1. JPA란 무엇인가
스프링에서 SQL문이 아닌 Method를 통해서 DB를 조작하는것이다.
그로인하여 개발자는 객체 모델을 이용하여 비즈니스 로직을 구성하는데만 집중할수있다. 그로인하여 코드의 가독성을 높이게 되었다.
그러나 단점도 있었는데 복잡하고 무거운 Query는 속도를 위해 별도의 변경사항이 필요하기 때문에 SQL문을 써야할수도있고 학습비용이 비싸다.
2. ERD만들어보기
생각보다 DB를 구성하는 방법을 고민하게 되는데 JPA를 편하게 만들수있는데.. 단점으로는 ERD를 잘못만드는순간 JPA도 잘못짜게 되는 단점이있으니 만들때 신중하게 만들어야한다.
3. Dto를 사용하는이유
디비의 내용에서 너무 많은 데이터를 가져와서 낭비 하지 않고 필요한 데이터만 가져오기 위해서 사용하거나 DB의 내용을 다른자가 마음대로 바꾸는 것을 방지하기 위해서 사용한다.
4. EAGER(즉시로딩), LAZY(지연로딩)
@ManyToOne 매핑의 기본 fetch가 EAGER라서 생략해도 EAGER로 동작한다
(fetch = FatchType.EAGER)와(fetch = FatchType.LAZY)
EAGER(즉시로딩), LAZY(지연로딩)
EAGER는 사전적 의미인 열심인, 열렬한 처럼 Member를 조회하면 연관관계에 있는 Team 역시 함께 조회는 반면에, LAZY는 게을러서 Member만 조회해오고 연관관계에 있는 나머지 데이터는 조회를 미룬다.
EAGER는 N+1만큼의 문제(쿼리를 날린다)를일으킨다.
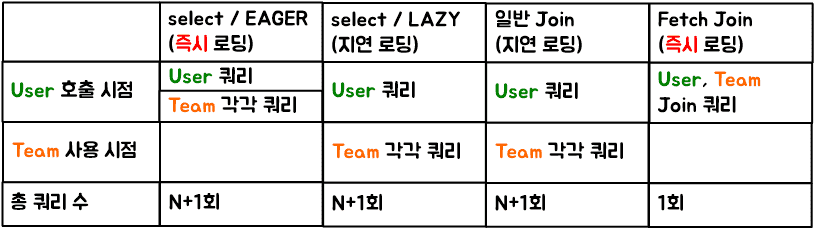
지연 로딩(LAZY로 설정)
- 멤버 전체를 조회하기 위해 JPQL 실행 select m from member m
- JPQL은 EAGER와 무관하게 SQL로 그대로 번역 -> select m.* from member
- JPQL 결과가 member만 조회하고, team은 조회하지 않음
- member와 team이 지연 로딩으로 설정되어 있기 때문에 가짜 프록시 객체를 넣어두고, 실제 회원은 팀은 조회하지 않음
- 실제 team을 사용하는 시점에 쿼리를 날려서 각각 조회(N+1)
fetch join 또는 엔티티 그래프(EAGER, LAZY 상관 없음)
1. 멤버와 팀을 한번에 조회하기 위해 JPQL+fetch join 실행 select m from member m join fetch m.team
2. JPQL에서 fetch join을 사용했으므로 SQL은 멤버와 팀을 한 쿼리로 조회 -> select m., t. from member join team ...
3. JPQL 결과가 member와 team을 한꺼번에 조회함
4. member와 team이 fetch join으로 한번에 조회되었으므로 N+1 문제가 발생하지 않음
출처
5. 객체의 직렬화
참조형식데이터를 사용할 수 없기 때문에 데이터를 바이너리 또는 텍스트 형태로 통신이나 저장할때 파싱이 가능한 유의미한 데이터로 만들기 위해서 직렬화를한다.
6. 아직 계산식을 잘못쓴다.
나중에 볼때는 잘쓰고 있는가?
7. 스프링 시큐리티 설정 클래스 만들때
authorizeRequests() -> authorizeHttpRequests()로 대체됨
여기가서 어떤 내용으로 바뀌었는지 알수있음
8. URI와 URL
URL이 주소라면 URI는 주소를 포함하여 URL에서 보내오는 데이터를 식별한다.(패스워드, 아이디, 찾고싶은 게시글 번호 등)
9. 자바의 형변환
자바는 생각보다 형변환에 대해서 신경을 많이 써줘야한다.
int와 Integer가 다른것처럼 long과 int도 다르며 변환때 오류가 날수도있으니 한계점을 잘살피고 있어야한다.
