https://velog.io/@alpahexia/MapBook-%ED%8C%8C%EC%9D%BC-%EB%8B%A4%EC%9A%B4%EB%A1%9C%EB%93%9C-%EC%9E%90%EB%8F%99%ED%99%94
위 링크는 기존에 존재하던 대출 횟수 합산을 위한 전국 도서관 장서 목록 File을 다운로드 자동화하는 과정에 대한 글이다.
왜 필요 했나?
-
매달 1억 2천만 건의 데이터를 통해 대출 횟수 최신화, 새롭게 업데이트 되야하는 도서 상세 데이터, 구조화된 로그 데이터에 대한 후처리 등 주기적으로 이뤄져야 하지만 대단히 번거로운 작업들이 있다. 이 작업을 수작업으로 하는 게 너무 비효율적이라고 생각이 들었다.
-
코드의 복잡성 증가.
- Java의 I/O 기술을 활용해서 코드들을 짜면서 각 작업마다 I/O 관련 코드들의 중복되는 코드들 문제
- 방치되는 서비스로 되지 않기 위해
- MapBook 서비스의 특징 중 하나가 대출 횟수를 기반으로 도서관 도서를 보다 더 알맞게 검색할 수 있으며, 도서관 도서를 통합으로 검색이 가능하다. 사용자들은 최신의 데이터를 원할 것이며 그것을 제공하지 못한다면 사용자 경험을 헤칠 것이다.
배치 프로세스
- 도서관 장서 목록 File 다운로드 -> 정제 -> 분할하고 대출 횟수를 집계 -> 병합 -> 최종적으로 Book Table의 Loan_cnt 칼럼에 Update -> Update 되지 않는 Data는 Required Update Book Table에 Insert (이후 Update Book Batch가 맡음)
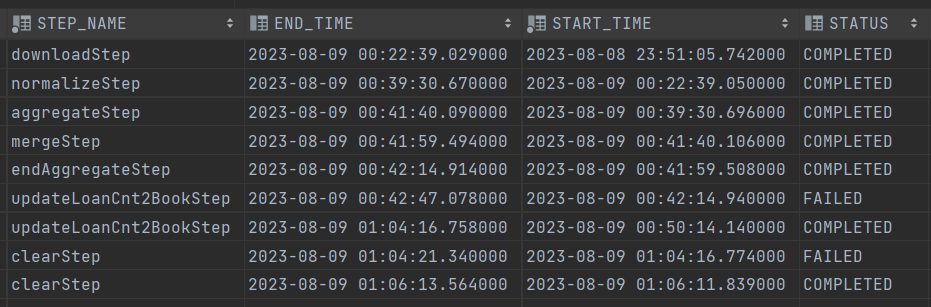
아래는 해당 프로세스를 통합 테스트를 했을 때의 Batch_Step_exuecution 테이블의 모습니다.
두개의 Fail이 있는데, 첫번째는 Required Update Book Table에서 Not_found라는 칼럼은 boolean 타입인데, 이때 default 값이 falut로 설정되고 nullable이였어야 했는데 설정이 잘못돼서 실패
두번째 실패는 모든 작업이 완료 후, 작업을 필요한 File들을 삭제하는 작업에서 File 하나를 열어놓은 상태였어서 시스템 에러.
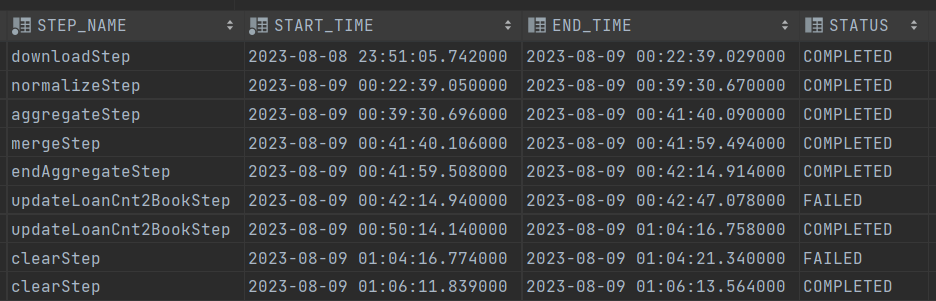
총 소요시간은 1시간 15분 가량 걸렸다.
