
Redis는 Remote Dictionary Server의 약자로, 데이터를 메모리에 저장하는 인메모리 데이터베이스이다. 빠른 성능과 키-밸류(key-value) 데이터 구조에 기반한 다양한 형태의 자료 구조를 제공하며, 캐시, 세션 관리, 실시간 데이터 분석 등 다양한 용도로 사용된다. 단순한 데이터 저장소를 넘어 메시지 브로커 및 분산 시스템 구현에도 적합하다. 저장된 데이터를 영구적으로 디스크에 저장할 수 있는 백업 기능을 제공하므로 애플리케이션의 주 저장소로도 사용할 수 있다. 또한 메모리에 데이터를 저장하기 때문에 빠른 처리 속도가 장점이다.
1. Redis의 주요 특징
1.1 데이터 백업 방식
메모리에 데이터를 관리하므로 매우 빠른 속도로 데이터를 저장 및 조회할 수 있다. 하지만 메모리 특성상 저장된 데이터는 사라질(휘발성) 가능성이 있다. 이를 보완하고자 레디스는 관리하고 있는 데이터에 영속성을 제공한다.
Redis는 두 가지 방식으로 데이터를 백업한다:
- RDB (Redis DataBase): 특정 시점의 데이터를 스냅샷으로 저장한다. 주기적으로 데이터를 디스크에 저장하며 복구 속도가 빠르다.
- AOF (Append Only File): 모든 쓰기 연산을 로그로 기록한다. 데이터의 지속성이 더 강력하지만 디스크 사용량이 늘어날 수 있다.
- 데이터를 생성, 수정, 삭제하는 이벤트를 초 단위로 취합 및 로그 파일에 작성
- 모든 데이터의 변경 기록들을 보관하고 있으므로 최신 데이터 정보를 백업 가능
- RDB 방식에 비해 데이터 유실량이 적음(초 단위 데이터는 유실 가능).
- RDB 방식보다 로딩 속도가 느리고 와 파일 크기가 큰 것이 단점
설정 예시 (redis.conf)
# RDB 스냅샷 설정 save 60 10000 # 60초마다 10,000개 변경 시 저장 # AOF 설정 appendonly yes appendfilename "appendonly.aof"
1.2 싱글 스레드
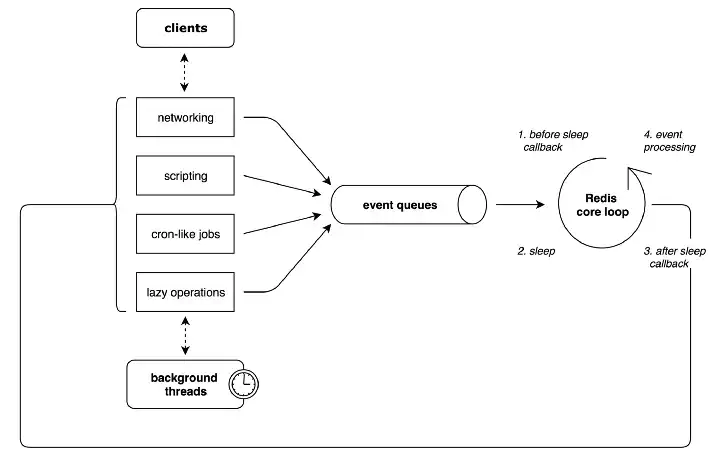
출처 : https://medium.com/fluence-network/porting-redis-to-webassembly-with-clang-wasi-af99b264ca8
레디스는 사용자들이 실행한 명령어들을 이벤트 루프(event loop) 방식으로 처리한다. 즉, 클라이언트가 실행한 명령어들을 Event Queue에 적재하고 싱글 스레드로 하나씩 처리한다. 메모리를 사용하기 때문에 싱글 스레드로 데이터를 빠르게 처리할 수 있다. 내부적으로 비동기 I/O를 활용하여 높은 성능을 유지하며, 데이터 일관성을 보장한다. 단일 스레드 구조로 인해 레이스 컨디션과 같은 동시성 문제를 최소화한다.
1.3 주요 사용 용도
Redis는 다양한 용도로 활용된다:
- 캐싱: 빠른 데이터 액세스를 위해 사용.
- 세션 관리: 웹 애플리케이션에서 유저 세션 저장.
- 메시지 브로커: Pub/Sub 기능을 통해 실시간 메시지 전달.
- 실시간 데이터 처리: 순위표, 실시간 분석 등에 사용.
1.4 아키텍처
Redis는 클라이언트-서버 모델로 동작하며, 요청-응답 구조를 따른다. 기본적으로 싱글 노드로 동작하지만 복제(Replication), 샤딩(Sharding), 클러스터링(Clustering)을 통해 확장 가능하다.
Redis 아키텍처 3가지
Redis는 다양한 아키텍처 패턴을 통해 확장성과 가용성을 보장할 수 있다. 각각의 아키텍처는 사용자의 요구사항에 따라 적합한 방식으로 선택된다.
1. 싱글 인스턴스 아키텍처
싱글 인스턴스 아키텍처는 Redis의 기본 구조로, 단일 서버에서 모든 데이터를 처리하고 저장하는 방식이다. 설정과 운영이 간단하지만, 단일 장애 지점(SPOF, Single Point of Failure)이 발생할 수 있다.
따라서 테스트 환경 또는 간단한 애플리케이션에서 주로 사용된다.
특징
- 단순한 설정.
- 단일 서버에 의존.
- 고가용성 보장이 어렵다.
