SQL튜닝
1.[SQL 튜닝] 1장.SQL 튜닝 개요

개발/운영 중인 시스템이 점점 커지기도 하고, 사용자들의 눈높이도 높아져서 빠른 속도에 대한 니즈가 계속해서 증가하고 있다. 작년에 프로젝트를 진행하며 속도를 개선할 수 있는 다양한 방법(어플리케이션 아키텍처 변경, 프로세스 간소화, SQL 튜닝)을 고민하고 적용했다.
2.SQL튜닝 - 인덱스 튜닝

인덱스 스캔의 효용성에 대해 자세히 알아본다인덱스 풀 스캔(Index Full Sacn)과 인덱스 패스트 풀 스캔(Index Fast Full Scan)의 장단점 및 사용 방법에 대해 자세히 알아본다인덱스 스캔보다 테이블 풀 스캔(Table Full Scan)이 유리한
3.SQL튜닝 - 실행계획 제어
Optimizer가 항상 최적의 실행계획(Execution Plan)을 생성하지는 않음CBO가 주어진 쿼리에 대해서 최적의 Plan을 생성하는데 도움을 제공하는 키워드(훈수)SQL개발자가 액세스되는 User Data에 대해서 Optimizer보다 더 잘 안다고 가정Hi
4.SQL튜닝 - Nested Loop Join
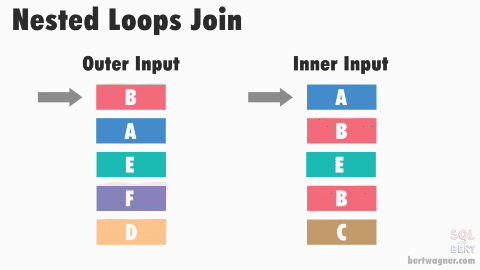
SQL은 어떤 테이블이 먼저 액세스 되든 결과는 동일A.FLD1 = '10' 조건은 통계정보에 의한 변별력 판단이 가능B.FLD2 LIKE 'A%' 조건은 통계정보에 의한 변별력 판단이 불가어느 테이블을 먼저 액세스 해야 하는가?액세스 순서에 따라 전체 일량이 달라짐일
5.SQL튜닝 - Sort Merge Join
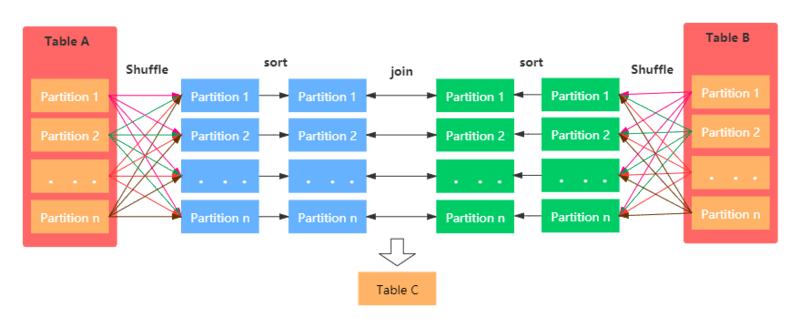
조인하고자 하는 두 테이블의 행들을 조인 조건 컬럼 기준으로 정렬한 후 Merge하여 매치조인 조건 컬럼이 정렬되어 있다면 검색 속도 향상에 도움조인 조건 컬럼에 인덱스가 없거나, 출력해야 할텍스트 결과 값이 많을 때 사용인덱스가 있으면 좋지만, 없어도 된다두 테이블의
6.SQL튜닝 - Hash Join
Build Input = Driving TableProbe Input = Driven Table둘 중 작은 집합(Build Input)을 읽어 해시 영역에 해시 테이블(=해시 맵) 을 생성하고, 반대쪽 큰 집합(Probe Input)을 읽어 해시 테이블을 탐색하면서 조
7.SQL튜닝 - 조인 튜닝
Driving table = Outer table = 선행 테이블Driven table = Inner table = 후행 테이블Nested Loop Join (중첩 루프 조인)Hash Join (해시 조인)Sort Merge Join (소트 머지 조인)소트 머지 조인은