메모리 내용만 나오면 뇌가 굳어버리는 질환이 생겨버렸습니다 ㅋㅋㅋㅋ 어떡하겠어요 극복해야죠,,,ㅠㅠ 그래도 여러 메모리 관련 알고리즘의 원리나 어떻게 진화를 하였는 지 논리적으로 이해가 되다보면 재밌는거 같아요!
Chapter 15는 파일시스템인데 이는 시스템 프로그래밍 공부 때 배웠었기 때문에 인터넷 서칭과 복기를 하면서 자세히 필기를 하였습니다!
다음 사진은 제가 vmware에서 만든 
virtual machine입니다! 🙂
아무튼 이렇게 한달 동안 '혼자 공부하는 컴퓨터구조와 운영체제'와 함께 공부해보았는데 너무 알차고 이런 프로젝트가 아니였다면 제 스스로 시간을 버리면서 놀고 있었을거 같아요 ㅠㅠ 따봉 짱짱입니다! 너무 좋은 기회였고 다음에도 혼공족 14기가 열린다면 하고 싶습니다! 아마 그때는 인공지능쪽이나 CS관련 책이 있다면 그쪽을 하지 않을까 싶네요🫡
그럼 14-15주차 내용인 가상메모리와 파일 시스템 공부를 진행해보겠습니다!
⚠ 아래 내용은 책 개념 + 인터넷 정보 등이 포함되어있습니다. ⚠
( 📢 수정할 내용이 있다면 알려주세요! )
📚Ch.14 가상 메모리
연속 메모리 할당
연속 메모리 할당은 프로세스에 연속적인 메모리 공간을 할당하는 것입니다.
메모리에 프로세스를 적재하였지만 해당 프로세스가 실행중이지 않는다면 보조기억장치의 swap space에 swap out을 시킵니다. 이에 해당 메모리 공간은 비게 되며 이 공간에 다른 프로세스를 적재할 수 있습니다. swap space에 있던 프로세스를 다시 메모리에 옮기는 것을 swap in이라고 합니다.
☝ first fit
최초 적합은 운영체제가 메모리의 빈 공간을 순차탐색하다가 빈 공간을 발견시에 프로세스를 적재하는 방식입니다.
이에 탐색을 최소화하여 빠른 할당을 할 수 있습니다.
👍 best fit
최적 적합은 운영체제가 메모리의 빈 공간을 '모두' 검색해본 후 적재할 수 있는 빈 공간 중에서 가장 적은 메모리 공간에 할당하는 방식입니다.
👎 worst fit
최악 적합은 최적 적합과 반대로 가장 큰 빈 공간에 할당하는 방식입니다.
이렇게 프로세스를 연속적으로 배치하는 것은 메모리를 효율적으로 사용하는 방법은 아닙니다. 이는 external fragmentation문제를 가지기 때문입니다.
외부 단편화 문제는 실행과 종료를 반복하는 프로세스들에 의해 메모리 사이사이에 빈 공간들이 생기는데 이런 것들 때문에 용량이 큰 프로세스를 할당하기 어려운 경우가 생길 수 있으며 메모리 낭비의 결과로 이어지는 것을 말합니다.
이런 외부 단편화는 프로세스가 swap out되고 기존 공간보다 작은 프로세스가 할당되었을 때 발생하곤 합니다. 이런 경우, 외부 단편화를 해결하기 위한 대책으로는 메모리를 '압축'하는 것이 있습니다. 메모리 압축은 외부 단편화를 발생시킨 작은 빈 공간을 프로세스들을 하나의 덩어리처럼 모아 압축시키는 방법입니다.
하지만 이 압축을 하기 위해서는 많은 작업이 요구되고 외에도 여러 고려 사항이 많기에 다른 방안이 필요합니다. 이에 페이징 기법이 있습니다.
📑 페이징을 통한 가상 메모리 관리
외부 단편화 외에도 연속적인 메모리 할당 방식은 메모리의 크기보다 더 큰 용량의 프로그램을 실행시킬 수 없다는 문제 또한 존재합니다.
