Thread Pool 이란?
Thread Pool은 작업을 실행하는 데 사용할 수 있는 worker Thread의 모음이며, 효율적으로 Thread를 처리하여 전반적인 Runtime 성능을 향상시키기 위해 생겨난 Thead 제어 방법 중 하나이다.
Thread는 커널 리소스를 참조하고 있으므로 생성되거나 파괴될 때, 비용이 크게 발생하는데
주기적으로 요청되는 작업을 위해 매번 Thread를 생성하고 파괴하게 된다면 해당 동작에 대한 부담은 프로그램 전체적인 퍼포먼스를 저하시키게 된다.
이 때, Thread Pool을 통해 사용할 Thread를 미리 만들어 놓음으로써 다수의 사용자 요청을 빠르게 수용하고 처리할 수 있는 환경을 마련할 수 있다.
하지만, 그렇다고해서 Thread Pool에 너무 많은 양의 Thread를 만들어둔다면 유휴 Thread가 쓸데없이 Memory만 차지하게 되는 현상이 발생할 수 있기에 개발자는 Thread Pool에 얼마만큼의 Thread가 필요할지 현명하게 예측하고 할당하여 사용해야만 한다.
Thread Pool 기본 동작
응용 프로그램이 어떠한 작업을 실행 해야하는 경우 해당 Task를 Thread Pool에 전달만하면, 병렬 처리할 Task를 가용한 Thread에 할당하여 작업을 실행시킨다.
Thread Pool의 모든 Thread가 작업 중이면 Task가 Queue에 대기하여 Thread를 사용할 수있을 때까지 기다리고 순차적으로 Thread에 할당된다. (FIFO)
하지만, 당연히 병렬 프로그래밍 성격에따라 작업 요청 순서대로 작업 처리가 순차 완료되는 것은 아니다. --> 순차 완료를 원한다면 single thread pool을 사용하자.

그리고 Java는 Thread Pool의 구현을 위해 다음과 같이 java.util.concurrent 패키지를 통해 손 쉬운 개발 환경을 제공하고 있다.
Executors: Thread Pool과 이를 제어하기 위한 ThreadPoolExecutor의 정적 생성 메서드를 지원하는 객체
final ExecutorService executorService = Executors.newFixedThreadPool(5)
// final ExecutorService executorService = Executors.newSingleThreadExecutor();
// final ExecutorService executorService = Executors.newCachedThreadPool();ExecutorService: Task 등록뿐만 아니라 Thread Pool을 관리하고 제어하는 책임을 갖는 Interface
// 1. create
final ExecutorService executorService = Executors.newFixedThreadPool(2);
// 2. execute
for (int i = 0; i < 10; i++) {
executorService.execute(() -> System.out.println("Thread: " + Thread.currentThread().getName()));
// executorService.submit(() -> System.out.println("Thread: " + Thread.currentThread().getName()));
}
// 3. shutdown
executorService.shutdown();해당 예제 코드를 실행시켜보면, executorService가 Thread Pool에서 가용한 Thread에 Task를 배정하여 수행시키는 모습을 볼 수 있다.
