
1. 자료형 선언하기
C, 자바 같은 컴파일 언어는 변수를 사용하기 전에 반드시 자료형을 서언해야 한다. 변수의 자료형을 선언할 때는 변수 이름 앞에 자료형을 표기해야 한다. 변수에 자료형이 선언되면 메모리에는 변숫값을 저장할 수 있는 공간이 만들어진다.
Do it! 실습 | 변수 선언과 값을 대입하는 2가지 방법
package sec01_datatype.EX01_UsageOfDataType;
public class UsageOfDataType {
public static void main(String[] args) {
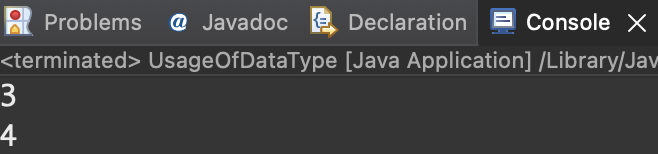
//변수 선언과 함께 값 대입
int a = 3;
//변수 선언과 값 대입 분리
int b;
b = 4;
System.out.println(a);
System.out.println(b);
}
}
- 변수의 선언과 동시에 값 대입
int a = 3처럼 변수의 선언과 함께 값을 대입하는 방법은 왼쪽의int a로 메모리에는a라는 공간이 생기고 오른쪽의a = 3으로 생성된 공간에는 값 3이 저장된다. - 변수 선언과 값 대입 분리하기
어떤 값을 저장할 수 있는 변수인지를 정하는 변수의 선언이 먼저 이뤄진 후 적절한 값을 대입한다. 2개의 수행 내용(선언 및 대입)을 명령 2개로 처리한다는 점에서 첫번째 방법과 차이가 있다. 메모리에 변수가 선언되고, 값이 대입되는 과정에서도 약간 차이점이 있다.
2. 이름 짓기
변수와 상수의 이름을 지을 때는 필수 사항과 권장 사항을 준수해야 한다. 필수 사항은 지키지 않으면 문법 오류가 발생해 컴파일 자체가 안된다. 반면 권장 사항은 개발자 끼리 혹은 협업하는 상황에서의 지켜야 할 약속 정도로 받아드리면 된다.
2-1. 이름을 지을 때 지켜야 하는 필수 사항
변수, 상수, 메서드의 이름을 지을 때 반드시 지키자.
- 영문 대소 문자와 한글 사용 가능
- 특수문자는 밑줄(_)과 달러($)표기만 사용 가능
- 아라비아 숫자는 첫 번째 글자로 사용 불가
- 자바에서 사용하는 예약어는 사용 불가(예약어는 외울 필요가 없으나 이 시리즈의 마지막을 작성하는 날에는 자연스럽게 알게 될 것이다.)
2-2. 이름을 지을 때 지키면 좋은 권장 사항
변수명을 지을 때 권장사항
- 영문 소문자로 시작한다.
- 영문 단어 2개 이상을 결합할 때는 새로운 단어의 첫 글자를 대문자로 시작(camel case)
상수명을 지을 때 권장사항
- 변수와 구분을 위해 모두 대문자로 표기
- 단어가 여러 개 결합하면 가독성이 떨어지므로 각각 밑줄(_)을 사용해 분리
메서드명 지을 때 권장사항
- 영문 소문자로 시작한다. (눈치 챘는가. 메서드명은 변수명을 지을 때와 권장사항이 같다.)
- 영문 단어 2개 이상을 결합할 때는 새로운 단어의 첫 글자를 대문자로 시작(camel case)
Do it! 실습 | 변수와 상수명 짓기
package sec01_datatype.EX02_NamingVariableAndConstant;
public class NamingVariableAndConstant {
public static void main(String[] args) {
// 변수
boolean aBcD; // 대문자는 새로운 단어의앞 글자에 사용 권장!
byte 가나다; // 한글로 작성 가능(권장하지 않음)
short _abcd;
char $ab_cd;
// int 3abc; // 숫자는 이름 맨 앞에 올 수 없음
long abc3;
//float int; // 자바 예약어는 사용 불가!
double main;
// int my space; // 스페이스, 특수 키는 사용 불가!
String myClassMate;
int ABC; // 전부 대문자는 권장하지 않음!
// 상수
final double PI;
final int MY_DATA;
final float myData; // 소문자 사용은 권장하지 않음!
