
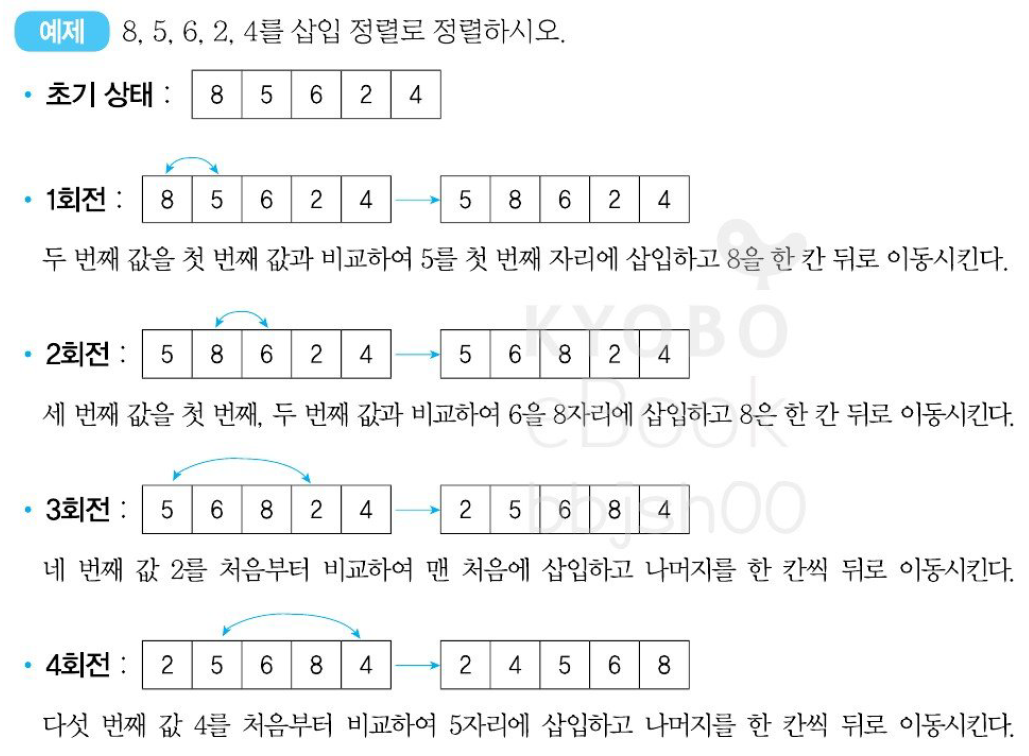
삽입 정렬(Insertion Sort)
- 삽입 정렬은 가장 간단한 정렬 방식으로 이미 순서화된 파일에 새로운 하나의 레코드를 순서에 맞게 삽입시켜 정렬한다.
- 두 번째 키와 첫 번째 키를 비교해 순서대로 나열(1회전)하고, 이어서 세 번째 키를 첫 번째, 두 번째 키와 비교해 순서대로 나열(2회전)하고, 계속해서 n번째 키를 앞의 n-1개의 키와 비교하여 알맞은 순서에 삽입하여 정렬하는 방식이다.
- 평균과 최악 모두 수행 시간 복잡도는 O()이다.
쉘 정렬(Shell Sort)
- 쉘 정렬은 삽입 정렬(Insertion Sort)을 확장한 개념이다.
- 입력 파일을 어떤 매개변수(h)의 값으로 서브파일을 구성하고, 각 서브파일을 Insertion 정렬 방식으로 순서 배열하는 과정을 반복하는 정렬 방식(보통 h=), 즉 임의의 레코드 키와 값만큼 떨어진 곳의 레코드 키를 비교하여 순서화되어 있지 않으면 서로 교환하는 것을 반복하는 정렬 방식이다.
- 입력 파일이 부분적으로 정렬되어 있는 경우에 유리한 방식이다.
- 평균 수행 시간 복잡도는 O()이고, 최악의 수행 시간 복잡도는 O()이다.
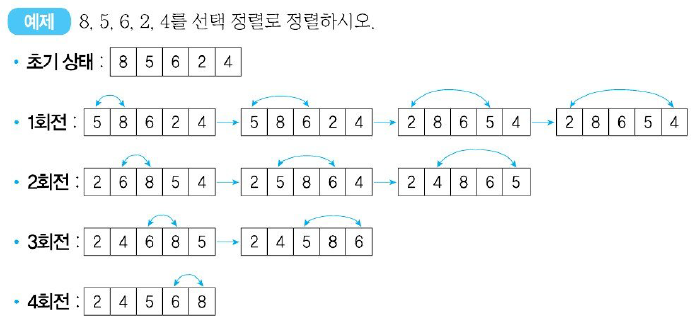
선택 정렬(Selection Sort)
- 선택 정렬은 1개의 레코드 중에서 최소값을 찾아 첫 번째 레코드 위치에 놓고, 나머지 (n-1)개 중에서 다시 최소값을 찾아 두 번째 레코드 위치에 놓는 방식을 반복하여 정렬하는 방식이다.
- 평균과 최악 모두 수행 시간 복잡도는 O()이다.
