
01.RNN
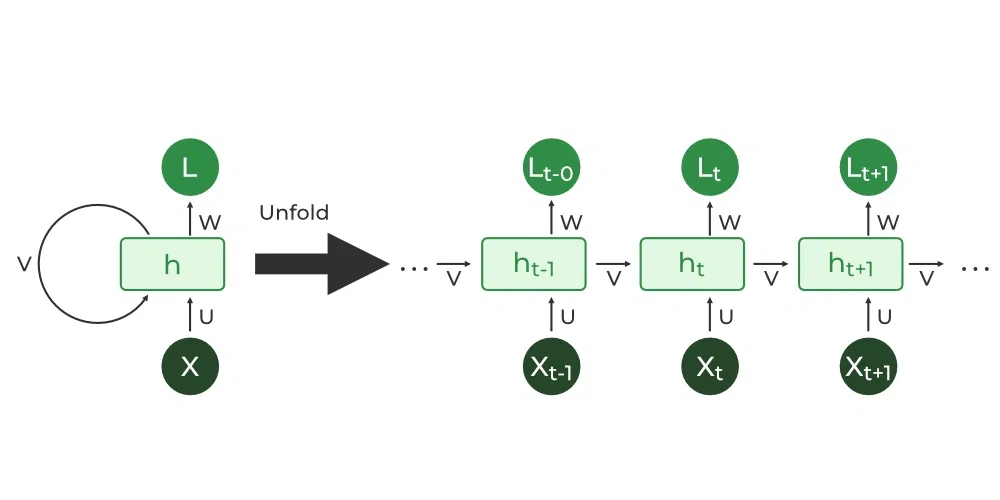
RNN(Recurrent Neural Network)이란?
: 시계열 데이터(Sequential data)를 처리하도록 고안된 모델 중 하나로 순환신경망이라고 부름
Ont to One, One to Many, Many to One, Many to Many
BPTT & Truncated BPTT
- BPTT(Backpropagation Through Time) - RNN의 역전파 알고리즘
RNN은 매 시점의 중간데이터를 메모리에 저장해야 하기 때문에 시계열 데이터의 시간크기에 비례하여 컴퓨팅자원이 증가하고 기울기가 불안해짐
-> Gradient Vanishing or Gradient Exploding 발생 - Truncated BPTT
위와 같은 문제를 해결하기 위해 시간축 방향으로 길어진 신경망을 적당한 지점에서 잘라내어 오차역전파 법 수행
단, 순전파가 아니라 "역전파"만 끊을 것
RNNLM(RNN Language Model)
: RNN 계층을 이용한 언어모델로 이전단어들과의 의존 관계를 고려하여 예측함
계층 순서 : input > embedding > RNN > Softmax > output
RNN의 문제점
Gradient Vanishing(기울기 소실) & Gradient Exploding(기울기 폭주)
1) 활성화 함수인 tanh 함수를 역전파 시키면 층이 깊어질수록 기울기값 점점 작아짐
2) Matmul 노드를 지나가는 횟수에 비례에 기울기가 폭발적으로 증가 혹은 감소
- 해결방안
- 기울기 폭주 : 기울기 클리핑(gradient clipping)
- 기울기 소실 : 장기 의존성 문제(long-term dependency) -> LSTM
02.LSTM
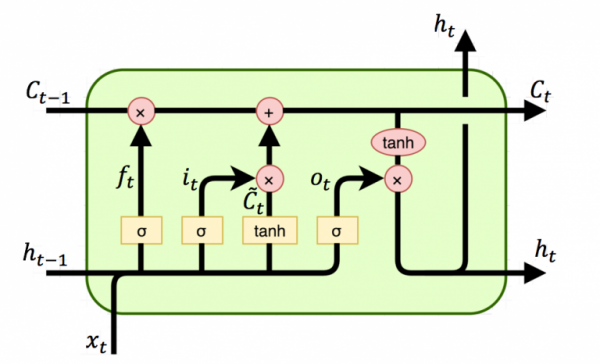
: 장기 기억과 단기기억,'잊어버림'추가를 통해 기본 RNN의 장기 의존성 문제 해결.
- LSTM의 구조
- Cell state : 장기기억을 담당하는 메모리와 같은 존재로 Cell state의 기울기를 보존하여 기올기 소실 문제 완화
- Gate : 3개의 Gate를 통해 정보를 얼마나 기억할지 제어 (어떤정보를 유지할지, 어떤정보를 버릴지 학습함)
- Forget Gate() : 과거 정보를 얼마나 잊을지
- Input Gate() : 현재 정보를 얼마나 기억할 것인지
- State Update() : 에서 로 Cell state를 갱신하는 단계
- Output Gate : 다음 state로 내보낼 hidden state를 구하는 단계
03.GRU(Grated Recurrent Unit)
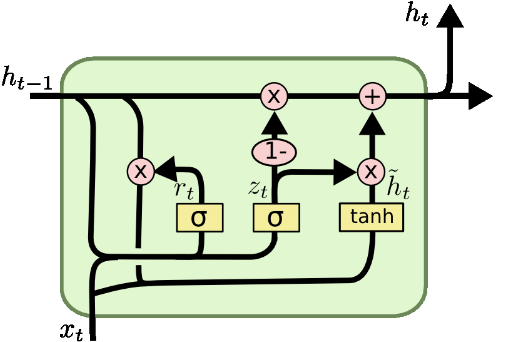
LSTM과의 차이점 : LSTM의 간소화 버전, 학습할 parameter가 적어 학습속도 빠름, Gate가 2개(Reset Gate,Update Gate)
- Reset Gate : 이전의 정보를 얼마나 반영할지 결정
- Update Gate : 새로운 입력을 얼마나 반영할지 결정
- 현제 Hidden State : Reset Gate와 Update Gate의 값을 조합하여 계산
04.Seq2Seq
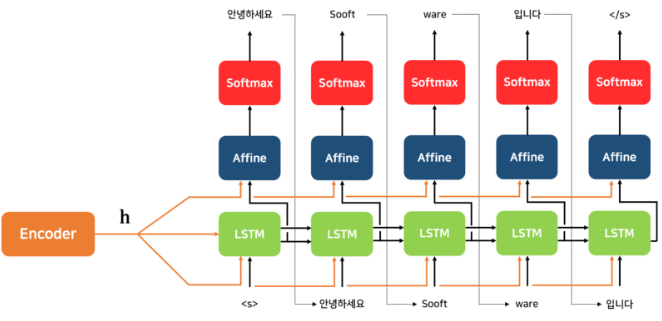
: 시계열 데이터를 다른 시계열 데이터로 변환하는 모델
- Seq2Seq의 구조
- Encoder : RNN계층을 이어둔 구조로 임의 길이의 시계열 데이터를 고정길이벡터 h로 변환함
- Decoder : RNNLM과 비슷한 구조지만 context vector를 추가로 입력받아 sequence변환함
- Seq2Seq 성능 개선 방안
- 입력 데이터 반전
- 엿보기 : Decoder가 처리할 수 있는 유일한 정보가 모두 담긴 h를 더 활용하기 위해 Decoder의 다른 계층에도 전달
- Seq2Seq 문제점
- 정보손실 문제 (고정길이벡터이므로 입력문장의 길이에 관계없이 같은 길이의 벡터에 정보를 밀어넣어야함)
- 기울기 손실