- downloadStep - 30 min (전국 도서관 장서 목록 데이터 1460개 Csv File Download)
- normalizeStep - 17 min (ISBN과 대출 횟수만 남기고 다른 Data 제거, Csv File 또는 ISBN 양식에 맞지 않는 데이터 정제)
- aggregateStep - 2 min (File을 일정 단위로 그룹화해서 ISBN별로 대출 횟수를 합산, HashMap 사용)
- mergeStep - 11s (나뉘어진 File들을 하나로 합침)
- endAggregateStep - 13s (합쳐진 File들을 최종적으로 다시 ISBN별로 대출 횟수 합산)
- updateStep - 22 min ( 내부 DB에 연결하여 Book Table의 Loan_Cnt 칼럼에 대출 횟수 업데이터. Book Table에 존재하지 않는 ISBN은 따로 Required_Update Table에 Insert)
- clearStep - 3s (관련 Directory의 File들 모두 삭제)
역시나 DownLoad 단계에서 가장 많은 시간이 소요가 됐다.
현재 병렬 스트림을 사용함으로써 시간을 단축시키긴 했지만 보다 나은 방법을 찾아봐야 한다.
두번째로 오래 걸린 Step은 DB에 입력하는 단계로 UpdateStep이다.
병렬 Step을 통해 Chunk Size를 10만을 기준으로 작업하고 있지만, 이 Chunck Size를 조절해서 최적의 Size를 찾아봐야겠다.
아래는 DownLoad Step에서 Java의 병렬 스트림을 사용하지 않았을 때와 했을 때의 소요 시간 차이를 보여 준다.
- 단일 스트림 사용

- 병렬 스트림 사용

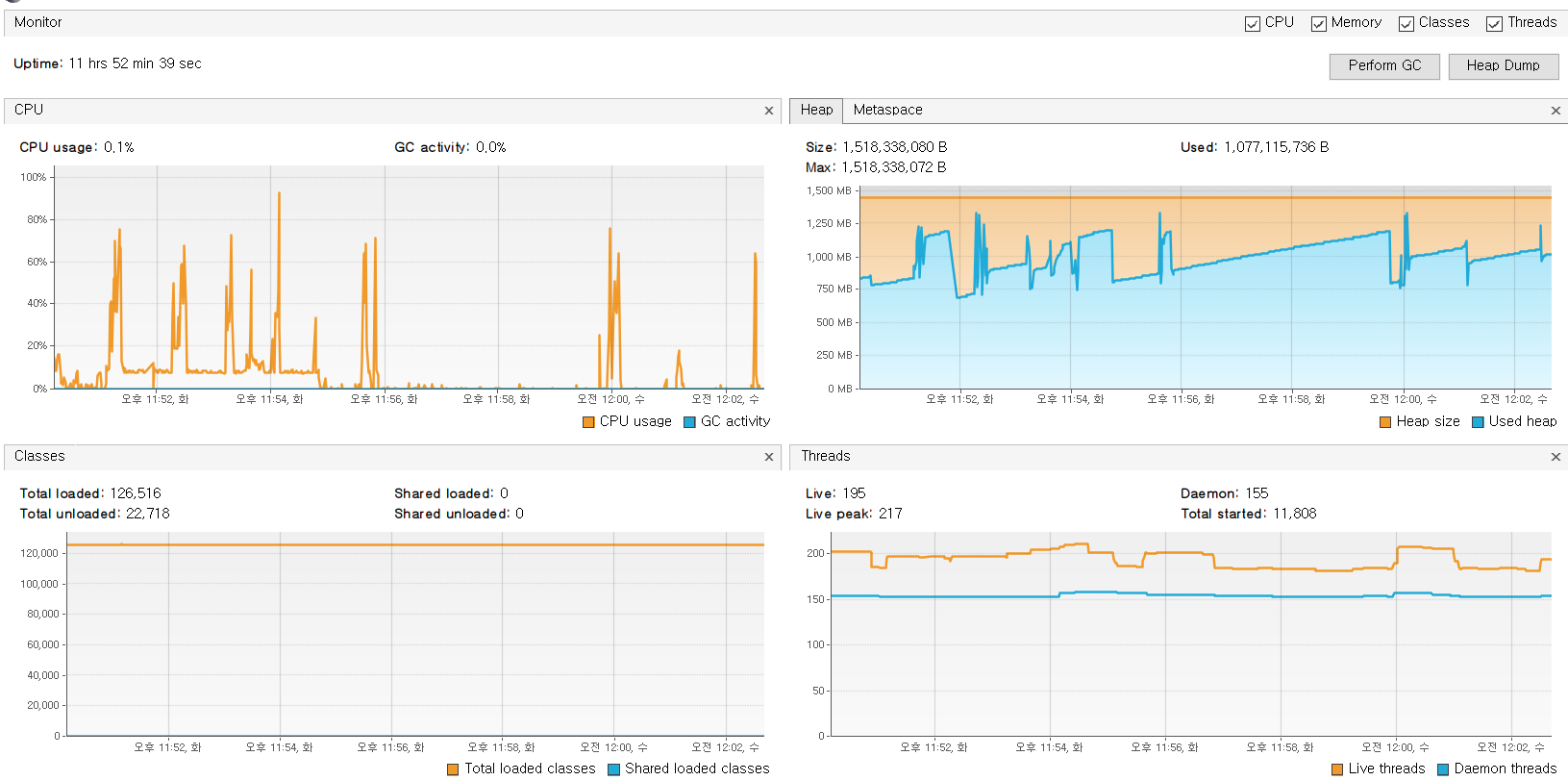
Visual VM을 통해 해당 Batch Process 상태 확인하기
- Batch Server가 올라갔을 때, 행여나 하드웨어 상의 문제가 발생할까 Local에서 Batch 통합 테스트를 시행할 때 Visual VM을 통해 상태를 확인 했다.
로컬 노트북의 사양은 아래와 같다. SSD 231GB이다.

- downLoad Step
-
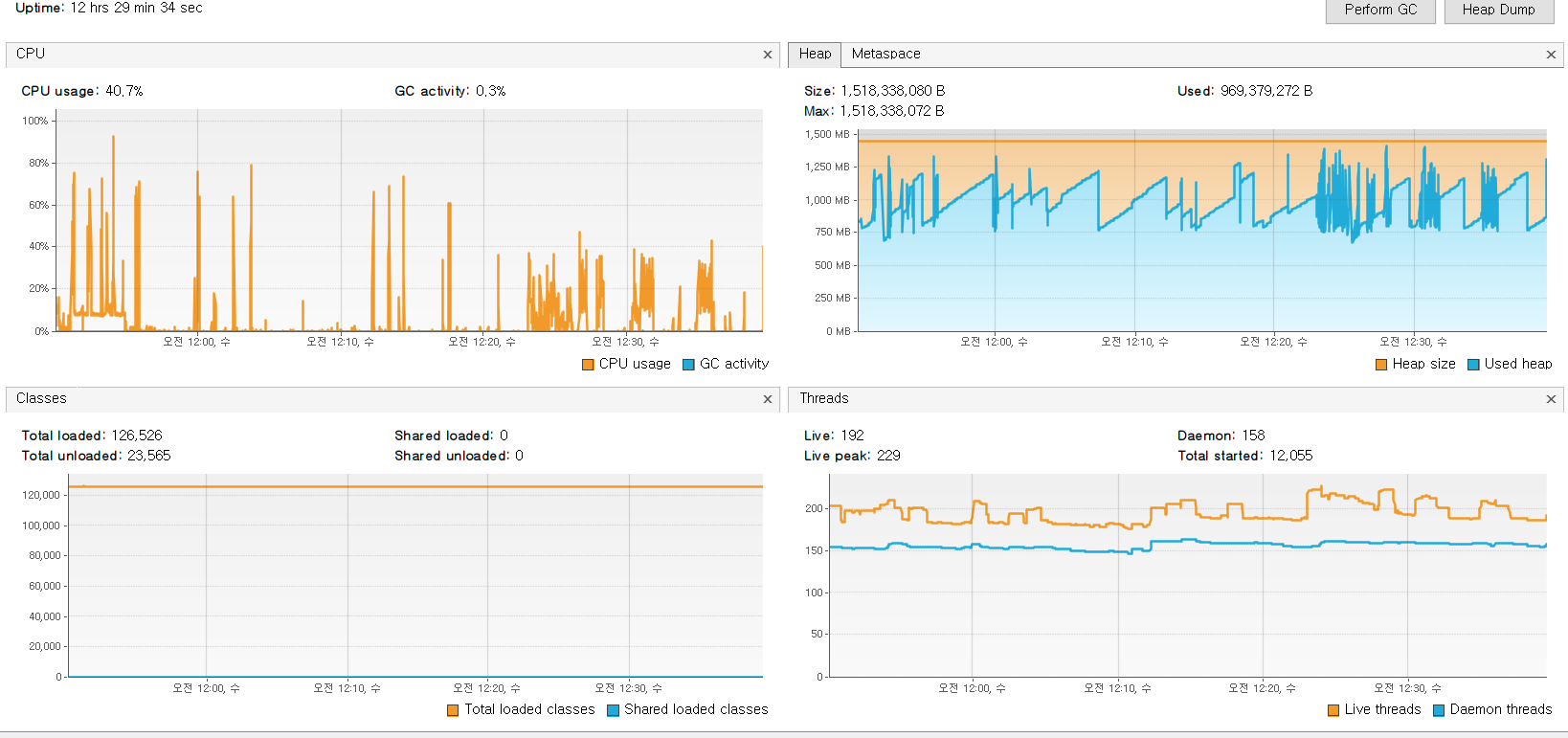
Aggregating Step
-
UpdateStep
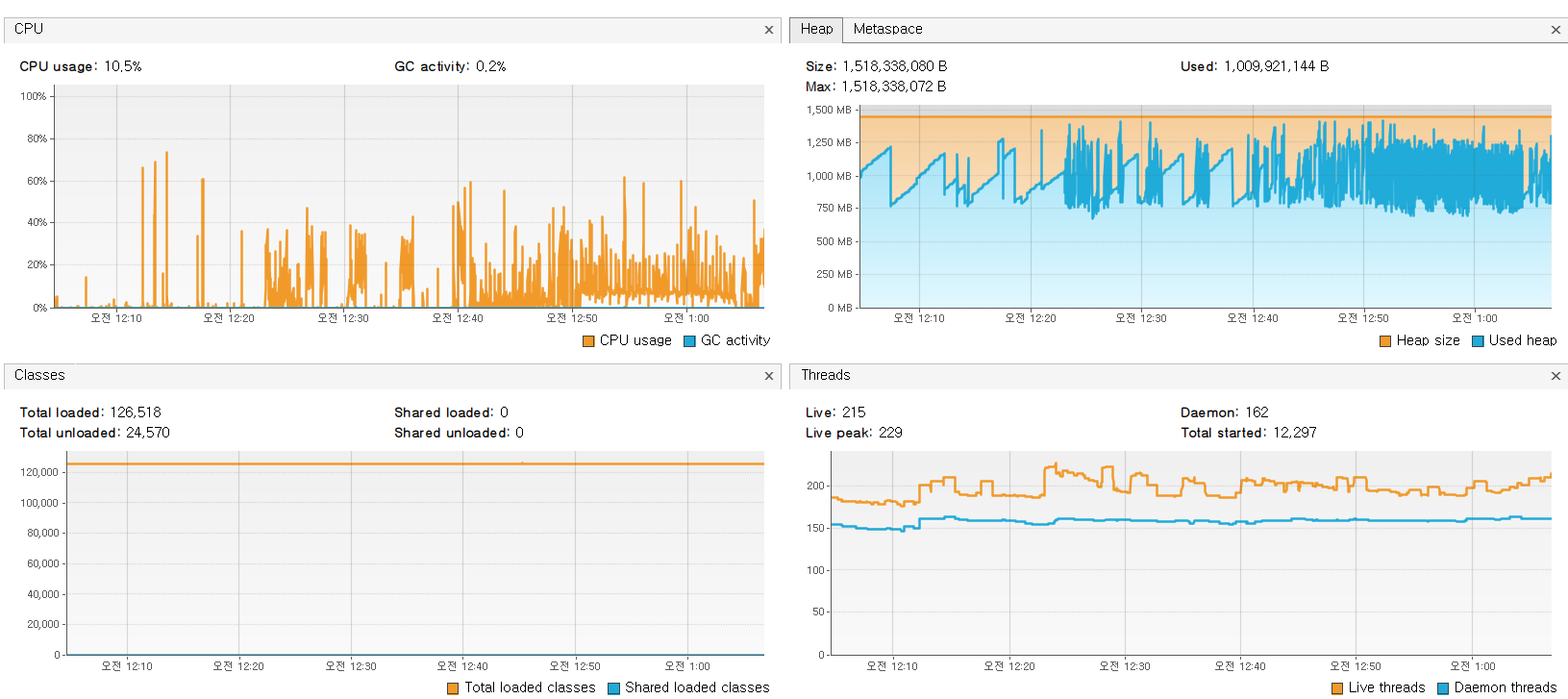
Aggregating Step이 Map을 통해서 ISBN를 Key로 Loan_Cnt을 합산하는 과정에서 map의 다량의 ISBN과 Loan_cnt 데이터가 포함돼 메모리의 양이 급격하게 증가할 것이란 건 예상 했었지만, DB와 연결하는 UpdateStep에서 CPU와 Memory 사용량이 더 높을 것이라고는 생각하지 못했다.
