2. Index란 무엇인가?
3. INSERT, UPDATE, DELETE가 자주 발생하지 않는 테이블 대처법
4. Index 인덱스를 사용한 검색방법
5. Index Clustering과 non-Clustering
1. DI란 무엇인가?
목차로 이동
스프링 프레임워크에서 기본적으로 제공하는 기능으로서
외부에서 두 객체 간의 관계를 결정해주는 디자인 패턴으로
클래스 사이의 의존관계를 빈 설정 정보를 바탕으로 컨테이너(IOC)가
자동적으로 연결해주기 때문에 개발자들은 제어할 필요없이
빈 설정 파일에 의존관계가 필요하다는 정보만 추가해주면 된다.
자신이 선언해둔 참조형에 IOC 컨테이너가 적절한 클래스를 찾아서 내용을 넣어줘서 두 클래스간의 관계(의존성)을 맺어주는 것을 의존성 주입(DI: depndency Injection)이다.
의존성 주입에는 생성자 주입(자동), 필드 주입(수동), 수정자 주입 등 다양한 주입 방법이 있는데, Spring 4이상은 개발팀에서는 생성자 주입을 권장하고 있다.
하지만 DI가 작동되는 것은 IOC 컨테이너가 해주는 것이므로 IOC컨테이너에 대해서도 알고 있어야한다.
DI의 장점은 무엇인가?
- 클래스를 재사용 할 가능성을 높이고, 다른 클래스와 독립적으로 클래스를 테스트 할 수 있다.
- 비즈니스 로직의 특정 구현이 아닌 클래스를 생성하는데 매우 효과적이다.
2. 인덱스
인덱스는 목차가 아닌 맨뒤 페이지의 내용이 몇페이지에 있다고 알려주는 색인에 가까운것이다.
추가적인 쓰기 작업과 저장 공간을 활용하여 데이터베이스 테이블의 검색 속도를 향상시키기 위한 자료구조 이다.
데이터베이스에서도 테이블의 모든 데이터를 검색하면 시간이 오래 걸리기 때문에 데이터와 데이터의 위치를 포함한 자료구조를 생성하여 빠르게 조회할 수 있도록 돕고 있다.
인덱스를 활용하면 데이터를 조회하는 SELECT외에도 UPDATE나 DELETE의 성능이 함께 향상된다. 해당 연산을 수행하려면 대상을 먼저 조회해야 작업을 할 수 있기 때문에, SELECT 성능이 향상됨에 따라 함께 성능이 향상된다.
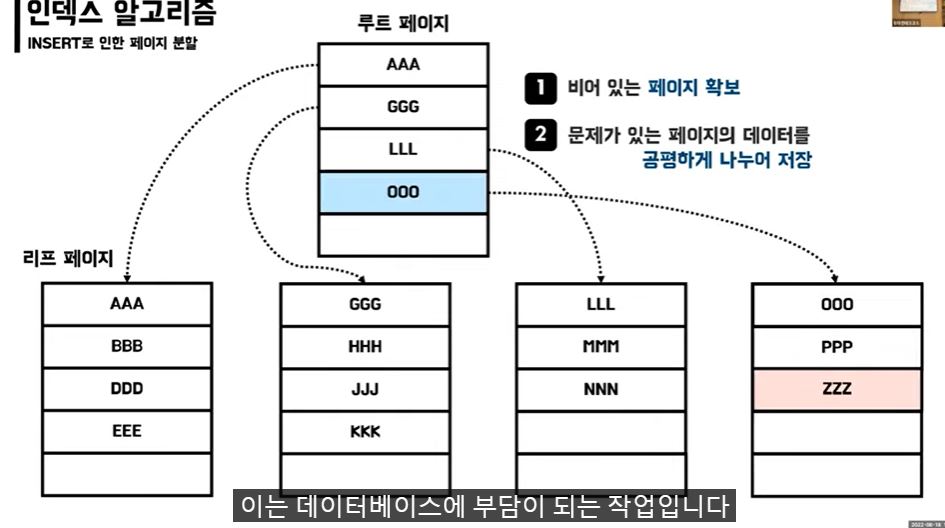
하지만 UPDATE나 DELETE후 다시 Index를 바꾸는 동안에는 그동안 조회가 불가하며 Index정보가 남아있어 그것까지 확인 후 조회시 오래걸리기 때문에 index 최적화전 까지는 성능이 떨어질 수 있다.