가상 메모리는 이런 문제를 위해 실행하려는 프로그램 일부만 메모리에 적재해 큰 용량의 프로세스를 실행할 수 있게 하는 기술입니다.
이 가상 메모리 기법에 페이징이 있으며 이로써 물리 메모리와 외부 단편화 문제를 해결할 수 있습니다.
페이징은 프로세스의 논리 주소 공간을 page 단위로 자르고 메모리 물리 주소 공간을 frame 단위로 자른 뒤에 페이지를 프레임에 할당하는 방식입니다. 이에 기존의 프로세스 하나의 swap out이나 swap in이 아닌 page 단위로의 page out, page in으로 이루어집니다.
이렇게 페이지 단위로 자르고 불연속적으로 배치가 되어있으면 순차적으로 실행하기 어렵기에 page table을 사용합니다.
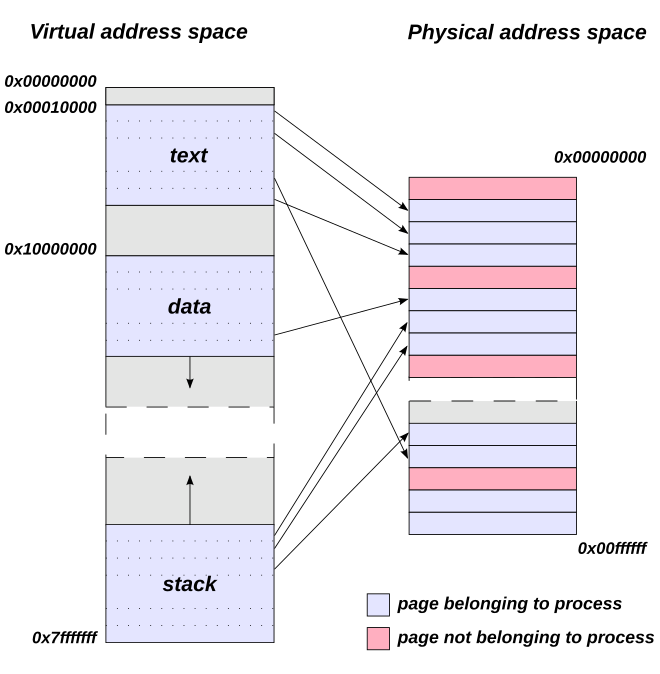
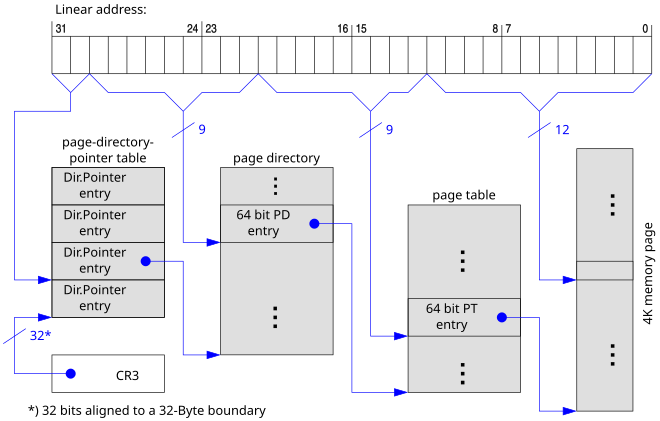
페이지 테이블은 위 이미지와 같이 virtual address space와 Physical address space 사이의 매핑을 저장하기 위해 이용되는 데이터 구조입니다.
다음의 표와 같이 나타낼 수 있습니다.
프로세스 A의 페이지 테이블 :
| 페이지 번호 | 프레임 번호 |
|---|---|
| 0 | 3 |
| 1 | 5 |
| 2 | 9 |
이렇게 프로세스마다 프로세스 테이블을 가지며 프로세스의 페이지 테이블은 메모리에 적재되어 있습니다. 또한 CPU 내 PTBR(Page Table Base Register)이 각 프로세스의 페이지 테이블이 적재된 주소를 가리킵니다.