2. 마스터-슬레이브 복제 아키텍처
마스터-슬레이브 복제는 하나의 마스터 노드와 여러 개의 슬레이브 노드로 구성된다. 마스터 노드는 쓰기 작업을 처리하고, 슬레이브 노드는 읽기 작업을 분산 처리한다.
슬레이브 노드는 마스터의 데이터를 지속적으로 복제하여 장애 시 데이터를 복구할 수 있다.
특징
- 읽기 성능 향상 (슬레이브를 통해 읽기 작업 분산).
- 기본적인 데이터 복구 가능.
- 쓰기 성능은 마스터 노드에 의존.
예시 (redis-cli 명령어)
# 슬레이브 노드에서 복제 설정 SLAVEOF <master-host> <master-port>
읽기 작업 확인
GET key
---
#### 3. Redis 클러스터 아키텍처
Redis 클러스터는 데이터 샤딩(Sharding)을 통해 여러 노드에 데이터를 분산 저장하는 구조이다. 각 노드는 슬롯(Slot)이라는 범위를 담당하며, 데이터의 일부분만 관리한다.
높은 확장성과 가용성을 보장하며, 대규모 애플리케이션에서 주로 사용된다.
> **특징**
- 데이터 분산 저장으로 확장성이 뛰어나다.
- 마스터-슬레이브 구조를 포함하여 가용성을 높인다.
- 네트워크 복잡성이 증가한다.
> **슬롯 분배 예시**
```bash
# 클러스터 초기화
redis-cli --cluster create 192.168.0.1:7000 192.168.0.2:7000 192.168.0.3:7000 --cluster-replicas 1아키텍처 비교
| 아키텍처 | 장점 | 단점 |
|---|---|---|
| 싱글 인스턴스 | 설정 간단, 테스트 환경 적합 | SPOF 발생 가능성, 확장 어려움 |
| 마스터-슬레이브 복제 | 읽기 성능 향상, 데이터 복구 가능 | 쓰기 성능 병목 가능성 |
| Redis 클러스터 | 높은 확장성, 고가용성 | 설정 복잡, 네트워크 복잡성 |
선택 기준
- 테스트 환경: 싱글 인스턴스.
- 읽기 성능이 중요한 환경: 마스터-슬레이브 복제.
- 대규모 트래픽 및 데이터 분산: Redis 클러스터.
1.5 지원 자료구조
Redis는 다양한 데이터 타입을 제공한다:
- String: 단순한 문자열.
- List: 순서가 있는 값의 리스트.
- Set: 중복을 허용하지 않는 값의 집합.
- Hash: 필드-값 쌍으로 구성된 맵.
- Sorted Set: 점수와 함께 정렬된 집합.
예시
# String SET key "value" GET key # List RPUSH mylist "a" "b" "c" LRANGE mylist 0 -1 # Set SADD myset "a" "b" "c" SMEMBERS myset # Hash HSET user:1 name "John" age 30 HGETALL user:1 # Sorted Set ZADD rankings 10 "Player1" 20 "Player2" ZRANGE rankings 0 -1 WITHSCORES
1.6 유효기간 (TTL)
Redis는 키에 만료 시간을 설정할 수 있다. 이는 캐시와 같은 상황에서 유용하다.
예시
# 키 생성과 만료 설정 SET session:user:12345 "active" EXPIRE session:user:12345 3600 # 1시간 동안 유효 # 남은 TTL 확인 TTL session:user:12345
2. Redis 사용 방법
Redis는 다양한 언어에서 클라이언트를 통해 사용할 수 있다. 아래는 Spring Boot에서 Redis를 사용하는 예시이다.
2.1 Gradle 의존성 추가
implementation 'org.springframework.boot:spring-boot-starter-data-redis'2.2 application.properties 설정
spring.redis.host=localhost
spring.redis.port=6379
spring.redis.password=2.3 RedisTemplate Bean 설정
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.lettuce.LettuceConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.StringRedisSerializer;
@Configuration
public class RedisConfig {
@Bean
public LettuceConnectionFactory redisConnectionFactory() {
return new LettuceConnectionFactory();
}
@Bean
public RedisTemplate<String, Object> redisTemplate() {
RedisTemplate<String, Object> template = new RedisTemplate<>();
template.setConnectionFactory(redisConnectionFactory());
template.setKeySerializer(new StringRedisSerializer());
template.setValueSerializer(new StringRedisSerializer());
return template;
}
}2.4 Redis 데이터 처리 코드
import lombok.RequiredArgsConstructor;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Service;
import java.util.concurrent.TimeUnit;
@Service
@RequiredArgsConstructor
public class RedisService {
private final RedisTemplate<String, Object> redisTemplate;
public void setValue(String key, String value, long timeout) {
redisTemplate.opsForValue().set(key, value, timeout, TimeUnit.SECONDS);
}
public String getValue(String key) {
return (String) redisTemplate.opsForValue().get(key);
}
public void deleteValue(String key) {
redisTemplate.delete(key);
}
}사용 예시
@RestController @RequiredArgsConstructor public class RedisController { private final RedisService redisService; @PostMapping("/cache") public void cacheData() { redisService.setValue("testKey", "testValue", 3600); } @GetMapping("/cache") public String getCachedData() { return redisService.getValue("testKey"); } }
3. 결론
Redis는 빠른 성능, 다양한 데이터 구조, 확장성 있는 아키텍처를 제공하여 다양한 애플리케이션에서 활용될 수 있다. 특히 캐싱, 세션 관리, 실시간 데이터 처리를 위한 훌륭한 선택지이다. Redis의 TTL 설정과 같은 기능은 효율적인 데이터 관리를 가능하게 한다. Spring Boot와 같은 프레임워크와 통합하면 손쉽게 활용할 수 있다.