> Thread: pool-2-thread-1
Thread: pool-2-thread-1
Thread: pool-2-thread-1
Thread: pool-2-thread-2
Thread: pool-2-thread-1
Thread: pool-2-thread-2
Thread: pool-2-thread-1
Thread: pool-2-thread-2
Thread: pool-2-thread-1
Thread: pool-2-thread-2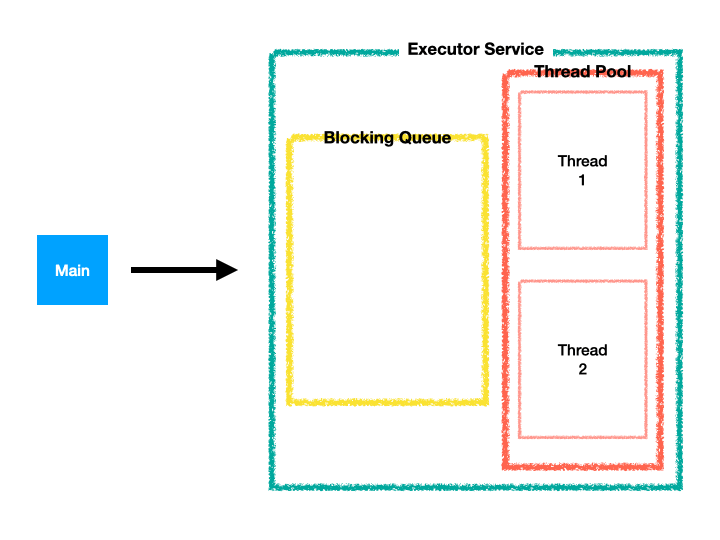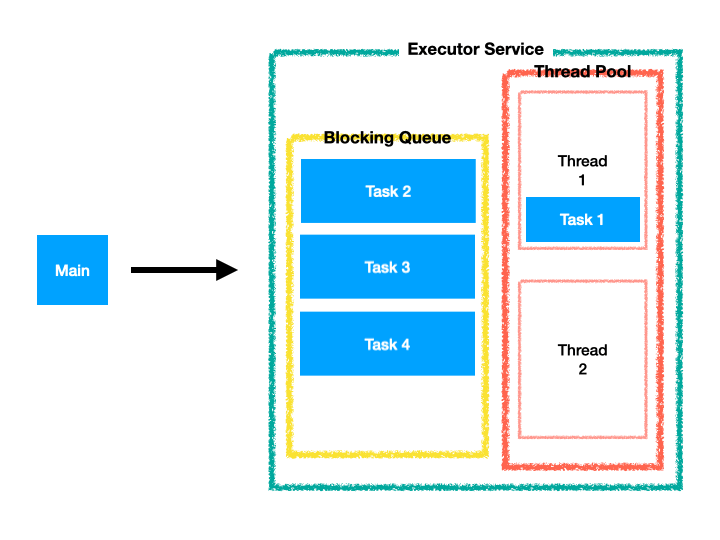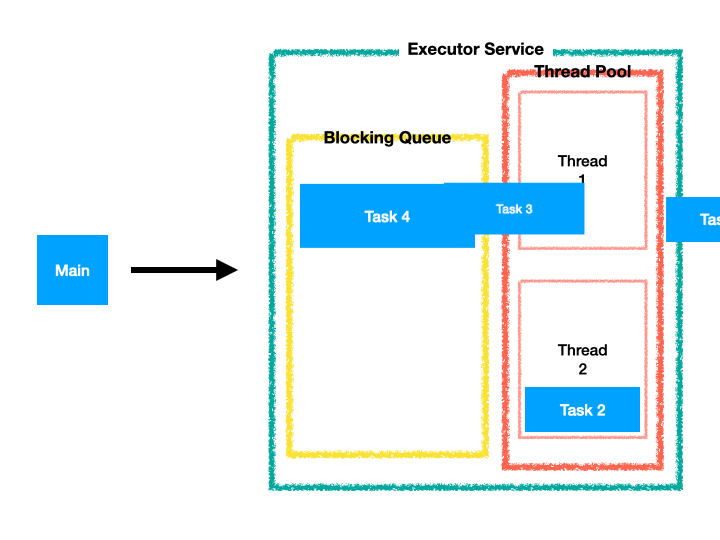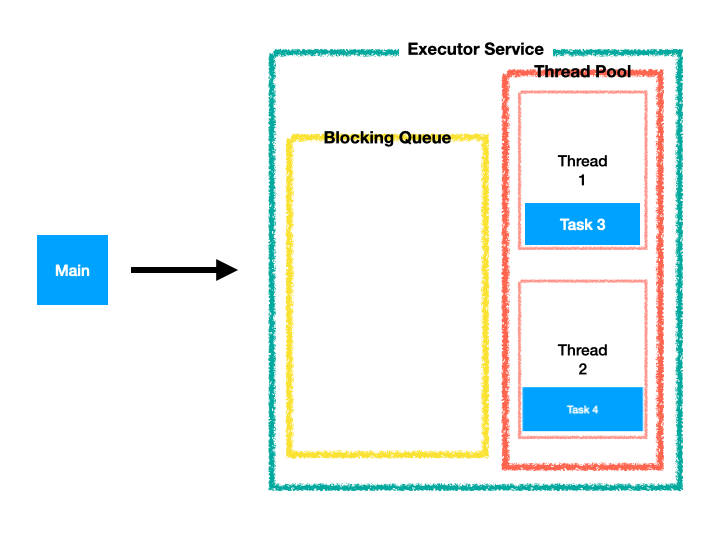
이렇게 Java에선 Thread Pool을 개발자가 보다 손 쉽게 구현하기 위한 방법들을 제공하고 있다.
