
관계형 데이터베이스의 개요
- 1970년 IBM에 근무하던 코드(E. F. Codd)에 의해 처음 제안되었다.
- 관계형 데이터베이스를 구성하는 개체(Entity)나 관계(Relationship)를 모두 릴레이션(Relation)이라는 표(Table)로 표현한다.
- 릴레이션은 개체를 표현하는 개체 릴레이션, 관계를 나타내는 관계 릴레이션으로 구분할 수 있다.
- 장점: 간결하고 보기 편리하며, 다른 데이터베이스로의 변환이 용이하다.
- 단점: 성능이 다소 떨어진다.
관계형 데이터베이스의 Relation 구조
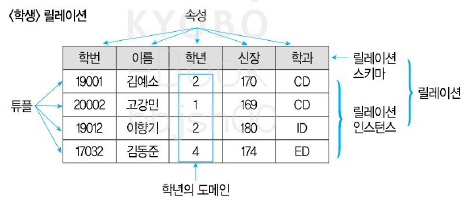
- 릴레이션은 데이터들을 표(Table)의 형태로 표현한 것으로 구조를 나타내는 릴레이션 스키마와 실제 값들인 릴레이션 인스턴스로 구성된다.
튜플(Tuple)
- 튜플은 릴레이션을 구성하는 각각의 행을 말한다.
- 튜플은 속성의 모임으로 구성된다.
- 파일 구조에서 레코드와 같은 의미이다.
- 튜플의 수를 카디널리티(Cardinality) 또는 기수, 대응수라고 한다.
속성(Attribute)
- 속성은 데이터베이스를 구성하는 가장 작은 논리적 단위이다.
- 파일 구조상의 데이터 항목 또는 데이터 필드에 해당된다.
- 속성은 개체의 특성을 기술한다.
- 속성의 수를 디그리(Degree) 또는 차수라고 한다.
도메인(Domain)
- 도메인은 하나의 애트리뷰트가 취할 수 있는 같은 타입의 원자(Atomic)값들의 집합이다.
- 도메인은 실제 애트리뷰트 값이 나타날 때 그 값의 합법 여부를 시스템이 검사하는데에도 이용된다.(성별 애트리뷰트의 도메인은 '남'과 '예'로, 그 외의 값은 입력될 수 없다.)
릴레이션의 특징
- 한 릴레이션에는 똑같은 튜플이 포함될 수 없으므로 릴레이션에 포함된 튜플들은 모두 상이하다.(<학생> 릴레이션을 구성하는 김예소 레코드는 김예소에 대한 학적 사항을 나타내는 것으로 <학생> 릴레이션 내에서는 유일하다.)
- 한 릴레이션에 포함된 튜플 사이에는 순서가 없다.(<학생> 릴레이션에서 김예소 레코드와 고강민 레코드의 위치가 바뀌어도 상관없다.)
- 튜플들의 삽입, 삭제 등의 작업으로 인해 릴레이션은 시간에 따라 변한다.(<학생> 릴레이션에 새로운 학생의 레코드를 삽입하거나 기존 학생에 대한 레코드를 삭제함으로써 테이블 은 내용 면에서나 크기면에서 변하게 된다.)
- 릴레이션 스키마를 구성하는 속성들 간의 순서는 중요하지 않다.(학번, 이름 등의 속성을 나열하는 순서가 이름, 학번 순으로 바뀌어도 데이터 처리에는 아무런 영향을 미치지 않는다.)
_ 속성의 유일한 식별을 위해 속성의 명칭은 유일해야 하지만, 속성을 구성하는 값은 동일한 값이 있을 수 있다.(각 학생의 학년을 기술하는 속성인 '학년은 다른 속성명들과 구분되어 유일해야 하지만 '학년' 속성에는 2, 1, 2, 4 등이 입력된 것처럼 동일한 값이 있을 수 있다.)- 릴레이션을 구성하는 튜플을 유일하게 식별하기 위해 속성들의 부분집합을 키(Key)로 설정한다.(<학생> 릴레이션에서는 '학번'이나 '이름'이 튜플들을 구분하는 유일한 값인 키가 될 수 있다.)
- 속성의 값은 논리적으로 더 이상 쪼갤 수 없는 원자값만을 저장한다.('학년'에 저장된 1. 2. 4 등은 더 이상 세분화할 수 없다.)

alpaka의 자격증 공부장