알고리즘 문제를 풀다보면 매개변수를 받아와서, 함수 내부의 다양한 조작을 받아 리턴값을 만드는 경우가 많다. 필요에 의해 매개변수를 이리저리 조작하다보면 특정 단계의 조작이 다른 특정 단계의 조작에 영향을 미치는 경우가 있다.
가령 유저의 ID를 "new_id"라는 매개변수로 받아 여러 단계의 조작을 한다고 가정해보자.
4단계 new_id가 빈 문자열이라면, new_id에 "a"를 대입합니다.
5단계 new_id에서 마침표(.)가 처음이나 끝에 위치한다면 제거합니다.
만약 "new_id"로 ".."이라는 문자 데이터가 입력됐다면, 4단계는 new_id가 빈 문자열이 아니기 때문에 통과하게 된다. 그러나 5단계를 거치면 조작된 new_id는 빈 문자열이기 때문에 다시 4단계를 거쳐서 적합성을 검증받아야 한다. 하지만 JS는 위에서부터 차례대로 읽어내려오기 때문에 4단계 부분의 함수를 다시 복붙으로 5단계 아래에 실행시키지 않으면 다시 검증할 방법이 없다. 또한 특정 단계를 몇번 반복하면 적합성이 검증될지 모르는 경우도 많기 때문에 무작정 복붙을 많이 할 수도 없을 노릇이다.
따라서 내가 하고 싶은 작업은
각각의 단계를 계속적으로 거쳐 적합할 때까지 함수를 반복하는 것이다.
이럴 때 사용하는 것이 재귀함수이다. 이럴 때 함수를 멈추는 시점이 되는 '적합할 때'를 상정하는 것이 어려웠는데 결론적으로 이야기하자면
함수의 매개변수로 들어오는 input값과 함수의 끝인 return 이하의 값이 일치
하면 함수는 return값을 배출하고 완료되면 된다.
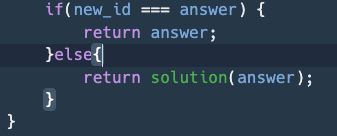
상기의 사진에서 new_id는 매개변수고, answer가 return될 값이다. 둘이 같으면 answer를 리턴하고 함수를 마무리 짓고,
그렇지 않으면 함수의 결론이 '새로운 매개변수로 함수를 재실행'인 것으로 마무리 지으면 된다.
이 과정에서 return solution(answer)이 아니라, 그냥 solution(answer)이면 왜 안 되는지 좀 고민에 빠졌었다. input값과 return값이 같지 않으면 'solution(새로운 매개변수)라는 함수를 실행'. 이라고 표현하니까 언뜻 맞는 것 같이 느껴졌다. 하지만 그러한 표현은 함수를 끝까지 종결짓지 않고, 콜 스택에 무수한 함수들을 계속 추가하는 행위에 지나지 않는다는 것을 깨달았다.
따라서 재귀함수를 실행할 때에도 함수는 return값에 '새로운 재귀함수 실행'이라는 결과를 배치 시켜야 한다.