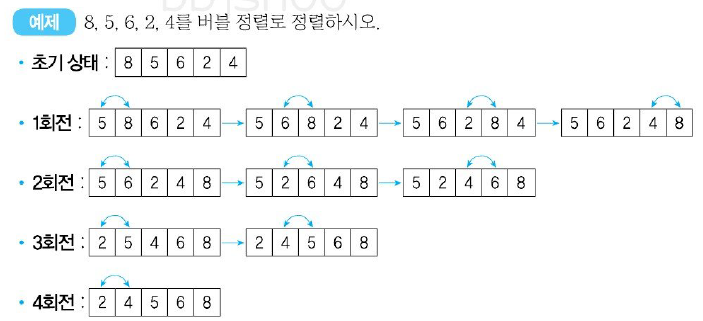
버블 정렬(Bubble Sort)
- 버블 정렬은 주어진 파일에서 인접한 두 개의 레코드 키 값을 비교하여 그 크기에 따라 레코드 위치를 서로 교환하는 정렬 방식이다.
- 계속 정렬 여부를 플래그 비트(f)로 결정한다.
- 평균과 최악 모두 수행 시간 복잡도는 O()이다.
퀵 정렬(Quick Sort)
- 퀵 정렬은 레코드의 많은 자료 이동을 없애고 하나의 파일을 부분적으로 나누어 가면서 정렬하는 방법으로 키를 기준으로 작은 값은 왼쪽에, 큰 값은 오른쪽 서브파일로 분해시키는 방식으로 정렬한다.
- 위치에 관계없이 임의의 키를 분할 원소로 사용할 수 있다.
- 정렬방식 중에서 가장 빠른 방식이다.
- 프로그램에서 되부름을 이용하기 때문에 스택(Stack)이 필요하다.
- 분할(Divide)과 정복(Conquer)을 통해 자료를 정렬한다.
- 분할(Divide) : 기준값인 피봇(Pivot)을 중심으로 정렬할 자료들을 2개의 부분집합으로 나눈다.
- 정복(Conquer) : 부분집합의 원소들 중 피봇(Pivot)보다 작은 원소들은 왼쪽, 피봇(Pivot)보다 큰 원소들은 오른쪽 부분집합으로 정렬한다.
- 부분집합의 크기가 더 이상 나누어질 수 없을 때까지 분할과 정복을 반복 수행한다.
- 평균 수행 시간 복잡도는 O(nn)이고, 최악의 수행 시간 복잡도는 O()이다.
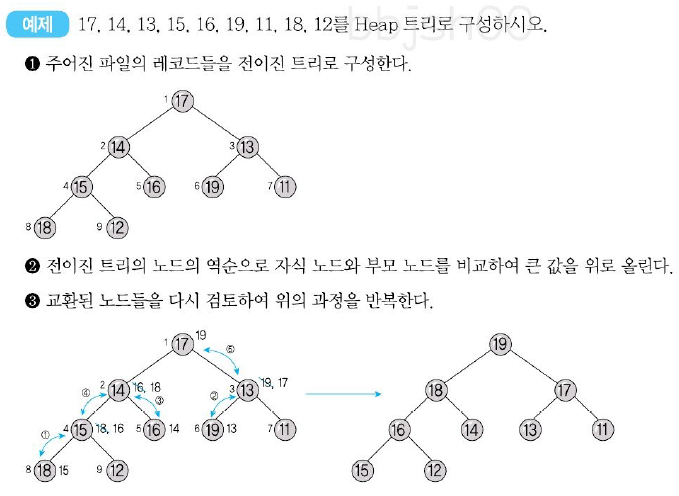
힙 정렬(Heap Sort)
- 힙 정렬은 전이진 트리(Complete Binary Tree)를 이용한 정렬 방식이다.
- 구성된 전이진 트리를 Heap Tree로 변환하여 정렬한다.
- 평균과 최악 모두 시간 복잡도는 O(n)이다.
2-Way 합병 정렬(Merge Sort)
- 2-Way Merge Sort는 이미 정렬되어 있는 두 개의 파일을 한 개의 파일로 합병하는 정렬 방식이다. 그 방법은 다음과 같다.
- 두 개의 키들을 한 쌍으로 하여 각 쌍에 대하여 순서를 정한다.
- 순서대로 정렬된 각 쌍의 키들을 합병하여 하나의 정렬된 서브리스트로 만든다.
- 위 과정에서 정렬된 서브리스트들을 하나의 정렬된 파일이 될 때까지 반복한다.
- 평균과 최악 모두 시간 복잡도는 O(n)이다.

기수정렬(Radix Sort) = Bucket Sort
- 기수정렬은 Queue를 이용하여 자릿수(Digit)별로 정렬하는 방식이다.
- 레코드의 키 값을 분석하여 같은 수 또는 같은 문자끼리 그 순서에 맞는 버킷에 분배 하였다가 버킷의 순서대로 레코드를 꺼내어 정렬한다.
- 평균과 최악 모두 시간 복잡도는 O(dn)이다.
출처: 2024 시나공 정보처리기사 필기 기본서

alpaka의 자격증 공부장