}
}
2-3. 변수의 생존 기간
메모리에 변수가 만들어진 이후 사라지기까지의 시간을 의미한다. 자바에서는 개발자가 직접 변수를 생성한다. 하지만 메모리에서 변수를 삭제하는 작업은 자바 가상 머신(JVM)이 알아서 한다. 변수를 삭제하는 주체가 개발자가 아니다 보니 메모리에서 변수가 사라지는 시점을 이해하는 것은 매우 중요하다!
변수는 선언된 시점에서 생성되고 자신이 선언된 열린 중괄호({)의 짝궁인 닫힌 중괄호(})을 만나면 메모리에서 삭제된다.
변수의 생성과 소멸 시점의 예
{
int a; // 변수 a의 생성 시점
{
a = 3;
}
} // 변수 a의 소멸 시점🎱 변수의 생성 시점이 값을 대입한 시점이 아니라 선언한 시점이라는 점에 유의하자.
3. 자료형의 종류
자료형은 크게 기본 자료형과 참조 자료형으로 나눌 수 있다. 자바에는 8가지 기본 자료형이 있으며, 이외의 모든 자료형은 참조 자료형이다. 참조 자료형은 개발자가 직접 정의할 수 있어 가짓수는 무한개이다.
| 구분 | 저장값 | 자료형 |
|---|---|---|
| 기본 자료형 | 참, 거짓: true, false 정수: ..., -1, 0, 1, ... 실수: 38, 27, ... 문자(정수): 'a', 'b', ... | boolean byte, short, int, long float, double char |
| 참조 자료형 | 객체: Object | 배열, 클래스, 인터페이스 |
왜 자료형을 이렇게 구분해야 할까?
기본 자료형과 참조 자료형의 값 저장 방식이 서로 다르기 때문이다. 자료형의 구분을 이해하기 위해 먼저 메모리의 구조를 알아야 한다. 메모리는 목적에 따라 크게 3가지 영역으로 나뉜다.
첫 번째 영역은 클래스 영역, 정적 영역, 상수 영역, 메서드 영역 이라는 4개의 이름으로 불린다.
두 번째 영역은 스택 영역으로, 변수들이 저장되는 공간이다.
세 번째 영역은 힙 영역으로, 객체들이 저장되는 공간이다.
3-1. 기본 자료형과 참조 자료형의 차이
자료형의 이름 규칙
기본 자료형과 참조 자료형의 첫 번째 차이점은 자료형 자체의 이름 규칙에 있다. 자바에서 제공하는 기본 자료형 8개의 이름은 모두 소문자로 시작하는 반면, 참조 자료형의 이름은 모두 대문자로 시작!
실제 데이터값의 저장 위치
기본 자료형과 참조 자료형의 두 번째 차이점은 실제 데이터 값의 저장위치가 다르다는 것이다. 기본 자료형과 참조 자료형 모두 변수의 공간이 스택 메모리에 생성되지만, 그 공간에 저장되는 값의 의미가 서로 다르다. 기본 자료형은 스택 메모리에 생성된 공간에 실제 변숫값을 저장, 참조 자료형은 실제 데이터 값은 힙 메모리에 저장하고, 스택 메모리의 변수 공간에는 저장된 힙 메모리의 주소값을 저장
3-2. 기본 자료형의 메모리 크기와 저장할 수 있는 값의 범위
기본 자료형에는 참과 거짓을 저장하는 boolean, 정수를 저장하는byte, short, int, long, 실수를 저장하는 float, double 그리고 문자(정수)를 저장하는 char자료형이 있다.
우선 정수를 저장할 수 있는 자료형 4개를 살펴보면 순서대로 자료형의 크기가 크고, 클수록 저장하는 값의 범위도 넓어진다.
각 정수 자료형의 범위는 어떻게 결정될까? n개의 비트로 표현할 수 있는 정수는 2^n개이다. 예를 들어 2비트로 표현할 수 있는 정수는 2^2=4개(00,01,10,11)이다. 그렇다면 1 byte(=8 bit) 크기의 바이트 자료형으로 표현할 수 있는 정수는 2^8=256개 일 것이다. 정수는 음수, 0, 양수를 포함하므로 표현할 수 있는 전체 개수 중 반은 음수, 반은 0과 양수에 해당한다. 따라서 바이트 자료형의 값 범위는 -2^7 ~ 2^7-1이다.