하지만 다음 사진과 같이 PTBR이 아닌 TLB라는 페이지 테이블의 캐시 메모리를 볼 수 있는데요, 이는 페이지 테이블을 메모리에 적재하면 메모리 접근 시간이 늘어나기 때문입니다. (페이지 테이블 접근과 프레임 접근이 이루어짐)
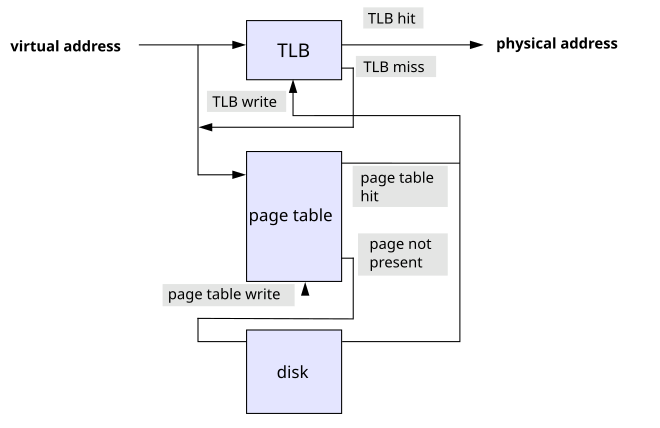
- TLB : Translation Lookaside Buffer의 약어로, 페이지 테이블의 일부 내용을 저장합니다.
이에 이전의 Cache hit/miss의 개념과 비슷하게 TLB hit/miss가 존재하며 TLB miss의 경우에는 사진의 경우처럼 메모리 내의 페이지 테이블에 접근합니다.
페이징 시스템에서는 모든 논리 주소가 page number(접근하려는 페이지 번호)와 offset(접근하려는 주소가 프레임의 시작 번지로부터 얼마나 떨어져 있는지를 알기 위한 정보)으로 이루어져 있습니다. 이에 (page num, offset) -> 페이지 테이블 -> (frame num, offset)의 과정으로 논리 주소에서 물리 주소로 변환이 됩니다.
'The page table is an array of page table entries.'
페이지 테이블 엔트리(PTE)에는 페이지 번호, 프레임 번호 외에 유효비트, 참조비트 등 여러 정보들이 있습니다.
-
유효 비트(valid bit) : 현재 해당 페이지 접근 가능의 여부. [ 1 : 메모리 적재 Y / 0 : 메모리 적재 N]
-
보호 비트(protection bit) : 페이지 보호 기능을 위해 존재. [1 : readNwrite / 0 : read_only]
- 이때 r,w,x를 사용해서 110, 001, 111의 형식으로 읽기, 쓰기, 실행의 권한을 나타낸다.
-
참조 비트(reference bit): CPU가 이 페이지에 접근한 적이 있는 지의 여부. [1 : 적재 이후 r/w된 페이지 / 0 : 적재 이후 r,w 된 적 없는 페이지]
-
수정 비트(dirty or modified bit) : 해당 페이지에 데이터를 쓴 적이 있는 지의 여부. [1 : 변경된 적이 있는 페이지 / 0 : 변경된 적이 없는 페이지]
- 이때 변경되지 않았다는 것은 참조비트 0과 같이 접근한 적이 없거나 읽기만 했던 페이지임을 의미한다.
- 수정비트가 0일 경우에는, swap out이 될 경우 아무런 추가적 작업이 필요 없이 새로 적재된 페이지로 덮어쓰기만 하면 된다.
- 수정비트가 1일 경우에는, swap out시에 변경된 값을 보조기억장치에 기록하는 추가적인 작업이 필요하다.
