데이터베이스에 저장된 데이터는 결함이 없어야 하기에 일관성을 유지하고 중복을 제거하는 등 데이터 신뢰도를 유지해야 한다. 이때문에 데이터의 삽입, 삭제, 수정 시 여러가지 제약조건이 있는 것이다. 관계 데이터베이스에서 가장 중요한 개념인 키에 대해 싹 정리해보았다.
키

SHINee 만능열쇠 key
가 아닌

자동차, 집을 잠그고 여는 데 사용하는 열쇠를 데이터베이스에서도 사용한다!
그러면 생각해보자. 자동차와 집 열쇠가 너도나도 가지고 있으면 그게 열쇠의 역할을 하는가?
아니다. 키는 무엇인가를 유일하게 식별한다는 의미가 있는 것이다!
실생활에서의 key처럼 데이터베이스에서 키는 특정 튜플을 식별할 때 사용되는 속성 혹은 속성의 집합이다.
튜플이란?
릴레이션 스키마에 실제로 저장된 데이터의 집합
릴레이션이란?
행과 열로 구성된 테이블을 말한다.
relation이란 사전적으로 '관계', '친척'을 말하는데 영어 relation은 우리말로 '관계'라고 해야 하지만 뒤에 나올 용어 relationship을 '관계'라고 하기 때문에 번역의 충돌을 피하기 위해 '릴레이션' 그대로 부른다.
그러나 다른 용어에 포함된 relation은 그대로 '관계'로 번역해 relational data model, relational database 등은 '관계 데이터 모델', '관계 데이터베이스'라고 한다.
키는 릴레이션 간의 관계를 맺는 데도 사용된다.
아래 사진을 보자.
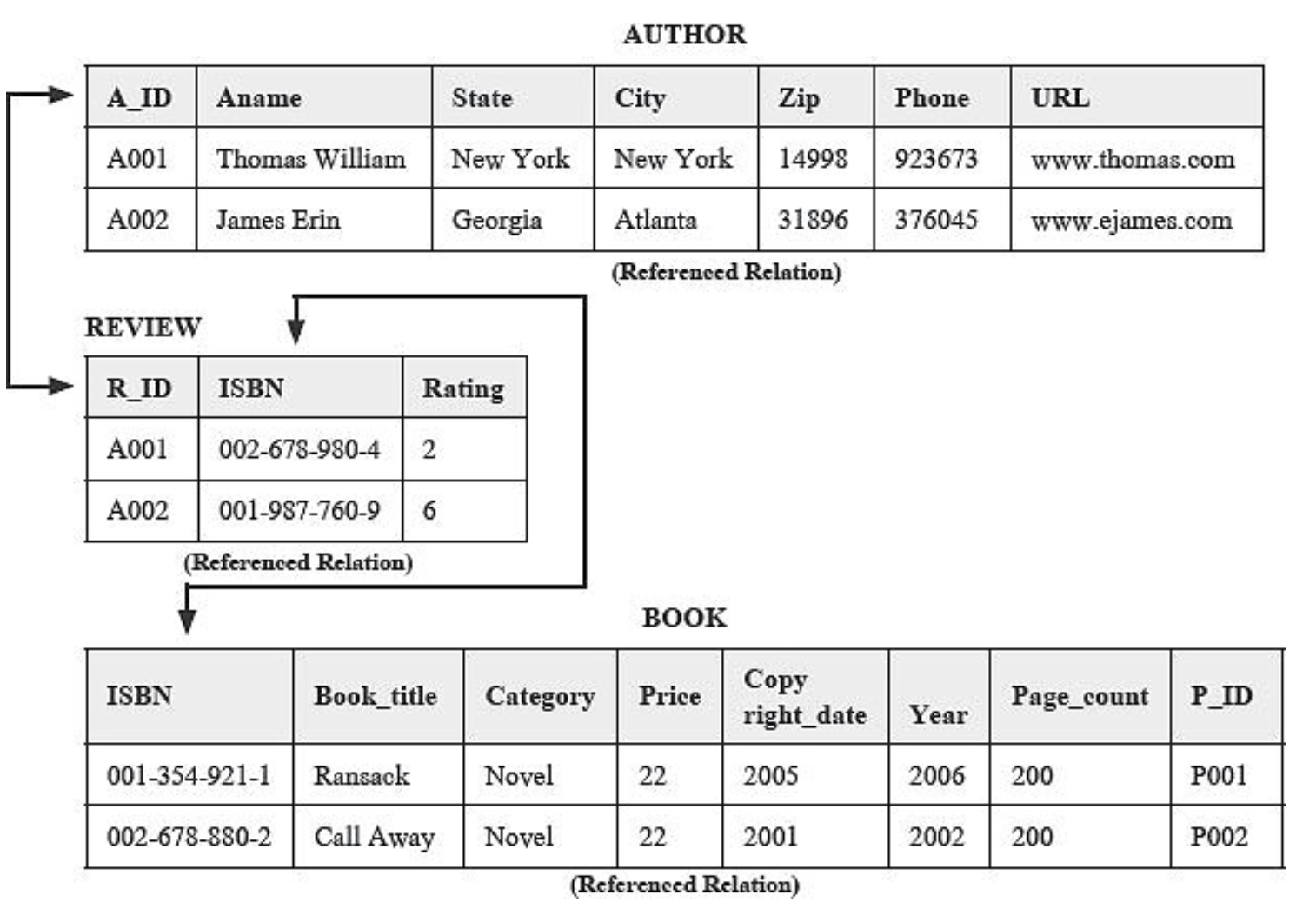
AUTHER 테이블, REVIEW 테이블, BOOK 테이블이 있다.
