컴퓨터가 이해하는 두 가지 정보 중 ‘문자 데이터’에 대한 학습
1. 컴퓨터에서 문자를 표현하는 방법
- 컴퓨터는 기본적으로 0과 1밖에 이해하지 못합니다.
- 그러나, 다양한 문자(영어, 한글, 이모티콘, 특수문자 등)를 표현할 수 있습니다.
- 이를 위해 문자 집합, 인코딩, 디코딩 개념이 필요합니다.
2. 문자 집합, 인코딩, 디코딩
-
문자 집합 (Character Set)
- 컴퓨터가 이해하고 표현할 수 있는 문자들의 모음입니다.
- 문자 집합에 속하지 않은 문자는 컴퓨터가 이해할 수 없습니다.
-
인코딩 (Encoding)
- 문자를 0과 1로 변환하는 과정입니다.
- 문자에 고유한 코드 포인트를 부여하고, 이를 0과 1로 변환합니다.
-
디코딩 (Decoding)
- 0과 1로 인코딩된 문자 코드를 사람이 이해할 수 있는 문자로 변환하는 과정입니다.
3. 주요 문자 집합 및 인코딩 방식
1) 아스키 코드 (ASCII)
-
영어 알파벳, 숫자, 일부 특수문자, 제어 문자 등을 표현하는 문자 집합입니다.
-
7비트로 하나의 문자를 표현하며, 총 128개의 문자를 지원합니다.
-
예시:
- 대문자
A의 아스키 코드: 65 - 소문자
a의 아스키 코드: 97
- 대문자
-
제한점: 영어 이외의 언어(예: 한글, 중국어 등)를 표현할 수 없습니다.
2) 한글 인코딩 방식
- 한글은 초성, 중성, 종성의 조합으로 이루어져 있어, 문자를 표현하는 방식이 영어와 다릅니다.
- 대표적인 한글 인코딩 방식:
- 완성형 인코딩: 자음과 모음이 조합된 완성된 글자에 고유 코드를 부여합니다.
- 조합형 인코딩: 자음과 모음 각각에 고유 코드를 부여하여 조합합니다.
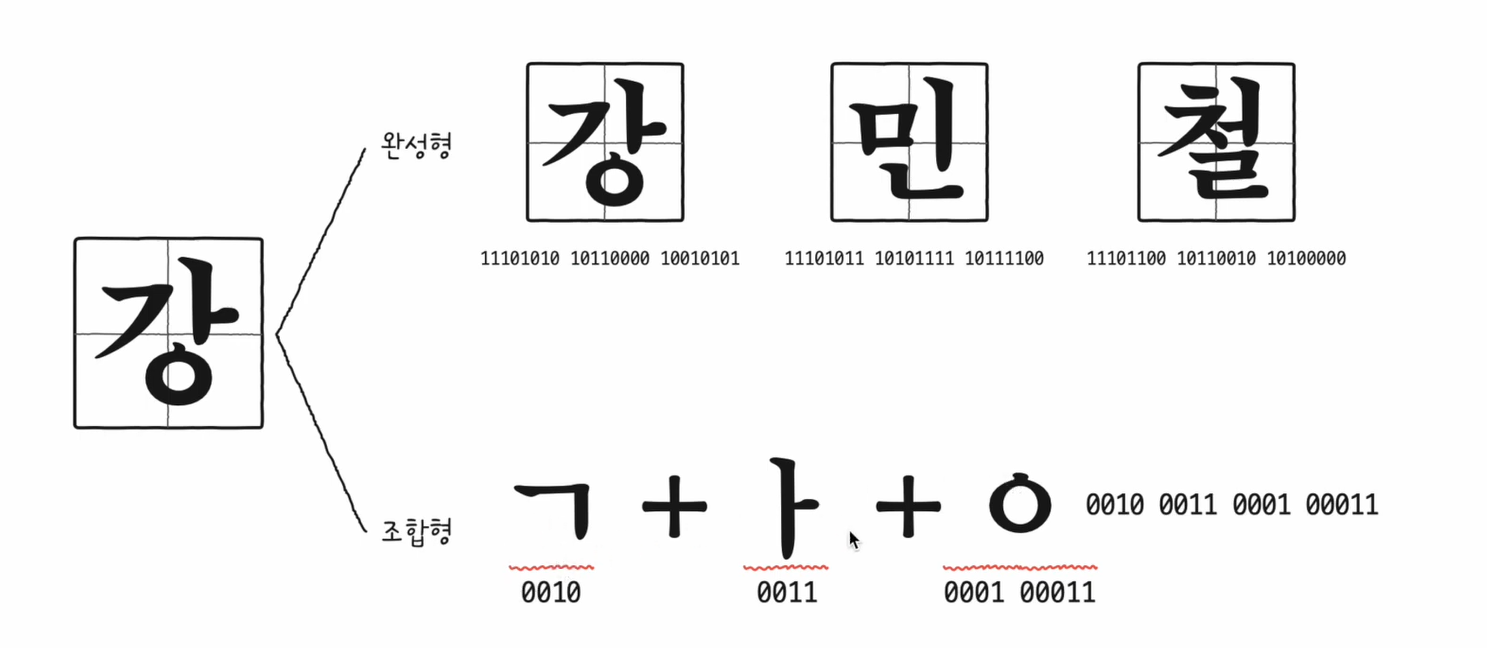
3) EUC-KR (완성형 인코딩 방식)
-
한글 문자를 표현하기 위해 개발된 인코딩 방식입니다.