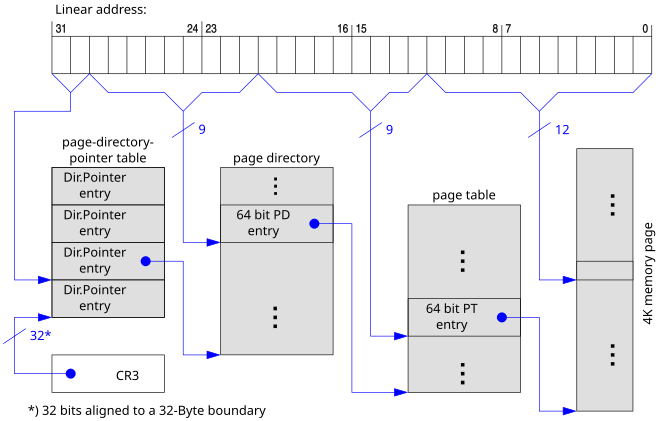
@Wikipedia Multilevel page tables
The inverted page table keeps a listing of mappings installed for all frames in physical memory. However, this could be quite wasteful. Instead of doing so, we could create a page table structure that contains mappings for virtual pages. It is done by keeping several page tables that cover a certain block of virtual memory. For example, we can create smaller 1024-entry 4 KB pages that cover 4 MB of virtual memory.
This is useful since often the top-most parts and bottom-most parts of virtual memory are used in running a process - the top is often used for text and data segments while the bottom for stack, with free memory in between. The multilevel page table may keep a few of the smaller page tables to cover just the top and bottom parts of memory and create new ones only when strictly necessary.
Now, each of these smaller page tables are linked together by a master page table, effectively creating a tree data structure. There need not be only two levels, but possibly multiple ones. For example, a virtual address in this schema could be split into three parts: the index in the root page table, the index in the sub-page table, and the offset in that page.
Multilevel page tables are also referred to as "hierarchical page tables".
📤페이지 교체와 프레임 할당
Demand paging
요구 페이징은 프로세스의 필요한 페이지만을 메모리에 적재하는 기법입니다. 이 기법으로 페이지를 적재하다보면 메모리가 꽉차는 경우가 생기며 이에 메모리에 적재된 페이지를 다시 보조기억장치로 보낼 필요가 생깁니다. 어떤 페이지를 교체시킬 지 결정하는 알고리즘이 바로 페이지 교체 알고리즘입니다.
페이지 교체 알고리즘
좋은 페이지 교체 알고리즘은 page fault를 적게 발생시키는 알고리즘입니다. (CPU가 valid bit가 0인 메모리에 적재되어 있지 않은 페이지로 접근할 경우 발생하는 Exception) 이는 page fault가 발생하면 필요한 페이지를 보조기억장치에서 가져와야 하며 이는 메모리에 적재된 경우보다 느리기 때문입니다.
따라서 좋은 알고리즘을 판별하기 위해 필요한 것은 page fault 횟수이며 page reference string을 통해 알 수 있습니다.
☝ FIFO
fifo page replacement Algorithm은 메모리에 가장 먼저 올라온 페이지부터 교체하는 알고리즘입니다.
자주 참조되는 페이지가 교체될 단점이 존재합니다.
✌ Second Chance
fifo와 기본적으로는 비슷하지만 해당 페이지의 reference bit를 검사하여 1일 경우, second chance로 이를 0으로 바꾼 뒤 현재 시간을 적재 시간으로 설정합니다.
🏅 Optimal
optimal page replacement Algorithm은 CPU에 의해 참조되는 횟수를 고려하는 알고리즘입니다. 즉, 앞으로의 참조 횟수가 가장 낮은 페이지를 교체합니다. 이를 통해서 타 페이지 교체 알고리즘보다 page fault의 발생 빈도가 가장 낮습니다.
하지만 이 알고리즘의 구현은 미래의 참조할 페이지와 아닌 페이지를 예측해야한다는 점에서 어렵습니다. 이에 페이지 교체 알고리즘을 평가하기 위해 사용되기도 합니다.
🏆 LRU
Least Recently Used page replacement Algorithm은 Optimal 알고리즘과 비슷합니다.
하지만 예측이라는 요소 없이 그저 가장 참조가 되지 않은 페이지를 교체한다는 점에서 구현의 난이도가 낮아집니다.
⏱ 스래싱과 프레임 할당
page fault 발생의 원인은 알고리즘 외에 프로세스의 사용 가능한 프레임의 수와도 연관이 있습니다. 프레임 수가 많으면 page fault가 발생할 가능성이 적어지기 때문입니다.
