Apache Airflow 구성 요소
Apache Airflow는 다양한 구성 요소로 이루어져 있으며, 각 구성 요소는 특정 역할을 담당하여 전체 워크플로우의 작동을 지원합니다. 주요 구성 요소는 다음과 같습니다:
1. 웹 서버 (Web Server)
역할: 사용자 인터페이스를 제공합니다.
설명: Flask와 Gunicorn을 사용하여 구현되며, DAG, Task의 상태, 로그, 실행 결과 등을 시각적으로 확인할 수 있는 대시보드를 제공합니다. 사용자들은 웹 인터페이스를 통해 DAG를 모니터링하고, 수동으로 트리거하거나, 실패한 Task를 재시작할 수 있습니다.
주요 기능
- DAG 및 Task 상태 모니터링
- DAG와 Task의 상태를 실시간으로 보여줍니다. 사용자는 각 DAG와 Task의 성공, 실패, 진행 중 상태 등을 시각적으로 확인할 수 있습니다.
- 로그 확인
- 각 Task의 실행 로그를 웹 인터페이스를 통해 확인할 수 있습니다. 이를 통해 오류 발생 시 원인을 파악하고 디버깅할 수 있습니다.
- Task 실행 및 재실행
- 사용자는 웹 인터페이스에서 Task를 수동으로 트리거하거나, 실패한 Task를 재실행할 수 있습니다.
- DAG 트리거 및 비활성화
- DAG를 수동으로 트리거하거나, 특정 DAG를 활성화/비활성화할 수 있습니다.
- 워크플로우 시각화
- DAG의 구조와 Task 간의 의존성을 시각적으로 표시합니다. 이를 통해 워크플로우의 전체적인 흐름을 한눈에 파악할 수 있습니다.
기술적 구성
- Flask
- Airflow의 웹 서버는 Flask라는 파이썬 기반 웹 프레임워크를 사용하여 구현되었습니다. Flask는 경량 웹 애플리케이션 프레임워크로, 빠르고 쉽게 웹 애플리케이션을 개발할 수 있게 해줍니다.
- Gunicorn
- Gunicorn은 Flask 애플리케이션을 호스팅하는 데 사용되는 WSGI 웹 서버입니다. 이는 Airflow 웹 서버의 성능을 높이고, 동시에 여러 요청을 처리할 수 있게 합니다.
웹 서버 사용 예시
웹 인터페이스를 통해 사용자는 다음과 같은 작업을 수행할 수 있습니다:
- 특정 DAG를 선택하여 DAG의 구조와 Task 상태를 확인합니다.
- 특정 Task를 클릭하여 실행 로그를 확인합니다.
- 실패한 Task를 수동으로 재실행하거나, 특정 Task를 수동으로 트리거합니다.
- DAG를 활성화하거나 비활성화하여 스케줄링을 조정합니다.
2. 스케줄러 (Scheduler)
역할: DAG를 분석하고, 각 Task를 스케줄링합니다.
설명: DAG 파일을 주기적으로 스캔하여 새로운 DAG와 변경된 DAG를 인식합니다. 각 Task의 실행 조건을 확인하고, 실행 가능한 Task를 Worker에게 할당합니다. DAG의 실행을 관리하고, 각 Task가 정의된 순서에 따라 실행되도록 합니다.
주요 기능
- DAG 파싱 및 스케줄링
- DAG 디렉토리에서 DAG 파일을 주기적으로 스캔하여 새로운 DAG와 변경된 DAG를 인식합니다. 이를 통해 DAG의 정의와 스케줄을 확인하고 필요한 작업을 예약합니다.
- Task 트리거
- 각 DAG의 스케줄에 따라 Task를 트리거합니다. 스케줄러는 각 Task의 상태를 확인하고, 실행 조건이 충족되면 해당 Task를 실행합니다.
- 의존성 관리
- DAG에 정의된 의존성을 바탕으로 Task의 실행 순서를 관리합니다. 이전 Task가 성공적으로 완료된 후에만 다음 Task를 실행합니다.
- Worker 할당
- Task를 실행할 Worker를 할당합니다. Worker는 실제로 Task를 실행하는 컴포넌트입니다. 스케줄러는 Task가 실패할 경우 재시도 정책에 따라 Task를 재실행할 수 있습니다.
동작 방식
- DAG 스캔
- 주기적으로 DAG 디렉토리를 스캔하여 새로운 DAG 파일을 찾고, 이를 데이터베이스에 로드합니다. 이 과정에서 DAG의 구조와 스케줄을 파악합니다.
