달라 질 수 있다.
3. 스택은 FILO, 큐는 FIFO이다.
4. Array
목차로이동
내부적으로 배열형태를 가지고 있으며 인덱스를 활용한 탐색이 가능하다. 앞이나 중간에 삽입할때 내용을 전체 복사해서 새로운 배열에 넣어야 하는 작업을 하게된다.
이것을 뒤로 옮기는 형태로 만들면 된다 하는데.. 인덱스를 활용한 탐색으로 빠르게 하는것인데 그렇게 옮기면 인덱스를 활용한 탐색이 의미가 없어보인다.

이런 형태로 되어있다고 해보자 그러면 순서 정렬이 되어있지 않으니 어디 삽입하든 삽입 위치의 내용을 뒤로 보내면 될것이다. 크기가 충분하다는 가정 하에 말이다. 만약 복사해야 한다면. 그냥 한칸씩 뒤로 이동시켜서 하는게 좋을 것이다.
5. Linked List
목차로이동
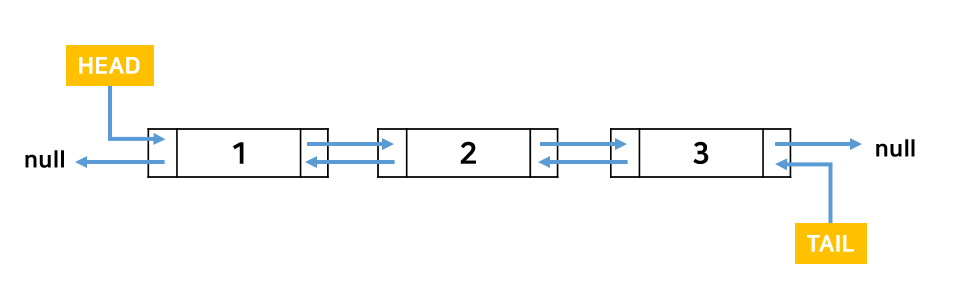
JAVA LinkedList를 보게 되면 LinkedList는 이중 연결 리스트의 형태를 가지고 있음을 알 수 있다.
get / set
LinkedList는 연결 리스트 형태를 띄고 있기 때문에 해당하는 index에 대한 값을 얻어올 때 시작이나 끝에서부터 해당 index까지 순차적으로 접근하며 값을 얻어온다.
따라서, 시간 복잡도는 O(n)을 가진다
add, reade
일반적인 경우
추가나 삭제를 원하는 index에 도달할 때까지 순차 접근을 하는 시간복잡도 O(n)
index-1의 노드의 next와 index+1의 prev를 새로 추가한 노드에 연결하는 작업은 n에 영향을 받지않는 상수 시간이기 때문에 O(1)이다
따라서, O(n)의 시간복잡도를 가진다
시작이나 끝에 요소를 추가나 삭제할 때
LinkedList는 head와 tail을 갖는 doubleLinkedList의 구조이기 때문에 시작과 끝에 해당하는 노드을 찾아가는데는 O(1)이라는 시간 복잡도를 갖게된다
따라서, 시간 복잡도는 O(1)이다.
6. Array와 Linked List의 차이점
일반적으로 get/set을 자주 사용한다면? ArrayList
처음이나 끝에 잦은 삽입, 삭제가 발생한다면? LinkedList
하지만, 공간 복잡도의 경우 ArrayList는 연속된 메모리안에 저장되므로 낭비되는 공간이 없기 때문에 종종 속도가 더 빠른 경우가 발생하기도 한다. LinkedList는 요소마다 두개의 참조 노드가 필요하기 때문에 더 많은 공간을 차지하고, 메모리 여기저기 노드가 흩어져 존재하는 경우 효율이 더욱 떨어질 수 있으니 잘 선택하자!
참고자료
Stack과 Queue
st-github
고코딩
Array와 Linked list
그냥 그냥 블로그
delftStack