-
한 글자를 표현하기 위해 2바이트(16비트)를 사용합니다.
-
예시:
가는 EUC-KR 인코딩에서 B0 A1로 표현됩니다.나는 B0 C0로 인코딩됩니다.
-
제한점: 약 2,350여 개의 한글만을 지원하여 일부 한글은 표현할 수 없습니다.
- 이로 인해 이름이 EUC-KR로 인코딩되지 않아 발생하는 문제(공공서비스 이용 불가 등)가 존재했습니다.
4) 유니코드 (Unicode)와 UTF-8 인코딩
-
유니코드: 모든 문자(한글, 영어, 특수문자, 이모티콘 등)를 통합적으로 표현하는 문자 집합입니다.
-
유니코드의 각 문자에는 고유한 코드 포인트(16진수 값)가 부여됩니다.
- 예:
- 화살표
→의 유니코드 코드 포인트: U+2192 - 한글
가의 코드 포인트: U+AC00
- 화살표
- 예:
-
UTF-8: 유니코드를 인코딩하는 대표적인 방식으로, 가변 길이 인코딩입니다.
- 문자에 따라 1바이트, 2바이트, 3바이트, 4바이트로 인코딩됩니다.
- 예시:
- 한글
가의 유니코드 코드 포인트 AC00는 UTF-8로 EAB080로 인코딩됩니다.
- 한글
4. 인코딩과 개발에서의 주의사항
- 개발 시 글자가 깨지는 현상이 발생할 수 있습니다.
- 원인: 인코딩 방식이 맞지 않거나, 문자 집합에 속하지 않은 문자를 사용한 경우.
- 해결: 올바른 문자 집합과 인코딩 방식을 확인하고 설정해야 합니다.
5. 요약
- 컴퓨터는 문자 집합, 인코딩, 디코딩을 통해 다양한 문자를 표현합니다.
- 아스키 코드는 단순하지만 제한적이며, 한글과 같은 다양한 문자는 EUC-KR, 유니코드 등을 사용하여 표현됩니다.
- 특히, 유니코드와 UTF-8은 현대의 문자 표현에서 가장 널리 사용되는 방식입니다.
👉 이해하셨다면, 인코딩과 문자 데이터에 대해 더욱 깊이 있는 프로그래밍 개발을 할 준비가 된 것입니다! 😊

Hello world