빅데이터를 처리하기 위한 nosql
옛날부터 있었던 정보들..데이터들..
빅데이터를 하면 좋은점?
마케팅 활용 => 수익 창출 가능
빅데이터 => 구글, 페이스북, 아마존에서 처음 만듦
고객들의 특성을 파악할 필요성 느낌
저장공간 용량 증가 => 소프트웨어 개발 => 하둡, nosql 등 기술 발생
딕셔너리, 리스트로 저장 => nosql
데이터베이스 in computer(머신)
server 머신 => 좋은 cpu, 많은 디스크들
서비스 대상이 만명 => 10만명으로 증가 => cpu, 디스크를 증가해야 => scale up!
저장, 처리 나눠서 하자 => 분산 저장 => 하둡
저장, 처리는 어떤 방식? => map/reduce 방식으로 하자~
10가지 일 => 10개의 map으로 나눔
10개의 서버에서 분산되게 작업 > 후 merge 하겠음
NoSQL
- 대량의 데이터(사진, 음성, 영상 등)을 어떻게 capture하고 저장할 수 있을까?
- 빅데이터를 어떻게 효율적으로 처리?
- 이것을 어떻게 저비용(low cost)로 달성?
Which to Choose?
- Hadoop
- Spark
- NoSQL
기업의 경쟁력의 변환
자본, 자원이 많은 회사들이 개발을 잘 했음(Oil)
그러나 지금은 데이터가 많은 회사가 잘 나감(Data, Service)
Requirements for Big Data
기술의 발전을 통해서 저장 비용 감소, 클라우드 기술 대중화
-
확장형 구조를 지원
RDB는 확장하는데 어려움이 있었음Scale up => Scale out
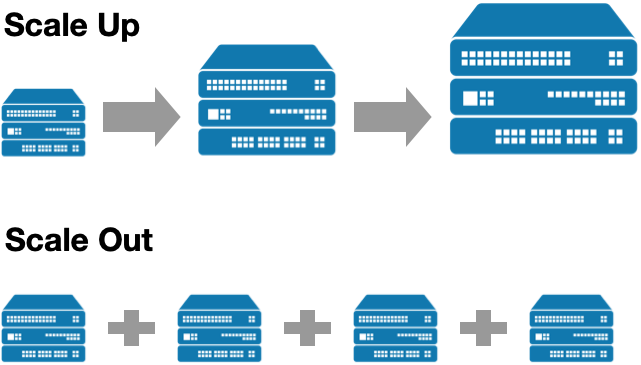
-
결함 허용 시스템
rdb에서는 트랜잭션의 원자성(all or nothing), 데이터 무결성 등의 결함 불허 -
다양한 데이터 구조 처리
open-source data framework
distributed storage and distributed processing
Core Hadoop
하둡 파일 시스템
하둡은 구글이 2000년대 초반에 수행한 작업을 기반
2003년 발표한 Google File System, MapReduce 기반
데이터가 시스템에 처음 저장될 때 노드에 데이터를 분배
구글 데이터 센터 => 우리나라, 미국, 샌프란시스코..
똑같은 유튜브 영상 => 한국 서버에 먼저 있는지 보고 미국 확인
똑같은 데이터가 여러 군데 저장됨
단점 : 용량 많이 소비(RDMS: 중복성 제거 => 정규화)
장점 : 가용성 높임(실시간 데이터 처리 속도 FAST)
공유 파일 시스템(HDFS) 사용
- 페타 바이트(테라 바이트 이상) 규모로 데이터 처리
- 단일 장애(SPOF) 없는 고 가용성 지원
효율적이고 확장 가능한 처리 시스템인(YARN/MR)
많은 서버에 효율적으로 처리 부하를 분산
비교적 간단한 프로그래밍 지원
가용성, 일관성, 확장성을 모두 만족하는 서비스는 안타깝게도 없음
RDMS: 확장성 포기
NoSQL, 빅데이터시스템: 일관성 포기
핵심 하둡에 기능을 추가하는 오픈 소스 프로젝트 들
Sqoop&Flume&Kafka
외부 시스템에서 데이터를 수집하는 도구
RDBMS에 보관되거나 즉시 생성되는 데이터를 Hadoop에 저장
Hive and Impala
SQL과 유사한 언어로 빅데이터 처리
프로그래머가 아니여도 데이터 분석 가능
Spark
MapReduce의 대안
더 빠르고 사용하기 쉬우며 스트리밍 데이터 처리
Spark Framework
spark이 제공하는 sql, streaming, milib, graphX 등의 라이브러리들을 java, scala, python 등의 언어를 사용해 분산 처리 어플리케이션을 생성
NoSQL
가용성, 확장성이 뛰어난 데이터베이스
하둡은 배치처리, 큰 양 처리, 컴퓨팅 능력
nosql => 실시간 처리, 응답속도 빠르게(user transaction, sensor data 등)
중복되는 코드가 많아 이를 라이브러리화
라이브러리가 자체 api를 보유한 db
데이터 정규화(data normalization)
- 큰 테이블을 작은 테이블로 분리
- key cloumn 관계를 기반으로 연결
- 데이터 중복 감소
- 이상현상 처리
ACID
- Atomicity
all or nothing
은행 송금 시 한 쪽이 끊기면 다 끊기어야!
- Consistency
일관성 유지 - Isolation
매 작업이 각각 간섭 x - Durablity
한번 실행된 결과는 영원히 보장
=> 이는 nosql에서는 base임
구글의 새로운 시도
Google File System => Hadoop File System(HDFS)
Google Map Reduce programming paraadigm
Google Big Table
SQL 기반 RDBMS는 더 이상 새로운 패러다임에 부적합
NoSQL은 데이터 크기와 엄청난 질의 증가를 처리 증가
파티션 허용 => 가용성/일관성 포기
- 저비용저장
- 분산정렬처리
- 클라우드 기술
NoSQL
- 간편한 복제 및 간단한 API 지원(SQL 시스템을 몰라도 OK)
- A Non-Relational database(No table)
- 빅데이터 및 실시간 시스템에 적합
- 다양한 형태의 NoSQL DATABASE
HBASE, Cassandra, MongoDB
단점
- 표준화 지원 및 완성도 부족
- 종류별로 다른 관리 방식에 대한 부담
- 중복에 의한 큰 데이터 증가
- 분석 및 BI 도구 부족
SQL 기반 RDMS랑 Nosql랑 완전 반대는 아니다
- NoSQL(정형화+비정형화(JSON)+비정형화 가능(음성, 센서데이터 등), 목적에 따라 선택
NoSQL 개념 3가지- 다양한 저장 모델(Key-Value)
- 분산 처리 가능
Scale up => out
다음시간 q/a 받고 비대면 수업