- DAG 실행 계획
- 각 DAG의 스케줄에 따라 실행 계획을 세웁니다. DAG의 스케줄은
schedule_interval파라미터로 정의됩니다. 예를 들어,@daily로 설정된 DAG는 매일 한 번 실행됩니다.
- 각 DAG의 스케줄에 따라 실행 계획을 세웁니다. DAG의 스케줄은
- Task 트리거
- 각 Task의 상태를 확인하고, 실행 조건이 충족되면 Task를 트리거합니다. 예를 들어, 이전 Task가 성공적으로 완료된 후에만 다음 Task를 실행합니다.
- Worker 할당
- 실행 가능한 Task를 적절한 Worker에게 할당합니다. Worker는 할당된 Task를 실행하고, 실행 결과를 스케줄러에게 보고합니다.
3. 워커 (Worker)
역할: 실제로 Task를 실행하는 컴포넌트입니다.
설명: 스케줄러로부터 할당받은 Task를 실행합니다. 각 Worker는 Task를 실행하고, 실행 결과를 스케줄러에게 보고합니다. Celery Executor를 사용하는 경우, 워커는 Celery를 통해 Task를 분산 처리합니다.
주요 기능
- Task 실행
- 스케줄러로부터 할당받은 Task를 실행합니다. 각 Task는 Python 코드, Bash 명령어, 데이터베이스 쿼리 등 다양한 형태일 수 있습니다.
- 결과 보고
- Task가 실행된 후, Worker는 실행 결과를 스케줄러에게 보고합니다. 성공, 실패, 재시도 등의 상태를 업데이트합니다.
- 로깅
- Task 실행 중 발생한 로그를 기록합니다. 이러한 로그는 디버깅과 모니터링에 유용하게 사용됩니다.
동작 방식
- Task 할당
- 스케줄러는 실행 가능한 Task를 Worker에게 할당합니다. 이 할당은 스케줄러와 Worker 간의 통신을 통해 이루어집니다.
- Task 실행
- Worker는 할당된 Task를 받아 실제로 실행합니다. Task는 Operator에 정의된 로직을 수행합니다.
- 결과 보고
- Task가 완료되면 그 결과를 스케줄러에게 보고합니다. 실행 결과는 메타데이터 데이터베이스에 저장됩니다.
- 재시도 및 오류 처리
- Task가 실패한 경우, Worker는 스케줄러의 재시도 정책에 따라 Task를 재실행할 수 있습니다.
4. 메타데이터 데이터베이스 (Metadata Database)
역할: Airflow의 상태와 메타데이터를 저장합니다.
설명: SQLite, MySQL, PostgreSQL 등과 같은 데이터베이스를 사용하여 DAG, Task의 상태, 실행 기록, 로그, 설정 정보 등을 저장합니다. 스케줄러와 웹 서버는 이 데이터베이스를 참조하여 현재 상태를 파악하고, 필요한 작업을 수행합니다.
주요 기능
- DAG 및 Task 상태 저장
- 모든 DAG와 Task의 상태를 저장합니다. 이는 각 Task의 실행 상태(예: 성공, 실패, 재시도)를 추적하는 데 사용됩니다.
- 실행 기록 저장
- 각 DAG와 Task의 실행 기록을 저장합니다. 이를 통해 과거 실행 내역을 확인하고, 실패한 Task를 디버깅할 수 있습니다.
- 로그 관리
- Task 실행 중 생성된 로그를 저장합니다. 이는 문제 발생 시 원인을 파악하고 해결하는 데 유용합니다.
- 설정 정보 저장
- Airflow의 다양한 설정 정보를 저장합니다. 예를 들어, 재시도 정책, 스케줄링 간격 등의 설정이 여기에 포함됩니다.
동작 방식
- 상태 업데이트
- 스케줄러와 Worker는 DAG와 Task의 상태를 주기적으로 메타데이터 데이터베이스에 업데이트합니다. 이를 통해 현재 워크플로우의 상태를 정확히 파악할 수 있습니다.
- 실행 기록 및 로그 저장
- 각 Task가 실행될 때마다 그 기록과 로그가 메타데이터 데이터베이스에 저장됩니다. 이는 웹 서버에서 사용자가 실행 내역과 로그를 확인할 수 있도록 합니다.