실수의 float과 double 자료형은 각각 4 byte와 8 byte로 int, long 과 자료의 크기는 같지만 저장할 수 있는 값의 범위는 훨씬 넓다. 왜냐면 실수의 저장 방식이 부동 소수점 형태로 저장하기 때문이다.
3-3. 정수 자료형 - byte, short, int, long
정수 리터럴(코드에 직접 작성한 값)의 기준은 크게 2가지로 나뉜다. 첫 번째는 byte 와 short 자료형에 저장할 수 있는 범위 내의 정숫값이 입력됐을 때다. 이때 정수 리터럴은 각각의 자료형, 즉 byte 또는 short 자료형으로 인식한다. 또는 크기에 상관없이 int, long 에 정수 리터럴을 입력할 때도 int 자료형으로 인식한다. 다만 정수 리터럴 뒤에 long 을 나태는 l(L)을 붙여 표기하면 long 자료형으로 인식한다.
3-4. 실수 자료형 - float, double
float 자료형의 정밀도는 소수점 7자리, double 자료형의 정밀도는 소수점 15자리 정도이다.
자바는 실수 리터럴(코드에 직접 작성한 값)을 double 자료형으로 인식한다.단, float 을 나타내는 f(F) 을 실수 리터럴 뒤에 붙이면 float 자료형으로 인식한다.
Do it! 실습 | 불 대수, 정수, 실수 값의 저장 및 출력
package datatype;
public class PrimaryDatatype_1 {
public static void main(String[] args) {
// boolean: true/ false
boolean bool1 = true;
boolean bool2 = false;
System.out.println(bool1);
System.out.println(bool2);
System.out.println();
// 정수 (byte, short, int, long: 음의 정수/ 0/ 양의 정수
byte value1 = 10;
short value2 = -10;
int value3 = 100;
long value4 = -10L;
System.out.println(value1);
System.out.println(value2);
System.out.println(value3);
System.out.println(value4);
System.out.println();
// 실수 (float, double) : 음의 실수/ 0/ 양의 실수
float value5 = 1.2F;
double value6 = -1.5;
double value7 = 5;
System.out.println(value5);
System.out.println(value6);
System.out.println(value7);
}
}
3-5. 문자 자료형
char 는 문자를 저장하는 자료형으로, 문자를 작은 따옴표(')안에 표기한다. char 자료형은 정수를 저장할 수 있지만, 정수 자료형 4가지와는 다소 차이가 있다. 모든 문자를 특정 정숫값으로 바꿔 저장하는데 이때, 유니코드 표를 사용해 그 문자에 해당하는 정수로 바꿔 메모리에 저장한다. 이와 반대로 문자를 읽을 때는 정수를 읽어와서 그 정수에 해당하는 문자를 출력한다.
4. 기본 자료형 간의 타입 변환
boolean을 제외한 기본 자료형 7개는 자료형을 서로 변환할 수 있는데 이를 타입 변환(type casting) 이라고 한다. 자바는 항상 대입 연산자(=)를 중심으로 왼쪽과 오른쪽 자료형을 일치시켜야 하므로 타입 변환을 수행해야 할 때가 있다.
타입 변환 방법은변환 대상앞에자료형만 표기하면 된다!
정수나 실수 리터럴은 숫자 뒤에 L이나 F를 붙여 각각 long, float 타입으로 변환이 가능하다.- 반드시 알아야 할 점은 타입 변환을 수행할 때는 저장할 수 있는 값의 범위나 종류가 달라지므로 값이 변할 수 있다는 것!
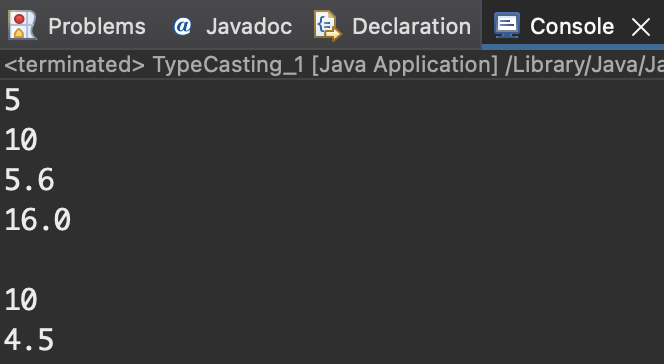
Do it! 실습 | 2가지 타입 변환 방법
package typecasting;
public class TypeCasting_1 {
public static void main(String[] args) {
// 캐스팅 방법 1: 자료형
int value1 = (int)5.3;
long value2 = (long)10;
float value3 = (float)5.6;
double value4 = (double)16;
System.out.println(value1);
System.out.println(value2);
System.out.println(value3);
System.out.println(value4);
System.out.println();
// 캐스팅 방법 2: L, F
long value5 = 10L;
float value6 = 4.5F;
System.out.println(value5);
System.out.println(value6);
}
}
4-1. 자동 타입 변환과 수동 타입 변환
타입 변환에는 컴파일러가 자동으로 수행하는 자동 타입 변환과 개발자가 직접 타입 변환을 수행해야 하는 수동 타입 변환이 있다.