프레임이 부족하면 CPU의 효율과 생산성이 떨어지고 '프로세스가 실행되는 시간보다 페이징에 소요되는 시간이 길어져 성능이 저해'됩니다. 이를 thrashing이라 합니다.
trashing을 방지하기 위해 운영체제는 각 프로세스들이 필요한 최소한의 프레임 수를 파악하고 할당해줍니다.
- 균등 할당(equal allocation) : 모든 프로세스에 균등하게 프레임 할당.
- 비례 할당(proportional allocation) : 프로세스의 크기에 비례하는 프레임 할당.
하지만 이는 프로세스를 실행해 보고 나서 실제 필요한 프레임을 알 수 있는 경우가 많습니다. 이에 실행하는 과정에서 배분할 프레임을 결정합니다.
- 작업 집합 모델(working set model)
- 페이지 폴트 빈도(PFF, page fault frequency)
🗂 Ch.15 파일 시스템
파일과 디렉터리
- 파일 : 하드디스크나 보조기억장치에 저장된 관련 정보의 집합.
- 디렉터리 : 디렉터리는 파일과 비슷하며 해당 디렉터리에 저장된 파일이나 하위 디렉터리이에 관한 정보가 저장.
- 이에 디렉터리는 계층구조(트리구조)를 띰.
- 루트 디렉터리 : 가장 최상위 디렉터리로 / 로 표현.
- 작업 디렉터리 : 현재 사용중인 디렉터리로 . 으로 표시.
- 홈 디렉터리 : 각 사용자에게 할당된 디렉터리로, ~로 표시. 처음 사용자 계정을 만들 때 지정됨.
- 이에 디렉터리는 계층구조(트리구조)를 띰.
경로명은 파일 시스템에서 디렉터리 계층 구조에 있는 특정 파일이나 디렉터리 위치를 표시합니다.
이에 파일마다 절대경로명과 상대경로명이 존재합니다.
- 절대경로 : 항상 /(루트)로 시작하여 중간에 거치는 모든 디렉터리의 이름을 표시하게 된다. 이에 특정위치를 나타내는 절대경로명은 항상 동일.
- 상대경로 : / 이외의 문자로 시작할 수 있으며, 현재 디렉터리를 기준으로 상위 디렉으로 가려면 ..을 추가하면 됨. 이에 현재 디렉터리가 어딘 지에 상대 경로명은 달라질 수 있으며, 하위 디렉터리로 갈 경우 디렉 사이에 슬래시는 구분자의 역할.
파일을 다루는 작업은 운영체제에 의해 이루어지며 프로그램이 파일을 이용하기 위해서 운영체제는 시스템 호출을 제공합니다.
대표적으로는 make/remove/open/close/read가 있습니다.
파일 시스템
하나의 컴퓨터에서 여러 종류의 파일 시스템을 사용 가능합니다.
저는 가상머신을 사용해서 파티셔닝과 포맷 작업 등을 통해 리눅스를 사용할 수 있었습니다.
Partitioning은 논리영역을 나누는 작업을 의미합니다. 이를 통해 나뉘어진 장치의 영역을 파티션이라고 합니다.
또한 Formatting은 파일 시스템을 설정하여 파일 관리 방식을 지정하는 것입니다.
@ 저는 리눅스에서 ext4 파일 시스템을 썼던거 같습니다. 이 파일 시스템에서는 효율적으로 disk를 사용하기 위해 저장 장치를 논리적인 블록의 집합(블록 그룹)으로 구분합니다.
- 블록그룹 0 : 파일시스템의 첫번째 블록그룹으로 특히 그룹 0 패딩과 수퍼블록, 그룹 디스크립터가 존재합니다.
- 블록그룹 a : 그룹 패딩이 존재하지 않는 블록그룹0의 복사본이라 생각할 수 있다.
- 블록그룹 b : 데이터블록 비트맵으로 시작.
다시 돌아와서 운영체제는 파일과 디렉터리를 블록단위로 읽고 쓰며 하나의 파일이 보조기억장치에 저장될 때는 하나 이상의 블록에 걸쳐 저장됩니다. 이에 파일을 보조기억장치에 할당하는 방법에는 다음이 있습니다.