- 쿼리 및 분석
- 메타데이터 데이터베이스는 쿼리와 분석을 통해 워크플로우의 성능을 모니터링하고 최적화할 수 있게 합니다. 예를 들어, 특정 DAG의 실행 시간을 분석하여 병목 지점을 찾을 수 있습니다.
5. Executor
역할: Task가 어떻게 실행될지를 정의합니다.
설명: Task의 실행 방식을 정의하는 컴포넌트입니다. 여러 종류의 Executor가 있으며, 기본적으로 LocalExecutor, CeleryExecutor, KubernetesExecutor 등이 있습니다. Executor는 Task를 실행할 환경을 설정하고, Worker에게 Task를 할당합니다.
주요 기능
- Task 실행 환경 설정
- Task가 실행될 환경을 설정합니다. 예를 들어, 로컬 머신에서 실행할지, 분산 클러스터에서 실행할지를 결정합니다.
- Worker 할당
- Task를 실행할 Worker를 할당합니다. Worker는 실제로 Task를 실행하는 컴포넌트입니다.
- 실행 결과 관리
- Task의 실행 결과를 관리하고, 실행 상태를 메타데이터 데이터베이스에 업데이트합니다.
종류
-
SequentialExecutor
- 설명: 모든 Task를 순차적으로 실행합니다.
- 적용 사례: 개발 및 테스트 환경에서 사용됩니다. Task가 하나씩 실행되기 때문에 병렬 실행이 필요 없는 작은 워크플로우에 적합합니다.
python코드 복사 from airflow.executors.sequential_executor import SequentialExecutor executor = SequentialExecutor() -
LocalExecutor
- 설명: Task를 로컬 머신에서 병렬로 실행합니다.
- 적용 사례: 단일 머신에서 여러 Task를 병렬로 실행할 수 있어, 중소 규모의 워크플로우에 적합합니다.
python코드 복사 from airflow.executors.local_executor import LocalExecutor executor = LocalExecutor() -
CeleryExecutor
- 설명: Celery를 사용하여 분산 환경에서 Task를 병렬로 실행합니다. Celery는 메시지 브로커(Redis 또는 RabbitMQ)를 사용하여 작업을 관리합니다.
- 적용 사례: 대규모 워크플로우 또는 고가용성이 필요한 환경에서 사용됩니다.
python코드 복사 from airflow.executors.celery_executor import CeleryExecutor executor = CeleryExecutor() -
KubernetesExecutor
- 설명: Kubernetes 클러스터에서 각 Task를 개별 Pod로 실행합니다. 각 Pod는 독립적으로 실행되며, 클러스터의 리소스를 효율적으로 사용합니다.
- 적용 사례: 클라우드 네이티브 환경 또는 Kubernetes 클러스터를 사용하는 대규모 워크플로우에서 사용됩니다.
python코드 복사 from airflow.executors.kubernetes_executor import KubernetesExecutor executor = KubernetesExecutor()
동작 방식
- Task 할당
- 스케줄러가 실행 가능한 Task를 발견하면, 해당 Task를 Executor에게 전달합니다.
- Worker 할당
- Executor는 Task를 실행할 Worker를 할당합니다. LocalExecutor의 경우 로컬 프로세스에서 Task를 실행하고, CeleryExecutor의 경우 Celery 워커에게 Task를 전달합니다.
- Task 실행
- 할당된 Worker는 Task를 실행합니다. Task의 실행 상태와 결과는 메타데이터 데이터베이스에 기록됩니다.
- 상태 업데이트
- Executor는 Task의 실행 결과를 메타데이터 데이터베이스에 업데이트하여, 스케줄러와 웹 서버가 현재 상태를 확인할 수 있도록 합니다.