인덱스를 사용하는 이유는 무엇인가?
인덱스의 가장 큰 특징은 데이터들이 정렬되어 있다는 것이다. 이 특징으로 인해 조건 검색에서 강점을 가진다.
데이터가 쌓여 순서없이 뒤죽박죽으로 저장되면 Where 조건 검색, Order by 정렬을 수행할 시 Full Table Scan을 하게 속도도 느려지고 부하가 걸릴 수도 있다.
그런데 적절히 인덱스를 사용하게 되면 이미 정렬이 되어 있기 때문에 빠르게, 전반적인 자원의 소모없이 해당 작업을 수행할 수 있다.
단점
- 인덱스를 관리하기 위해 DB의 약10%에 해당하는 저장공간이 필요하며, 추가적인 작업을 해야한다.
- 인덱스를 잘못 사용할 경우 오히려 성능이 저하되는 역효과가 일어날 수 있다.
그럼에도 인덱스를 쓰는 인덱스의 장점
- 테이블을 조회하는 속도와 그에 따른 성능을 향상시킬 수 있다.
- 전반적인 시스템의 부하를 줄일 수 있다.
그러면 인덱스는 언제 사용하면 좋을까?
- 중복된 데이터가 적은 컬럼
- JOIN이나 WHERE 또는 ORDER BY에 자주 사용되는 컬럼
- 규모가 작지 않은 테이블
- INSERT, UPDATE, DELETE가 자주 발생하지 않는 컬럼
보면
-
INSERT, UPDATE, DELETE가 자주 발생하지 않는 컬럼 으로 되어있는데
이것은 올바른것 같지 않다.
삽입은 한 열이 되기 때문에
하나의 열이 삽입 추가 삭제되는 순간 INDEX를 바꿔줘야한다.
그러니 두개의 경우테이블로 바꿔주는게 옳은 것 같다. -
INSERT, DELETE가 자주 발생하지 않는 테이블
3.INSERT, UPDATE, DELETE가 자주 발생하지 않는 테이블 대처법
목차로 이동
INSERT, UPDATE, DELETE가 자주 일어나지 않는 Table을
core 테이블로 자주 일어나는 테이블을 하위 테이블로 만들고
core 테이블에 Index를 적용 하는 방법이 있습니다.
그러니까
public User{
private String username;
private String password;
private String nickName;
private String email;
}위 와 같이
유저이름, 패스워드, 닉네임, 이메일이 있습니다.
여기서 변경될 가능성이 있는 것과 없는것에는 무엇이 있을까요?
상황에 따라 다르겠지만
유저이름이 있다면 유저이름을 통해서 로그인을 하겠죠
저기서 유저이름이 없다면 이메일로 로그인 할겁니다. 유저이름을 쓰지도 않고 이메일로 로그인 하는데 유저이름을 받을 필요는 없겠죠?
그렇다면 위 테이블은 두개로 분리가 됩니다.
public UserCore{
private String username;
}
public UserSub extends UserCore{
private String password;
private String nickName;
private String email;
}주의할점 만약 Unique를 선언해준 컬럼이 있다면 자동으로 index가 만들어질태니 core테이블에 넣어줘야한다.
유저이름은 변경되지 않기때문에 계속 인덱스를 통해서 검색이 가능합니다.
물론, 회원이 추가되거나 탈퇴하지 않는 다는 전제하에요
하지만 업데이트에 관해서는 Core 테이블은 아예 상관이 없어집니다. 변경이 없으니까요
이렇게 내용이 변경되지 않는 것을 Core 테이블로 만들어 놓고 인덱스 조각화를 관리해 주는것이 적은 컬럼갯수로 인하여 관리도 편할 것이다.
