Kafka
1.Kafka란?

Kafka란? > Kafka란? 실시간으로 기록 스트림을 게시, 구독, 저장 및 처리 할 수 있는 분산형 데이터 스트리밍 플랫폼. > > 대량의 데이터를 안정적이고 실시간으로 처리할 수 있도록 설계되었다. 카프카는 주로 대량의 이벤트 스트림 데이터를 처리하고 여러 시
2.스키마 레지스트리
Apache Kafka를 기반으로 데이터 스트리밍 플랫폼에서 스키마 관리를 위한 중앙 집중화된 서비스즉, 메시지의 구조(스키마)를 중앙에서 관리하고, 데이터의 일관성과 호환성을 보장하는 독립적인 애플리케이션카프카의 topic은 정해진 규정이 없기 때문에 어떤 형태의 메
3.Kafka Producer
사용자가 작성한 이벤트를 파티션 단위 로그에 기록하여 브로커에 전달하는 클라이언트 컨포넌트.아파치 카프카 생태계 내에서 카프카 Topic에 정보를 전송 또는 생성하는 클라리언트 애플리케이션직렬화(Serialization): 메세지 키와 값을 바이트 배열로 변환파티셔닝(
4.Kafka Broker
데이터를 저장하고 모든 데이터 스트리밍 요청을 처리하는 서버카프카 클러스터 내에서 실제 메세지를 저장, 검색 및 배포 그리고 클라이언트와의 통신을 담당한다.각 브로커는 퍼블리셔의 데이터를 처리하고 컨슈머에게 데이터를 제공하며 파티션 및 오프셋 상태를 유지하는 서버.즉,
5.Apache Avro
Avro란 Apache에서 만든 데이터 직렬화 시스템으로써, 다량의 데이터를 효율적으로 저장하고 관리하기 위한 개방형 데이터 직렬화 프레임워크이다.Avro는 JSON 스키마를 동봉한 상태로 데이터를 직렬화하기 때문에, 읽을 때 별도의 스키마 사전 지식 없이도 데이터를
6.Local-postgreSQL 환경에서 CDC 구축하기
이전 직장에서 운영중인 DB를 마이그레이션하는 작업을 한 경험이 있다. 그 절차가 마이그레이션이 필요한 테이블이나 칼럼을 새로 추가하고 Dual-write 방식으로 동시 쓰기를 진행하며 실시간 전환을 하도록 시스템을 구축하였다.하지만, 이직을 위해 면접을 보러다니는 와
7.Kafka Tombstone
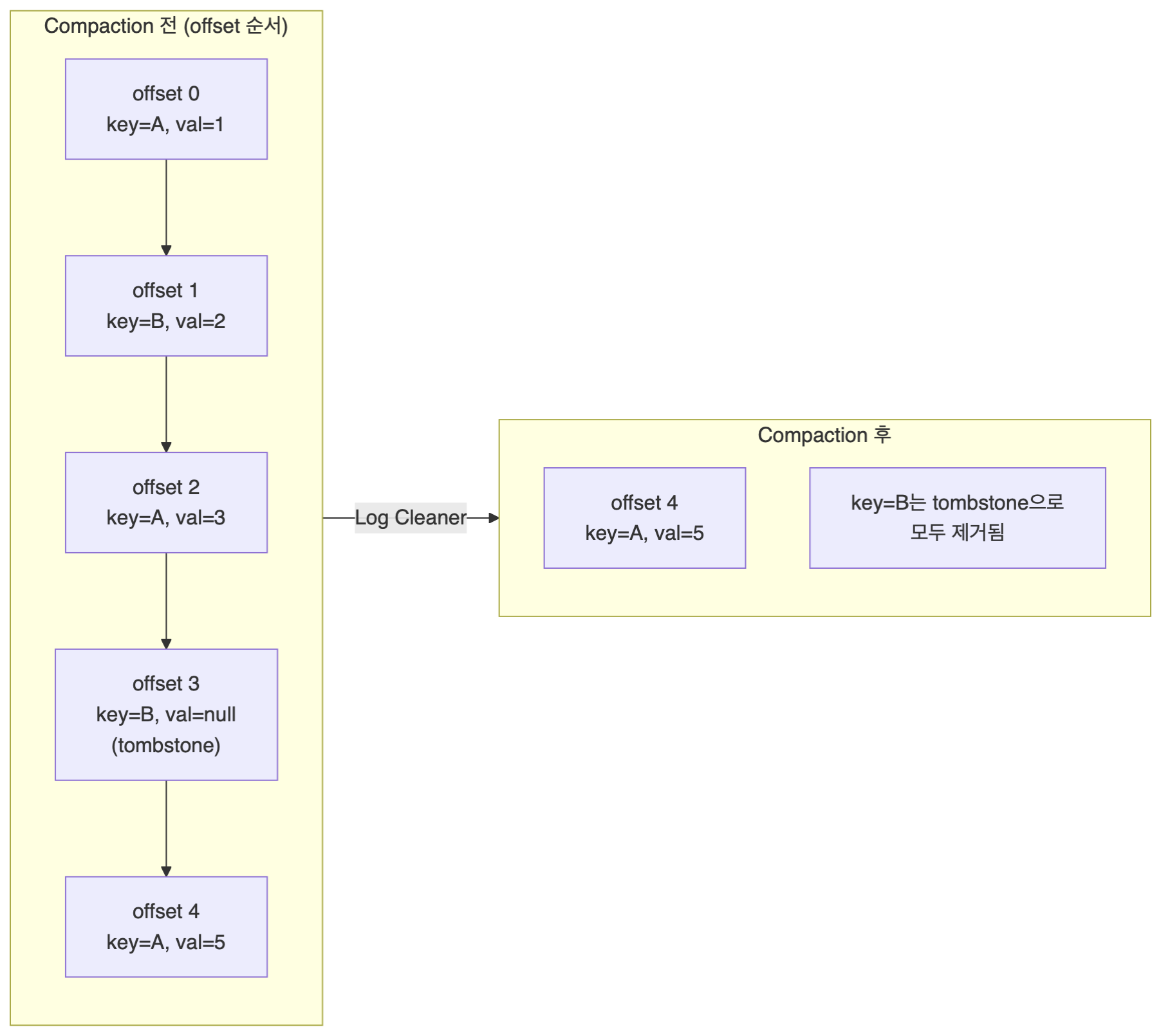
카프카 Topic의 삭제 마커로 사용하기 위해 발행하는 메시지를 말한다.Key는 있고, valude는 null인 레코드를 말하며, cleanup.policy=compact 토픽에서만 작동한다.요컨데, 발행한 메시지를 삭제할 수 없는 카프카 브로커에서 메시지를 삭제하기