하지만, 이를 실제 코드에 활용하기 위해선 내부적으로 어떻게 동작되는 것인지 보다 깊이 알 필요가 있다!
1. Thread Pool 생성 및 내부 Mechanism
앞서 본 예제와 같이 Executors에서 제공하는 정적 메소드를 사용하여 편리하게 Thread Pool을 생성할 수 있으며
응용 프로그램의 사용성에 맞춰 개발자가 직접 Thread Pool을 생성할 수 있다.
Java Thread Pool에서 다뤄지는 공통 개념은 다음과 같은데
- coreThreadSize : ExecutorService 객체가 생성될 때 생성되는 Thread size이자 최소한으로 유지되는 Thread size
- maxThreadSize : Thread Pool에서 관리하는 최대 Thread size
- keepAliveTime : Thread 미사용 시 제거되기까지의 대기 시간
- workQueue : 요청된 Task들이 실행 가능한 Thread Pool이 없을 경우 Task가 대기하는 공간
이러한 공통 개념을 토대로 개발자가 어떻게 Thread Pool을 직접 생성할 수 있는지 먼저 알아보도록 하자.
ThreadPoolExecutor
개발자는 ThreadPoolExecutor의 생성자를 이용하여 사용성에 맞춘 Thread Pool을 직접 생성할 수 있다.
ThreadPoolExecutor의 생성자는 총 4가지가 존재하며 가장 대표적인 생성자는 아래와 같다.
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}
final ThreadPoolExecutor executorService = new ThreadPoolExecutor(1, 3 , 3, TimeUnit.SECONDS, new LinkedBlockingQueue<>(9));
해당 생성자를 통해 개발자는 운용할 core/max thread의 갯수를 직접 지정할 수 있고 유휴 Thread 파괴를 위한 keepAliveTime 및 TimeUnit을 설정할 수 있다. 하지만, 여기에서 한 가지 반드시 알아야 할 것은 workQueue에 대한 Thread Pool 동작 방식이다.
앞선 ThreadPoolExecutor에선 생성자의 인자로 core thread와 max thread 갯수를 받았다.
개발자가 core thread를 3개로 max thread를 5개로 지정하여 ThreadPoolExecutor를 생성했다고 가정할 때, 10개의 Task가 연속해서 들어올 경우 과연 몇개의 thread가 동작할 것이라 예상할 수 있을까?
단편적인 생각으론 당연히 5개의 thread가 동작한다라고 생각할 수 있다. 왜냐하면 max thread 갯수를 5개로 설정했기 때문이다.
하지만, workQueue 동작 방식은 위와 같은 단편적인 생각에 살짝(?) 벗어난다.