솔직히 Update면 모를까 insert와 delete가 이루어지지 않는테이블에
자료가 많을까? 적을까? 그 사이트가 작동이 잘되는걸까? 안되는걸까?
저로서는 안되는 거고 적을꺼라 생각합니다
물론 용량마다 따로 테이블을 나눠서 할 수 있습니다
그러면 어쨋든 다른 테이블에 insert가 이루어지고 있는것이 아닌가 인덱스로 이루어진 core테이블은 최소한의 컬럼을 유지하며 insert와 delete로 인한 인덱스의 조각화발생으로 성능이 떨어지지 않게 유지해주는 것이 중요하다
아래 사이트 가서 한번 이런 방식이 있다는 것을 보면 될것같다.
MSSQL 조각화 확인 및 해결
4. 인덱스를 사용한 검색방법
목차로 이동
full table sacn, 해쉬 인덱스, B 트리 인덱스, B+ 트리 인덱스
full table sacn(privmary key는 인덱스(clustered index 라고 부른다)를 가지고있다. 이것을 통한 탐색이다)
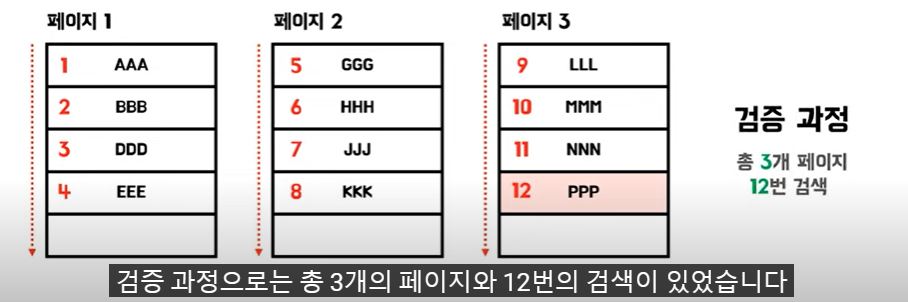
1. 적용 가능한 인덱스가 없는 경우
2. 인덱스 처리범위가 넓은 경우
3. 크기가 작은 테이블에서 검색할 경우
해쉬 인덱스
우아한테크 영상 링크
B 트리
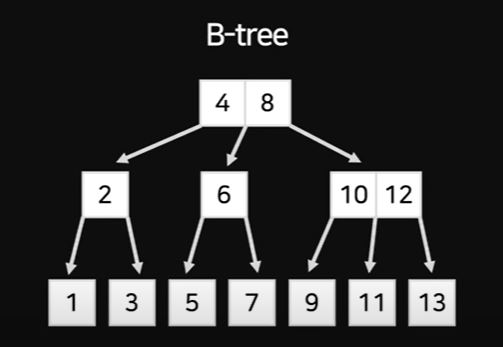
B+ 트리
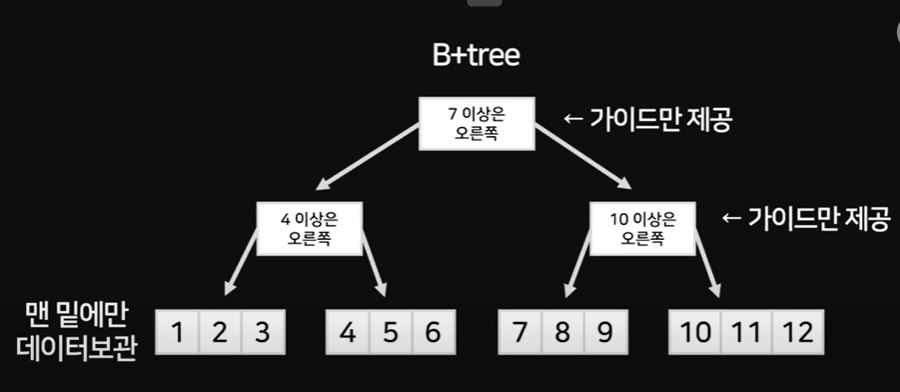
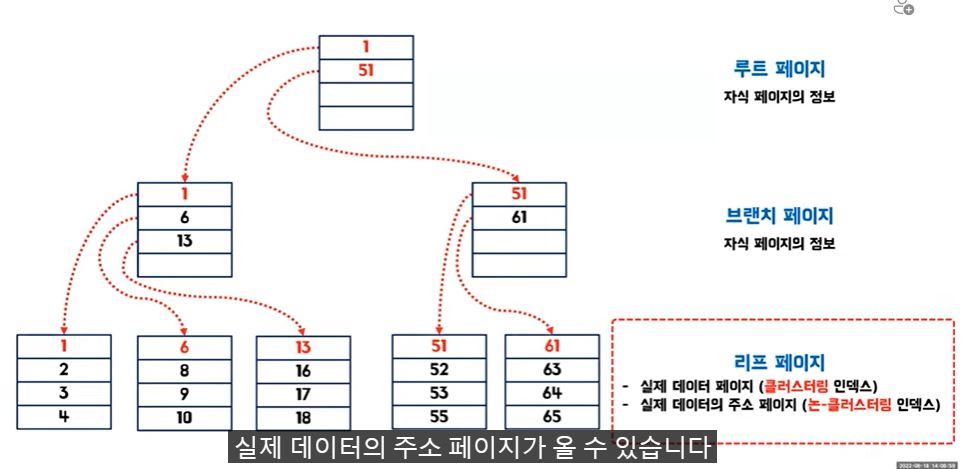
5. 클러스터링 인덱스와 논-클러스터링 인덱스
목차로 이동
|클러스터링 | 논 - 클러스터링|
|--|--|
|실제 데이터와 무리의 인덱스 |실제 데이터와 다른 무리의 인덱스|
