데이터셋 관련
필요한 데이터를 확보하여 활용하는 것은 저희 프로젝트에서 가장 중요한 부분 중 하나였습니다.
대부분의 자료는 도서관 정보나루에서 다운받고 가공해서 사용하였습니다.
데이터 수집 및 가공 과정
500만건의 데이터를 수집하였으나 같은 이름의 중복 데이터, Null이 들어가있는 필요없는 데이터가 존재하는 것을 확인하였습니다. 중복데이터를 제거하는 데이터 클렌징과 Null값으로 들어가 필요없는 데이터를 제거하는 데이터 정제 과정을 거친 후 검증하는 과정을 담았습니다.
💡 현재 가지고 있는 books는 500만 건이라고는 하지만, 중복된 데이터는 어느 정도이며, 사용자가 정말 필요로 하는( 인기 도서, 베스트 셀러) 도서를 담고 있을 정도로 실용성이 있는가?-
Select * from books;
count 5,000,266 -
isbn 기준으로 중복된 데이터가 얼마나 있는 지 확인
select sum(c-1) from (select ISBN_THIRTEEN_NO, count(*) as c from books group by ISBN_THIRTEEN_NO having count(*) > 1) as subquery;sum(c) 결과 1,346,822 500만건 중 26%가 중복 데이터
- 500만건 중에 130만건의 중복 데이터가 있다. 이것을 해결 해야 한다.
-
서울 전 지역, 성남 전 지역 도서관이 소장하는 도서를 얼마나 커버 할 수 있는가?
lib_has 테이블엔 isbn 기준 몇건의 도서가 있는가?
select distinct count(*) from (select ISBN from lib_hasbook group by ISBN) as subquery;sum(c) 1,413,338 books 테이블은 과연 lib_hasbook 테이블에 있는 도서를 얼마나 포함 하는가?
select distinct count(*) from (select ISBN as i from books b, lib_hasbook l where b.ISBN_THIRTEEN_NO = l.ISBN group by ISBN) as subquery;sum(c) 전체 141만건 결론 1,267,151 89.6% 서울,성남 지역 도서관 도서를 89.6% 확률로 검색 할 수 있다. 서울 지역 5년 간 인기 대출 1만건 데이터를 books는 얼마나 담고 있는가?
select count(*) from (select distinct b.ISBN_THIRTEEN_NO as books_isbn, f.ISBN as favoriteBook from books b LEFT OUTER JOIN favoritebook f on b.ISBN_THIRTEEN_NO = f.ISBN where f.ISBN is not null) as subquery;9585count(*) 전체 1만건 결론 9586 95.8% 사용자가 많이 찾을 도서 데이터를 95.8% 확률로 찾을 수 있다. 어떤 도서를 놓치고 있는가?
select distinct f.ISBN as favoriteBook, b.ISBN_THIRTEEN_NO as books_isbn, f.title_nm, f.loan_count,f.publish_data from favoritebook f LEFT OUTER JOIN books b on b.ISBN_THIRTEEN_NO = f.ISBN where b.ISBN_THIRTEEN_NO is nullbooks에서 isbn을 중복해서 가진 데이터의 형태를 분석, 제거
중복된 이유는 신판 출판으로 인한 중복으로 판단됨
select * from books where ISBN_THIRTEEN_NO in (select ISBN_THIRTEEN_NO from books group by ISBN_THIRTEEN_NO havingcount(*) > 1); select * from books where ISBN_THIRTEEN_NO=9788972201120;
delete from books where kdc_nm is null로 제거하는 경우
아래와 같이 중복이 아닌 데이터도 지워질 가능성이 높다고 판단.

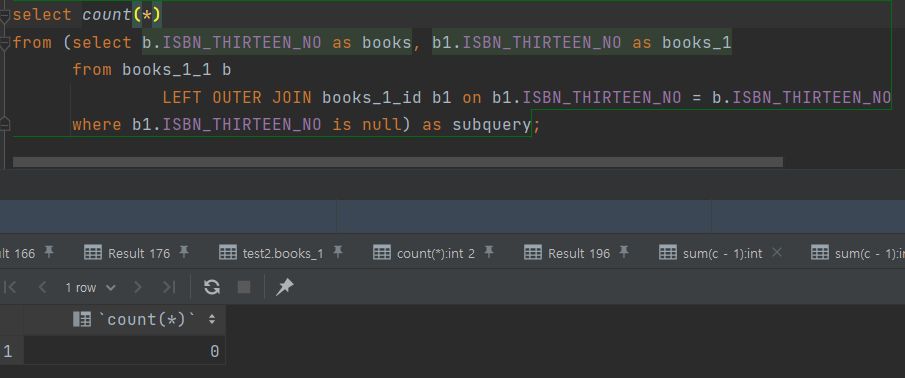
select * from books where ISBN_THIRTEEN_NO=9788988800959;CREATE TEMPORARY TABLE temp_books_to_delete SELECT ISBN_THIRTEEN_NO FROM books GROUP BY ISBN_THIRTEEN_NO HAVINGCOUNT(*) > 1;# 이건 왜 지원되지 않는가?? delete from books where ISBN_THIRTEEN_NO in (select ISBN_THIRTEEN_NO from books group by ISBN_THIRTEEN_NO havingcount(*) > 1) and KDC_NM is null;
중복 제거
delete from books b where b.ISBN_THIRTEEN_NO in (select ISBN_THIRTEEN_NO from temp_books_to_delete) and b.KDC_NM is null and TWO_PBLICTE_DE is null and TITLE_SBST_NM is null;count(*) 목표 값 달성률 3,853,047 5,000,266 →3,653,444 95% 데이터 검증
- 제대로 중복 제거 되었는가?