먼저 크기(범위)가 작은 자료형을 큰 자료형에 대입할 때를 생각해보자. 이때는 어떠한 데이터의 손실도 발생하지 않는다! 따라서 작은 자료형을 큰 자료형에 담으면 개발자가 타입 변환 코드를 따로 작성하지 않아도 컴파일러가 알아서 자동으로 타입 변환을 실행하는데, 이를 업캐스팅이라고 한다.
업캐스팅이 아닌데, 자동 타입 변환이 적용되는 때가 있다! 사실 모든 정수 리터럴 값은
int자료형으로 인식된다. 그러나byte및short자료형에 저장할 수 있는 범위 내의 정수 리터럴 값이 대입될 때에는 자동 타입 변환이 각각의 자료형으로 수행된다. 앞서 살펴본 것처럼byte또는short자료형에 저장할 수 있는 리터럴 값이 입력될 때 해당 리터럴이 각각의 타입으로 인식되는 이유이다!
큰 자료형을 작은 자료형에 대입하는 행위를 다운캐스팅이라고 한다. 이때는 데이터 손실이 발생할 수 있으므로 컴파일러는 자동 타입 변환을 수행하지 않으며 개발자가 직접 명시적으로 타입 변환을 수행해야 한다.
자료형의 크기(바이트 크기 아님, 저장하는 값의 범위 기준)
byte < short / char < int < long < float < double
Do it! 실습 | 자동 타입 변환과 수동 타입 변환![]
package typecasting_2;
public class TypeCasting_2 {
public static void main(String[] args) {
// 자동 타입 변환
float value1 = 3; //int -> float(업 캐스팅)
long value2 = 5; //int -> long(업 캐스팅)
double value3 = 7; //int -> double(업 캐스팅)
byte value4 = 9; //int -> byte
short value5 = 11; //int -> short
System.out.println(value1);
System.out.println(value2);
System.out.println(value3);
System.out.println(value4);
System.out.println(value5);
System.out.println();
// 수동 타입 변환
byte value6 = (byte)128; //int -> byte(다운캐스팅)
int value7 = (int)3.5; //double -> int(다운캐스팅)
float value8 = (float)7.5; //float -> float(다운캐스팅)
System.out.println(value6);
System.out.println(value7);
System.out.println(value8);
}
}
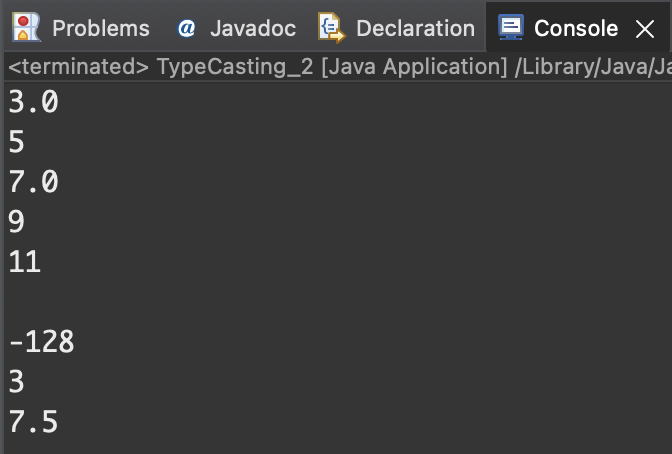
🎱 value 6 의 값으로 -128이 출력된 이유?
정수의 자료형을 작은 범위의 자료형으로 캐스팅할 때는 범위의 반대쪽 끝에서부터 다시 시작하는 circular 의 구조를 보인다. 즉, 정숫값 128(127+1)을 byte 자료형으로 다운캐스팅하면 byte 자료형의 범위에서 반대쪽 끝인 정숫값 -128로 변환된다.
📕 참고문헌) Do it! 자바 완전 정복!