- 연속 할당(contiguous allocation) : 파일이 블록에 걸쳐 연속적으로 할당된다. 외부 단편화 야기 가능.
- 연결 할당(linked allocation) : 각 블록 일부에 다음 블록의 주소를 저장하여 다음 블록을 가리키는 형태로 할당. (포인터와 비슷) 그러나 첫 블록을 읽는데 임의적으로 접근하는 속도가 느리며 파일을 이루는 블록 하나에 문제가 생길 시 접근이 불가능해 짐.
- 인덱스 할당(indexed allocation) : 파일의 모든 블록 주소를 index block에 모아 관리. 이에 인덱스 할당을 사용하는 fs에서는 디렉터리 엔트리에 index block의 주소를 명시한다.
FAT file system
FAT 파일 시스템은 연결 할당의 단점을 보완한 파일 시스템입니다.
FAT라는 '파일 할당 테이블'을 통하여 블록의 주소들을 한데 모아 테이블 형태로 관리하는 것입니다.
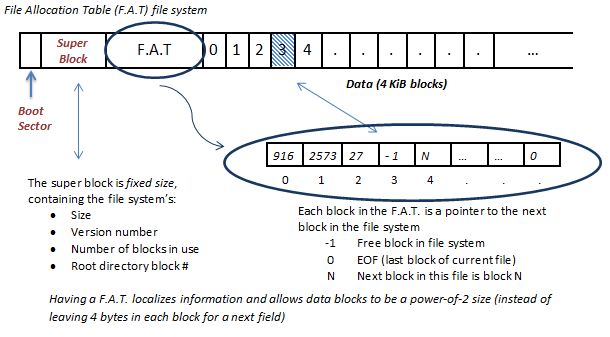
위 사진처럼 FAT 파일 시스템은 부트섹터와 슈퍼블록 뒤에 FAT가 위치하며 뒤로는 루트 디렉터리와 이후 서브 디렉터리, 파일들이 저장되는 데이터 영역으로 구분됩니다.
FAT 덕분에 기존의 연결 할당의 경우보다 다음 블록을 찾는 속도가 빨라지게 되며 임의 접근에도 용이합니다.
Unix file system
유닉스 파일 시스템은 인덱스 할당 기반의 파일 시스템 입니다.
inode에는 file's size, permissions, owner, links, and timestamps의 정보가 포함됩니다. 각각의 inode는 10 direct block pointers, 1 indirect block pointer, 1 doubly indirect block pointer을 포함할 수 있습니다.
또한 Unix 파일 시스템에서는 FAT 파일시스템과 동일하게 부트섹터, 슈퍼플록이 존재하고 그 옆에 inode table과 데이터영역이 존재합니다.
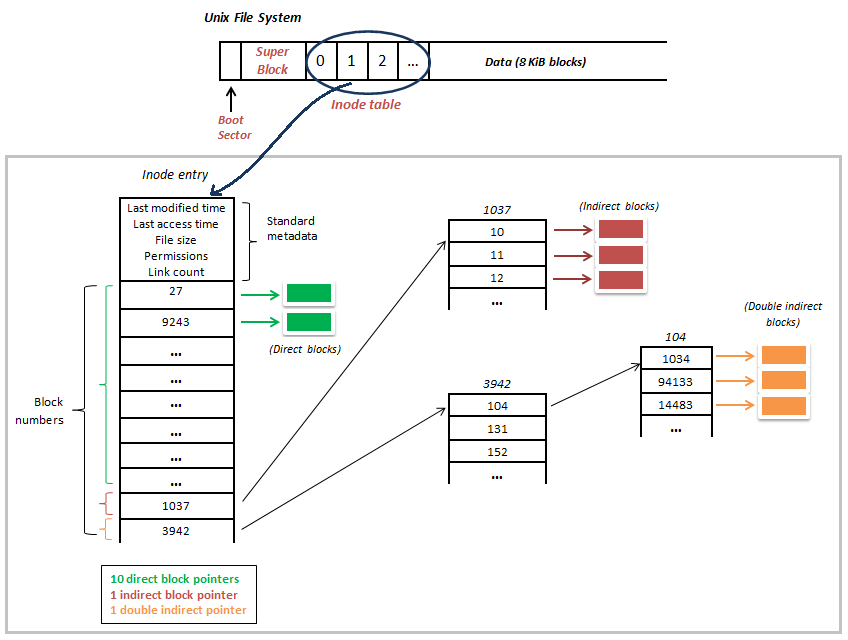
다음과 같이 inode에 direct, indirect, doubly indirect block의 용어가 사용되는 이유는 단순한 inode만으로는 많은 파일들의 블록들을 다 가리키기 어렵기 때문입니다.