예시
다음은 Airflow에서 Executor를 설정하고 사용하는 예시입니다:
-
SequentialExecutor 설정
python코드 복사 from airflow import DAG from airflow.executors.sequential_executor import SequentialExecutor from airflow.operators.python_operator import PythonOperator from datetime import datetime, timedelta def sample_task(): print("Executing task...") default_args = { 'owner': 'airflow', 'start_date': datetime(2023, 1, 1), 'retries': 1, 'retry_delay': timedelta(minutes=5), } dag = DAG( 'example_dag', default_args=default_args, description='An example DAG using SequentialExecutor', schedule_interval='@daily', executor=SequentialExecutor() # SequentialExecutor 사용 ) t1 = PythonOperator( task_id='sample_task', python_callable=sample_task, dag=dag, ) -
CeleryExecutor 설정
python코드 복사 from airflow import DAG from airflow.executors.celery_executor import CeleryExecutor from airflow.operators.python_operator import PythonOperator from datetime import datetime, timedelta def sample_task(): print("Executing task...") default_args = { 'owner': 'airflow', 'start_date': datetime(2023, 1, 1), 'retries': 1, 'retry_delay': timedelta(minutes=5), } dag = DAG( 'example_dag', default_args=default_args, description='An example DAG using CeleryExecutor', schedule_interval='@daily', executor=CeleryExecutor() # CeleryExecutor 사용 ) t1 = PythonOperator( task_id='sample_task', python_callable=sample_task, dag=dag, )
구성 요소 간의 상호작용
- 웹 서버와 메타데이터 데이터베이스
- 웹 서버는 메타데이터 데이터베이스를 참조하여 DAG, Task의 상태를 시각적으로 표시합니다.
- 사용자는 웹 인터페이스를 통해 DAG를 모니터링하고, Task를 수동으로 트리거할 수 있습니다.
- 스케줄러와 메타데이터 데이터베이스
- 스케줄러는 메타데이터 데이터베이스를 참조하여 각 DAG의 상태를 파악하고, 실행할 Task를 결정합니다.
- 스케줄러는 DAG 파일을 주기적으로 스캔하여 새로운 DAG와 변경된 DAG를 인식하고, Task를 스케줄링합니다.
- 스케줄러와 워커
- 스케줄러는 실행 가능한 Task를 Worker에게 할당합니다.
- Worker는 할당받은 Task를 실행하고, 실행 결과를 스케줄러에게 보고합니다.
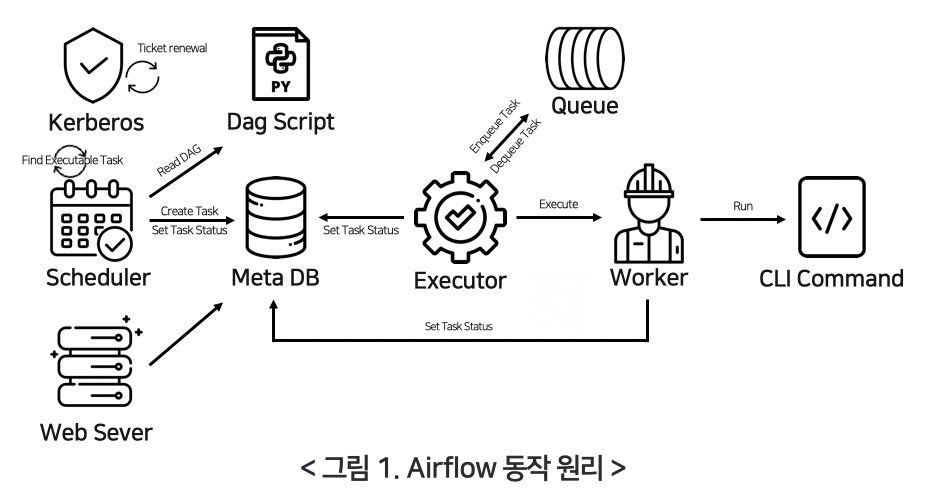
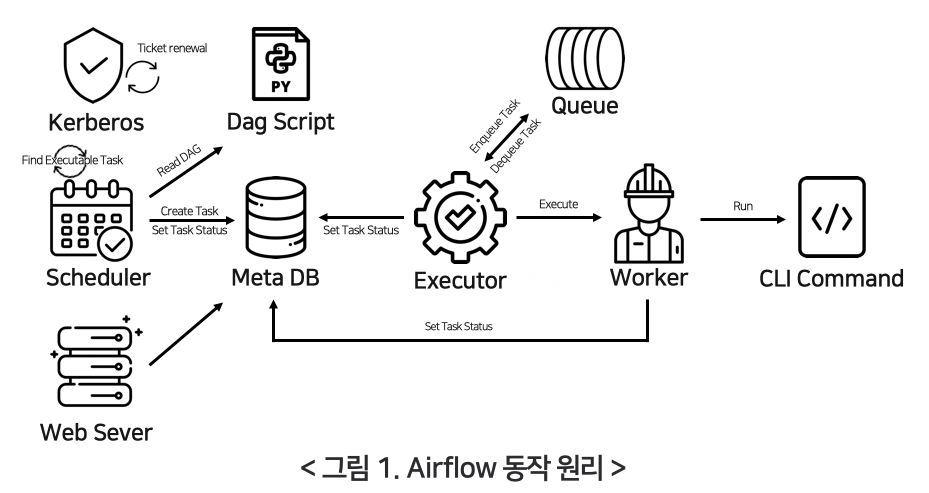
Apache Airflow 기본 동작 원리
Apache Airflow의 동작 원리는 DAG(Directed Acyclic Graph)를 중심으로 이루어집니다. 각 DAG는 워크플로우를 정의하며, 여러 Task로 구성됩니다. 아래는 Airflow의 기본 동작 원리를 단계별로 설명한 것입니다:
1. DAG 작성 및 배치
- 유저가 새로운 DAG를 작성: 유저는 Python 스크립트를 작성하여 DAG를 정의합니다. 이 스크립트에는 워크플로우의 구조와 각 Task가 포함됩니다.