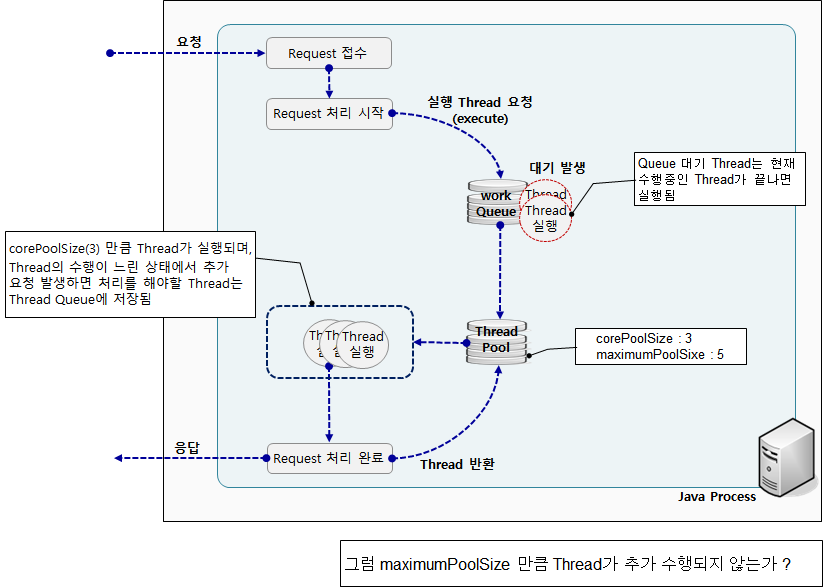
ThreadPoolExecutor는 기본적으로 corePoolSize만큼의 Thread만 수행하며 추가적인 Task는 workQueue에 Queuing이 된다. 그리고 이 해당 Queue가 지정한 size만큼 다 차면 그제서야 maxThreadPoolSize 옵션이 적용되어 추가적인 Thread가 생성되어 Task가 수행된다.
final ThreadPoolExecutor executorService = new ThreadPoolExecutor(
/*coreThreadPoolSize*/3,
/*maxThreadPoolSize*/5,
/*keepAliveTime*/3,
TimeUnit.SECONDS,
new LinkedBlockingQueue<>(9)); // workQueue의 size는 9즉, 위와 같이 core thread size가 3, workQueue size가 9 라고 가정하면 연속적인 Task가 13개 와야만 추가적인 Thread가 할당되며, 해당 Thread는 Task를 수행하고 지정한 keepAliveTime인 3초 후에 파괴된다.
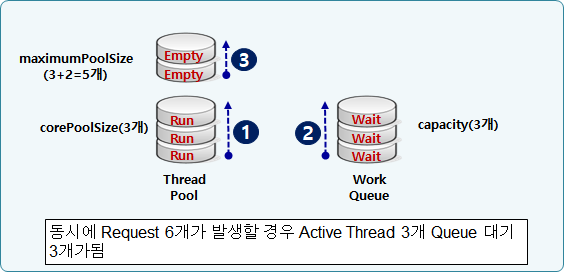
그리고 max thread 갯수와 workQueue size 를 넘어선 Task가 추가적으로 올 경우엔 다음과 같은 RejectedExecutionException 이 발생하게 된다.
Exception in thread "main" java.util.concurrent.RejectedExecutionException: Task Example$Task@50040f0c rejected from java.util.concurrent.ThreadPoolExecutor@2dda6444[Running, pool size = 5, active threads = 5, queued tasks = 9, completed tasks = 0]
at java.util.concurrent.ThreadPoolExecutor$AbortPolicy.rejectedExecution(ThreadPoolExecutor.java:2063)
at java.util.concurrent.ThreadPoolExecutor.reject(ThreadPoolExecutor.java:830)
at java.util.concurrent.ThreadPoolExecutor.execute(ThreadPoolExecutor.java:1379)
이러한 RejectedExecutionException 정책은 ThreadPoolExecutor 의 또 다른 생성자를 통해 exception을 handling 할 수 있다.
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
RejectedExecutionHandler handler) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), handler);
}- ThreadPoolExecutor.AbortPolicy
Default policy이며 execption을 발생시킨다. - ThreadPoolExecutor.CallerRunsPolicy
호출한 Thread에서 reject된 task를 대신 실행한다. - ThreadPoolExecutor.DiscardPolicy
Reject된 task는 버려진다. Exception도 발생하지 않는다. (Task 유실 O) - ThreadPoolExecutor.DiscardOldestPolicy
가장 오래 처리되지 않은 요청을 삭제하고 다시 시도한다. (Task 유실 O)
물론, 이러한 RejectedExecutionException 을 발생시키지 않기 위해
workQueue에 대해 다음과 같이 LinkedBlockingQueue의 기본 생성자를 이용해 Integer.MAX_VALUE 크기의 capacity를 갖게 할 수 있지만.... 이런 경우엔 maxThreadPoolSize를 고려한 Thread 운용은 의미가 없게 된다ㅎ
public LinkedBlockingQueue() {
this(Integer.MAX_VALUE);
}
public LinkedBlockingQueue(int capacity) {
this.capacity = capacity;
last = head = new Node<E>(null);
}final ThreadPoolExecutor executorService = new ThreadPoolExecutor(1, 3 , 3, TimeUnit.SECONDS, new LinkedBlockingQueue<>());이렇게 응용 프로그램의 특성에 따라 적절한 thread 갯수 및 keepAlive 설정이 필요하다는 것을 알게되었다.