- Chunk 기반의 멀티 쓰레드를 통한 병렬 작업 때문일까?
배치를 사용하기 전 코드
- 각각의 실행은 Executor라는 클래스가 담당해서 실시 했다. 각각의 필요한 Step은 별도의 ExecutionStep이라는 인터페이스로 정의해서 List의 형태로 매개변수로 받아 해당 Step만 실행하는 구조이다.
public class LibraryCatalogExecutor {
private final LibraryCatalogDownloader libraryCatalogDownloader;
// targetDate "(2023년 06월)"
@BatchLogging
public void executeProcess(Path input, List<ExecutionStep> executionSteps,
ExecutionStep... skipSteps) {
AtomicReference<Path> currentPath = new AtomicReference<>(input);
List<ExecutionStep> skipList = Arrays.stream(skipSteps).toList();
List<Path> completePath = new ArrayList<>();
executionSteps.stream()
.filter(step -> !skipList.contains(step))
.forEach(executionStep -> {
try {
Path outPutPath = executionStep.execute(currentPath.get());
if (!currentPath.get().subpath(0, 2).toString().equals("pipe/endStep")) {
completePath.add(currentPath.get());
}
currentPath.set(outPutPath);
} catch (IOException e) {
throw new UncheckedIOException(e);
}
});
completePath.forEach(this::clearDirectory);
}- Executor에게 Step 목록을 전달하는 StepBuilder
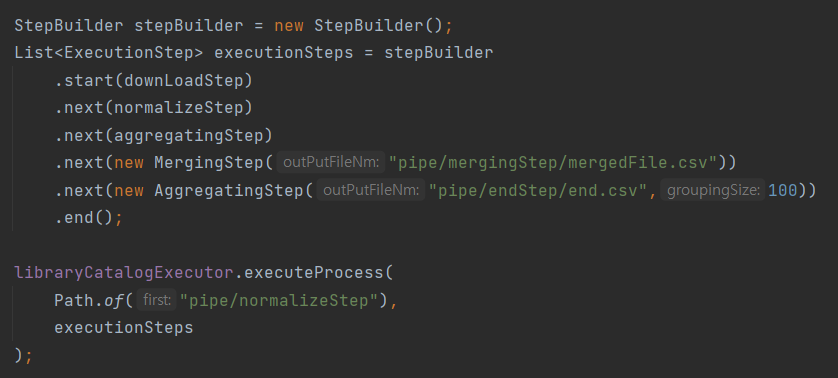
Executor에게 Step 목록을 전달하기 위해서 Builder 패턴을 사용 했다. StepBuilder의 코드는 아래와 같이 간단하다.