- 불필요하게 지워진 데이터는 없는가?
select count(*) from (select b1.ISBN_THIRTEEN_NO, b1.TITLE_NM, b.ISBN_THIRTEEN_NO as isbn, b.TITLE_NM as title from books_1 b1 left outer join books b on b.ISBN_THIRTEEN_NO = b1.ISBN_THIRTEEN_NO where b.ISBN_THIRTEEN_NO is null) as subquery;count(*) 8 중복 제거한 데이터가 원본과 비교 했을 때 8건 데이터가 손실 5%의 중복은 왜 제거되지 못 했는가?
- 그전의 중복 데이터와는 다르게 완전히 일치하는 중복 데이터. → 그래도 두개의 데이터에서 차이나는 칼럼이 하나 있었다. Authr_SBST_NM
중복된 칼럼 중에 auth_sbst_nm이 빈 문자열인 경우를 삭제하는 방법이 있음
select * from books b, temp_books_to_delete t where b.ISBN_THIRTEEN_NO = t.ISBN_THIRTEEN_NO and b.AUTHR_SBST_NM = '';→ 하지만 만약에 둘다 빈 문자열을 가진다면 확인하는 절차가 필요하다고 판단.
select sum(c-1) from (select b.ISBN_THIRTEEN_NO,count(*) c from books b, temp_books_to_delete t where b.ISBN_THIRTEEN_NO = t.ISBN_THIRTEEN_NO and b.AUTHR_SBST_NM = '' group by b.ISBN_THIRTEEN_NO having count(*) > 1) as subquery;확인 결과
count(*) 6159 6159 건의 데이터가 유실 될 수 있다. → 데이터가 유실될 가능성이 높으므로 좋은 방법이 아니라고 판단.
남은 중복 데이터를 확인 → 한자로 구성된 도서 데이터.
- 한자 도서 데이터를 모두 삭제 할 것인가?
- 인위키를 만들어서 인위키가 더 큰 것을 삭제 할 것인가?
- 다른 조건을 판단하여 삭제 할 것인가?
delete b1 from books_1 b1 join temp_books_1_to_delete t on b1.ISBN_THIRTEEN_NO = t.ISBN_THIRTEEN_NO where (length(b1.AUTHR_SBST_NM) <length(t.AUTHR_SBST_NM));삭제 후 불필요한 데이터가 삭제되지 않았나?
select distinctcount(*) from (select b.ISBN_THIRTEEN_NO as books, b1.ISBN_THIRTEEN_NO as books_1 from books b LEFT OUTER JOIN books_1 b1 on b1.ISBN_THIRTEEN_NO = b.ISBN_THIRTEEN_NO where b1.ISBN_THIRTEEN_NO is null) as subquery;count(*) 유실 정도 결론 13595 3,853,047 → 3737570 ( -3%) 2차 중복 제거 과정에서 13595건의 데이터가 유실 됐다. 그럼 중복이 완전히 제거 됐는가?
select sum(c - 1) from (select ISBN_THIRTEEN_NO,count(*) as c from books_1 group by ISBN_THIRTEEN_NO having count(*) > 1) as subquery;count(*) 중복 제거 결론 97,259 199,603 → 97,259 (48%) 불완전한 조건에 의해 시행된 중복 제거 2번 방법으로 돌아와서, auto_increment를 통한 pk를 만들고, 중복된 데이터 중 pk가 더 큰 데이터를 삭제
| 전체 데이터 수 | 중복 데이터 | 손실 데이터 |
|---|---|---|
| 3,640,311 | 0 | 0 |
중복 데이터 확인 1
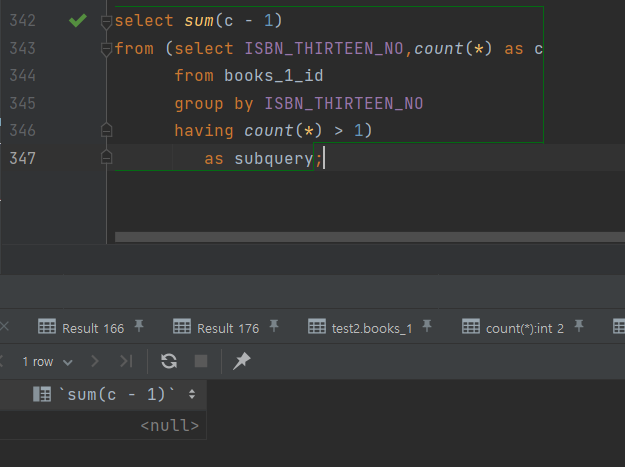
중복 데이터 확인 2
손실 데이터 확인