크기가 제한된 Queue를 사용하면 자원 사용량을 한정시킬 수 있지만 Queue가 가득 찼을 때 새로운 Task가 등록되는 상황또한 고려해야 한다. 즉, Queue의 크기를 제한한 상태에서는 큐의 크기와 Thread의 갯수를 동시에 튜닝해야만 한다.
2. Java에서 지원하는Executors static factory method
사용자 정의 ThreadPoolExecutor와는 별개로 java에서 지원하는 Executors는 개발자 편의를 위해 ThreadPoolExecutor를 생성하는 정적 메소드를 다음과 같이 지원하고 있다.
(a) newSingleThreadExecutor
core/max thread 수는 1개로 고정한 후, keepAliveTime을 0ms로 두어 고정적으로 한개의 Thread를 운용
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService (
new ThreadPoolExecutor(
/*corePoolSize*/1,
/*maxPoolSize*/1,
/*keepAliveTime*/0L,
TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>())
);
}- newSingleThreadExecutor 활용 예
- 순차적으로 실행되어야 하는 작업
- UI Event 처리
- DB query
- 공유 리소스에 대한 접근이 동기화되어야 하는 경우
- File 일관성을 위한 File I/O
- Data 무결성을 위한 네트워크 통신
- 순차적으로 실행되어야 하는 작업
(b) newFixedThreadPool
core/max thread 수는 인자로 들어온 thread 수로 고정한 후, keepAliveTime을 0ms로 두어 고정 갯수의 Thread를 운용
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>());
}- newFixedThreadPool 활용 예
- 동시에 병렬적으로 수행되는 Task량이 비교적 일정할 경우
- 이미지 or 동영상 처리 작업 : section 별로 압축/필터 적용
- 동일한 계산식을 수행하는 작업
- 데이터 전송/다운로드
- Thread 개수를 제한하여 시스템 자원을 효율적으로 사용해야 하는 경우
- Server 부하 방지를 위해 Thread 갯수를 제한하여 Client 요청을 처리
- 동시에 병렬적으로 수행되는 Task량이 비교적 일정할 경우
(c) newCachedThreadPool
- core thread 수는 0, max thread 수는 Integer.MAX_VALUE 로 고정한 후, keepAliveTime을 60s로 두어 유동적인 Thread를 운용
- 최소 Thread의 수는 0이었다가 추가 요청에 따라 Thread Pool의 Thread 갯수가 증가한다.
- 단시간에 Thread 수가 폭발적으로 증가할 수 있는 위험이 있기에 짧게 많이 요청되는 Task를 운용할 때 사용.
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>());
}- newCachedThreadPool 활용 예
- 동시 요청 처리
- 웹 서버 / 네트워크 서비스
- 작업량을 예측할 수 없는 경우
- 동시 요청 처리
(d) newScheduledThreadPool
- 고정된 크기의 Thread Pool을 생성하고 Thread를 예약된 시간에 일정한 시간 간격으로 작업을 수행하도록 스케줄링하는 Thread Pool.
- 일정 시간마다 혹은 주기적으로 반복해야 하는 Task에 대한 병렬 작업을 위해 사용
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}
public class ScheduledThreadPoolExecutor extends ThreadPoolExecutor implements ScheduledExecutorService {
private static final long DEFAULT_KEEPALIVE_MILLIS = 10L;
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, DEFAULT_KEEPALIVE_MILLIS, MILLISECONDS, new DelayedWorkQueue());
}
// 1. delay runnable execute (작업을 일정 시간 뒤에 수행 - 결과 반환 x)
public ScheduledFuture<?> schedule(Runnable command, long delay, TimeUnit unit) {
...