public class StepBuilder {
private List<ExecutionStep> executionSteps;
public StepBuilder start(ExecutionStep step){
if(executionSteps == null){
executionSteps = new ArrayList<>();
executionSteps.add(step);
}
return this;
}
public StepBuilder next(ExecutionStep nextStep){
if(executionSteps == null){
throw new IllegalArgumentException();
}
executionSteps.add(nextStep);
return this;
}
public List<ExecutionStep> end(){
return this.executionSteps;
}
}- ExecutionStep 인터페이스는 아래와 같이 execute 메소드를 구현해 작동한다. 반환하는 Path는 다음 Step이 참조할 Path를 뜻한다. 각 Step 별로 정해진 Directory가 있다.
public interface ExecutionStep {
Path execute(Path input) throws IOException;
}어찌보면 Spring batch와 스타일이 비슷하다. Spring Batch를 학습하며 참고해서 기존에 복잡 했던 Executor Class를 Step과 StepBuilder를 통해 리팩토링 했다.
배치에서의 코드
아래는 대출 횟수 최신화 Batch Config 코드의 일부분이다. Simple Job으로 구성되며, downloadStep부터 endAggregateStep까지는 기존에 사용하던 자바 I/O 기반의 코드들을 가져다가 활용해서 작업하고 있다. 그 이유는 여러개의 File과 대용량 데이터를 Spring Batch의 청크 기반 Task로 작업하는데에 아직 학습이 부족해 적용하지 못했다.
다만 그 다음부터 단계 Chunck 기반으로 Spring Batch가 제공하는 ItemReader와 ItemWriter를 사용해서 작업하고 있다.
public class LoanCntUpdateBatchConfig {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
private final LibraryCatalogDownloader libraryCatalogDownloader;
private final LibraryCatalogWriter libraryCatalogWriter;
private final DownLoadFileClearTask downLoadFileClearTask;
private static final int GROUP_SIZE = 100;
@Bean
public Job libraryCatalogBatch() {
return jobBuilderFactory.get("updateLoanCntJob")
.start(downloadStep(null)) // Crawler와 조합해 File Download
.next(normalizeStep()) // 불필요한 데이터 제거. noraml format에 맞게 data cleansing
.next(aggregateStep())// ISBN별로 대출 횟수를 집계
.next(mergeStep()) // 합산 작업이 완료된 파일 하나로 합치기
.next(endAggregateStep()) //합쳐진 파일을 대상으로 다시 대출 횟수 집계
.next(updateToBookStep()) // DB와 연결하여 대출 횟수 update 및 update 필요한 도서 추가
.next(fileClearStep()) // 작업 완료 후 다운로드 및 작업 File 삭제
.build();
}Spring Batch 학습하며 적용해본 이후 회고
- 추상화를 좋아하는 Spring이 왜 Java I/O쪽에 대해선 추상화를 하지 않을까 의문이 과거에 들었지만, Spring Batch가 그 역할을 하고 있었다.
- 대량의 데이터에 의해 소요시간이 오래 걸리는 작업을 하며 중간에 오류가 나면 처음부터 다시 시작 해야하는 경우가 많았는데, Spring Batch는 Job과 Step Execution 상태 등을 DB에 저장하여 이 문제를 해결 했다. 정말 나이스한 해결 방식이다.
- Spring Batch의 러닝 커브는 다소 높게 느껴졌으며 보다 더 심도깊은 학습이 필요하다.