REVIEW 테이블의 ISBN은 BOOK 테이블의 ISBN에 쓰인다.
REVIEW 테이블의 R_ID은 AUTHOR 테이블의 A_ID에서 가져온 것이다. 이처럼 각 테이블마다 관계를 맺고 있는 것을 확인할 수 있는데, 리뷰 릴레이션의 ISBN은 리뷰 릴레이션의 키이면서 북 릴레이션에 저장되어 어떤 도서 번호인지 알 수 있도록 관계를 맺고 있다.
저자 릴레이션과 리뷰 릴레이션의 저자 아이디 역시 같은 역할을 하는 것이다!
슈퍼키
슈퍼키(super key)는 튜플을 유일하게 식별할 수 있는 하나의 속성 혹은 속성의 집합을 말한다.
author 릴레이션에서 속성별로 튜플 식별이 가능한지 살펴보자.
- A_ID: 저자 별로 유일한 값 부여 => 튜플 식별 o
- Aname : 저자의 이름으로 동명이인이 있을 경우 => 튜플 식별 x
- State : 저자의 주소지 => 튜플 식별 x
- Phone : 한 사람이 여러개의 핸드폰 사용 가능 & 사용하지 않는 사람이 있을 경우 => 튜플 식별 x
- URL : 자신의 이름으로 된 웹페이지, 도메인 주소는 유일 => 튜플 식별 o
튜플을 유일하게 식별할 수 있으면 모두 슈퍼키가 될 수 있다.
따라서 저자 릴레이션의 경우 저자 번호(A_ID)와 URL을 포함한 모든 속성의 집합이 슈퍼키가 된다.
따라서 슈퍼키는 포함하지 않아도 되는 속성을 포함할 수 있다.
(저자번호), (저자번호, 이름), (저자번호, 이름, 주소), (저자번호, 이름, 핸드폰), (URL), (URL, 이름, 주소), ...
그러나 우리는 튜플을 식별할 수 있는 최소한의 속성 집합이 필요하다!
키를 구성하는 속성이 많으면 많을 수록 복잡하기 때문이다.
후보키
후보키(cardidate key)는 튜플을 유일하게 식별할 수 있는 속성의 최소 집합이다. 이는 효율성 측면에서 매우 중요하다.
저자 릴레이션의 경우 슈퍼키는 많지만 후보키는 '저자번호', 'URL' 만 될 수 있다. 예를 들어, (저자번호, 이름)은 슈퍼키이지만 후보키는 아니다! 없어도 되는 속성인 '이름'이 포함되어 있기 때문이다.
도서 릴레이션을 보자.
도서 릴레이션은 저자가 도서를 냈을때 생성되는데, 한 명의 저자가 여러 권의 도서를 낼 수 있으며, 여러 명의 도서는 한 명의 저자 또는 여러명의 저자를 가질 수 있다.
도서 릴레이션의 후보키는 ISBN와 P_ID라는 두개의 속성을 합한 (도서번호, P_ID)가 된다.
참고로 이렇게 두개 이상의 속성으로 이뤄진 키를 복합키라고 한다.
기본키
기본키(primary key)는 여러 후보키 중 하나를 선정해 대표로 삼는 키.
후보키가 하나뿐이라면 그 후보키를 기본키로 사용하면 되고 여러 개라면 릴레이션의 특성을 반영해 하나 선택하면 됨.
기본키는 릴레이션을 대표하므로 여러 사항을 고려해야 한다.
예를 들어 저자 릴레이션의 경우 '저자번호', 'URL'을 기본키로 선택할 수 있다. 먼저 URL을 보면, 저자에게 각각 주어지며 변경이 불가능하다. 변경이 불가능하면 튜플 식별 시 자료변형에 잘 대처할 수 있는 여지를 제공.
그러나 URL은 속성의 값이 다른 데이터에 비해 큰 편이라 데이터 계산 속도에 영향을 줄 수 있다.
따라서 기본키로 저자번호를 선택하는 것이 좋다.