}
// 2. delay callable execute (작업을 일정 시간 뒤에 수행 - 결과 반환 o)
public <V> ScheduledFuture<V> schedule(Callable<V> callable, long delay, TimeUnit unit) {
...
}
// 3. delay + periodic execute (작업을 일정 시간 간격으로 반복적 실행)
public ScheduledFuture<?> scheduleAtFixedRate(Runnable command, long initialDelay, long period, TimeUnit unit) {
...
}
// 4. delay + periodic execute (작업이 완료되면 일정 시간 간격 뒤에 반복적 실행)
public ScheduledFuture<?> scheduleWithFixedDelay(Runnable command,
long initialDelay,
long delay,
TimeUnit unit) {
...
}
}- newScheduledThreadPool 활용 예
- 주기적으로 Background 작업을 실행하는 경우
- Log file back-up
- 작업 수행 시간에 대한 정확성과 일관성을 유지해야 하는 경우
- Time-out task
- 주기적으로 Background 작업을 실행하는 경우
(e) ForkJoinPool
동일한 작업 내용을 가지고 있지만 각기 다른 weight을 가진 Task로 인해 Thread 별 유휴타임이 발생할 수 있다.
ex) a, b, c 3개의 폴더에 속한 .mp4 확장자 파일을 검색하기
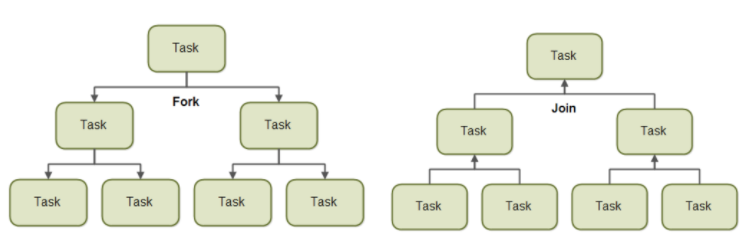
이와 같은 경우를 위해 Java7 concurrent package에서 분할 정복 알고리즘을 토대로 Task를 세부적으로 분할(Fork)하고 최종으로 합치는(Join) 하는 ForkJoinPool 이라는 Thread Pool을 지원하고 있다.
하지만, ForkJoinPool 에 대한 설명은 쓰레드풀 과 ForkJoinPool 블로그에서 너무 잘 설명되어있기에 본 Posting에선 설명하지 않으려한다 :)
지금까지 Thread Pool을 생성하는 방법에 대해 살펴봤다. 다음으론 이렇게 생성된 Thread Pool에 어떻게 Task를 요청해야 하는지 알아보도록 하자.
3. Thread Pool 실행
Thread Pool에게 작업을 요청 하기 위해선 execute(), submit() 2가지 method를 사용하면 된다.
3-1) execute(Runnable runnable)
- 작업 처리 결과를 반환하지 않는다.
- 작업 처리 도중 예외가 발생하면 Theread가 종료되고 해당 Theread는 Theread Pool에서 제거된다.
즉, 예외가 발생하여 Thread가 종료된 경우, 다른 작업을 처리하기 위해 새로운 Thread를 생성한다. Runnable만 인자로 받기때문에 작업이 완료되는 것을 기다리지 않고 다른 작업을 계속해서 추가할 수 있다.
3-2) submit(Runnable runnable), submit(Callable callable)
Runnable을 인자로 주어execute()와 같은 사용성을 가질 수 있다.Future를 통해 작업 처리 결과를 반환한다.Future를 통해 Task의 state를 파악하고 제어할 수 있다.- 작업 처리 도중 예외가 발생하더라도 Thread는 종료되지 않고 다음 작업을 위해 재사용된다.