- direct block : 블록 주소가 직접적으로 명시된 블록
- indirect block : 파일 데이터가 저장된 블록이 아닌 파일 데이터를 저장한 블록 주소가 저장된 블록
- doubly indirect block : indirect block들의 주소를 저장하는 블록
이외에도 triple indirect block이 이용될 수 있으며 이로써 웬만한 크기의 파일은 모두 표현할 수 있다고 합니다.
@ mount
유닉스, 리눅스에서는 mount라는 것이 존재합니다. 디렉터리 계층구조에 따라서 하나의 파일 시스템이 아닌 여러 파일 시스템으로 구성될 수 있습니다. 하지만 파일 시스템이 디렉터리 계층 구조와 연결되지 않으면 사용자가 해당 파일 시스템에 접근하 수 없기에 연결시킬 필요가 있습니다. 이에 파일 시스템 mount를 하는 것입니다.
마운트 하기 위해서는
[장치명 마운트포인트 파일시스템종류 옵션 덤프설정 파일점검옵션] 을 설정하면 됩니다.
제가 사용했던 리눅스시스템에서는 mount -t ext2 /dev/sdb1 /mnt 와 같은 명령어로 마운트를 시킬 수 있었습니다!
이후에 파일시스템 언마운트를 시키려면 umount를 하면 됩니다.
p. 400의 확인 문제 1번 풀고 인증하기 Ch.14(14-3) 프로세스가 사용할 수 있는 프레임이 3개 있고, 페이지 참조열이 '2313523423' 일 때 LRU 페이지 교체 알고리즘으로 이 페이지를 참조한다면 몇 번의 페이지 폴트가 발생하는지 풀어보기
p.400 확인문제1
Q : 메모리 할당 방식에 대한 설명으로 올바른 것을 다음 보기에서 찾아 써 보세요.
[보기] : 최초 적합, 최적 적합, 최악 적합
A :
- ( 최초 적합 ) : 최초로 발견한 적재 가능한 빈 공간에 프로세스를 배치하는 방식
- ( 최악 적합 ) : 프로세스가 적재될 수 있는 가장 큰 공간에 프로세스를 배치하는 방식
- ( 최적 적합 ) : 프로세스가 적재될 수 있는 가장 작은 공간에 프로세스를 배치하는 방식
Ch.14(14-3)
Q : 프로세스가 사용할 수 있는 프레임이 3개 있고, 페이지 참조열이 '2 3 1 3 5 2 3 4 2 3' 일 때 LRU 페이지 교체 알고리즘으로 이 페이지를 참조한다면 몇 번의 페이지 폴트가 발생하는지?
A : 3회 발생합니다.
LRU는 가장 참조되지 않은 오랜 페이지를 교체시키기 때문에 사용 가능한 프레임이 3개라면 다음의 과정을 거칠 수 있습니다.
2
23
231
231
'5' 231 -> 531
'2' 531 -> 532
532
'4' 532 -> 432
432
432
ps.
컴퓨터구조를 공부하시는데 영어원문 lecture 책을 찾으시다면 다음을 추천🙃
https://product.kyobobook.co.kr/detail/S000002261883
한국어 교재를 찾으신다면 다음을 추천드립니다. 🙂
https://www.hanbit.co.kr/store/books/look.php?p_code=B9177037040