클러스터링 : 가나다순으로 정렬된 사전과 같은 역할
- 실제 데이터의 정렬이 이루어 진다.
- 실제 데이터 자체가 정렬
- 테이블당 1개만 존재 가능
- 리프페이지(데이터 페이지의 주소)와 데이터 페이지(실제 데이터)
- 아래의 제약조전시 자동생성
-1.primary key(우선순위)
-2.unique + not null(함께 걸어줘야한다)- 1번과 2번두개가 같이걸리게 된다면 primary key를 가지고 인덱스를 생성하게 된다.
논클러스터링 : 찾아보기 페이지 같은 역할
- 실제 데이터의 변경 없이 페이지는 그대로 존재한다.
- 별도의 인덱스 페이지 추가구성 - > 추가공간이 필요하다
- unique 제약조건 추가
- 중복 불가 - index 직접 생성
- 중복 허용 - 리프페이지(데이터의 주소 페이지+ 위치)와 데이터 페이지(실제 데이터)
- 리프페이지에 실제 데이터 페이지 주소를 가지고 있다.
-테이블당 여러개 존재할수도있다.(인덱스로 직접생성시)
primarykey id -> 클러스터링 B트리를 이용하여 데이터를 조회
unique가 선언된 컬럼 -> 논 클러스터링 B트리
6. 카디널리티
어떤 컬럼에 인덱스를 적용해야 할까?
카디널리티(그룹 내 요소의 개수)가 높은것 = 중복 수치가 낮은 것
남여와 같이 2개거나 사람과 동물 처럼 2개 중복수치가 높은 것에는 사용하면 안된다.
이메일과 유저이름처럼 들어오는 사람마다 다른것에 적용해야한다.
조금 느린 쓰기를 감수하고 빠를 조회를 이용하는 것이 좋다
그 이유는 쓰기와 조회의 비율이 1:9~ 2:8 로 조회가 압도적으로 많기 때문이다.