이와 같은 특성으로
- Task 수행에 대한 정보를 알기 위해
- Thread의 생성 오버헤드를 방지하기 위해
Thread Pool 이용시 submit()을 보편적으로 이용하고 있다.
sample code
@Test
public void ExecutorService_Submit_Test() {
final ExecutorService executorService = Executors.newFixedThreadPool(5);
try {
// 1. submit runnable task
// Runnable을 인자로 준 submit 수행에 대한 결과로 null을 반환한다.
final Future<?> future1 = executorService.submit(new Runnable() {
@Override
public void run() {
System.out.println("submit runnable task");
}
});
assertFalse(future1.isDone());
assertNull(future1.get());
// 2. submit callable task
// get()을 통해 task 수행 결과를 받아온다 (Blocking)
final Future<String> future2 = executorService.submit(new Callable<String>() {
@Override
public String call() {
return "submit callable task";
}
});
assertEquals("submit callable task", future2.get());
assertTrue(future2.isDone());
// 3. submit callable task and cancel
// Future의 cancel을 통해 Task의 state를 제어할 수 있다.
final Future<String> future3 = executorService.submit(new Callable<String>() {
@Override
public String call() throws InterruptedException {
Thread.sleep(1000);
return "submit callable task and cancel";
}
});
future3.cancel(true);
assertTrue(future3.isCancelled());
assertTrue(future3.isDone());
assertThrows(CancellationException.class, () -> future3.get());
} catch (ExecutionException | InterruptedException e) {
// ignore
}
executorService.shutdown();
}4. Thread Pool 종료
이렇게 생성하고 이용한 Thread Pool을 종료하지 않고 방치하다간 pending된 Memory가 존재하게 된다.
따라서, 사용성이 완전히 완료된 이후엔 Thread Pool을 반드시 종료해줘야만 한다.
Thread Pool의 Life cycle 확인을 위한 method는 다음과 같다.
ExecutorService는 Executor의 상태 확인과 작업 종료 등 라이프사이클 관리를 위한 메소드들을 제공하고 있다.
shutdown()
- 현재 처리 중인 작업을 완료한 후에 Thread Pool을 종료한다.
shutdown()이 호출되면 더 이상 새로운 작업을 받지 않고 workQueue에 대기 중인 모든 작업을 처리한 후에 Thread Pool이 종료된다. 즉, 완전한 종료까지 일정 시간이 소요될 수 있다.
shutdownNow()
- 현재 처리 중인 작업과
workQueue에 대기 중인 모든 작업을 취소하고, Thread Pool을 종료한다. shutdownNow()가 호출되면 실행 중인 모든 작업은 인터럽트되고, workQueue에서 대기 중인 작업은 모두 취소된다.- 실행을 위해 대기중이었던 작업 목록 List를 반환한다.
isShutdown()
- ExecutorService가 shutdown() 또는 shutdownNow()를 호출 됨으로써
더 이상 새로운 작업을 수락하지 않고 작업 대기열을 처리 중인지의 여부를 반환한다.
terminate()
- 현재 처리 중인 작업과 workQueue에서 대기 중인 작업을 모두 즉시 종료시킨다.
- Thread Pool을 강제 종료시키는 경우에 사용된다.
isTerminated()
- ExecutorService가 완전히 종료되어 더 이상 실행 중인 작업이 없는지 여부를 반환한다.
awaitTermination(long timeout, TimeUnit unit)
shutdown()실행 후, 지정한 시간 동안 모든 작업이 종료될 때 까지 대기한다.
즉, 지정한 시간 내에 모든 작업이 종료되었는지 여부를 반환한다.
sample code
// 1. 더 이상 새로운 작업을 받지 않고, 작업 큐에 대기 중인 모든 작업을 처리한 후 종료한다.
executor.shutdown();
try {
// 2. 10초 동안 모든 작업이 완료되길 기다린다.
if (!executor.awaitTermination(10, TimeUnit.SECONDS)) {
// 3. 10초 동안 모든 작업이 끝나지 않은 경우, 모든 작업을 취소하고 Thread Pool을 강제 종료한다.
executor.shutdownNow();
}
} catch (InterruptedException e) {
// InterruptedException 발생 시, 작업 취소하고 Thread Pool을 강제 종료한다.
executor.shutdownNow();
}