- DAG 폴더에 파일 배치: 작성된 DAG 파일을 Airflow의 DAG 폴더에 배치합니다. 이 폴더는 Airflow 설정 파일에서 지정됩니다.
2. DAG 파싱
- 웹 서버와 스케줄러가 DAG 파일 파싱: 웹 서버와 스케줄러는 주기적으로 DAG 폴더를 스캔하여 새로운 DAG 파일을 파싱합니다. 이를 통해 DAG의 구조와 Task 정보를 읽어들입니다.
3. DAG 실행 준비
- 스케줄러가 Metastore를 통해 DagRun 오브젝트 생성: 스케줄러는 Metastore(메타데이터 데이터베이스)를 통해 DAG 실행 인스턴스인 DagRun 오브젝트를 생성합니다.
- DagRun 인스턴스: DagRun은 사용자가 작성한 DAG의 실행 인스턴스입니다.
- DagRun 상태: 초기 상태는
Running입니다.
- DagRun 상태: 초기 상태는
4. Task 스케줄링
- 스케줄러가 Task Instance 오브젝트 스케줄링: 스케줄러는 DAG의 각 Task를 Task Instance로 생성하고 스케줄링합니다. Task Instance는 특정 시간에 실행될 Task의 인스턴스입니다.
5. Task 실행
- 조건이 맞으면 Task Instance 실행: 스케줄러는 Task의 실행 조건이 충족되면 해당 Task Instance를 Executor로 보냅니다. 예를 들어, 이전 Task가 성공적으로 완료되면 다음 Task를 실행합니다.
- Executor가 Task Instance 실행: Executor는 Task Instance를 실제로 실행합니다. Task는 다양한 작업을 포함할 수 있습니다(예: 데이터베이스 쿼리, 파일 처리, API 호출 등).
6. 실행 결과 보고
- Task 완료 후 Metastore에 보고: Task가 완료되면 Executor는 Metastore에 실행 결과를 보고합니다. Task가 성공적으로 완료되었는지, 실패했는지 등의 정보가 포함됩니다.
- DagRun 업데이트: 완료된 Task Instance의 상태는 DagRun에 업데이트됩니다. 스케줄러는 Metastore를 통해 DagRun의 상태를 확인하고, 모든 Task가 완료되었는지 확인합니다.
7. DAG 실행 완료
- DAG 실행 완료 확인: 스케줄러는 모든 Task가 완료되었는지 확인합니다. 모든 Task가 성공적으로 완료되면 DagRun의 상태를
Completed로 변경합니다. - DagRun 상태 변경: DAG 실행이 완료되었음을 Metastore에 보고하여 DagRun의 최종 상태를 업데이트합니다.
예시 흐름도
- DAG 작성 및 배치:
- 유저 작성 ->
DAG 폴더에 배치
- 유저 작성 ->
- DAG 파싱:
웹 서버 & 스케줄러-> DAG 파일 파싱
- DAG 실행 준비:
스케줄러-> DagRun 생성 (상태: Running)
- Task 스케줄링:
스케줄러-> Task Instance 생성 및 스케줄링
- Task 실행:
- 조건 충족 시
스케줄러-> Task Instance를Executor로 전송 Executor-> Task Instance 실행
- 조건 충족 시
- 실행 결과 보고:
Executor-> Metastore에 실행 결과 보고- Task Instance 상태 업데이트 -> DagRun 업데이트
- DAG 실행 완료:
- 모든 Task 완료 확인 ->
스케줄러-> DagRun 상태 변경 (Completed) - 최종 상태 Metastore에 보고
- 모든 Task 완료 확인 ->
