쿼리 분석
데이터베이스 엔진은 쿼리를 수행할 때 어떤 방식을 사용하고 어떤 순서로 쿼리를 수행 할지에 대한 계획을 세우게 되는데,
이것을 쿼리 실행 계획(Query execution plan) 또는 쿼리 플랜(Query plan) 이라고 부른다.
PostgreSQL과 MySQL 모두 EXPLAIN 이라는 SQL구문을 이용해 쿼리 플랜을 확인할 수 있다.
그리고 성능 분석을 할 때는 보통 ANALYZE 문까지 붙여서 실행 시간을 포함한 구체적인 실행 계획을 분석한다.
- EXPLAIN: 쿼리 튜닝 초기 단계나 데이터 변경 없이 실행 계획만 확인하고 싶을 때
- EXPLAIN ANALYZE:
- 실제 성능 측정이 필요할 때
- 예상 실행 계획과 실제 실행 결과의 차이를 비교하고 싶을 때
- 더 정확한 튜닝 정보가 필요할 때
비용(Cost) 의 주요 구성 요소
- 디스크 페이지 읽기 비용
- sequential page cost (기본값: 1.0)
- 순차적으로 디스크 페이지를 읽는 비용
- random page cost (기본값: 4.0)
- 무작위로 디스크 페이지를 읽는 비용
- 일반적으로 순차 읽기보다 더 비쌈
- sequential page cost (기본값: 1.0)
- CPU 처리 비용
- cpu_tuple_cost (기본값: 0.01)
- 한 행을 처리하는 CPU 비용
- cpu_index_tuple_cost (기본값: 0.005)
- 인덱스 항목을 처리하는 CPU 비용
- cpu_operator_cost (기본값: 0.0025)
- 연산자나 함수를 실행하는 CPU 비용
- cpu_tuple_cost (기본값: 0.01)
💁♂️ EXPLAIN
- cost : 상대적인 수행 비용
- rows : 예상 조회 대상 열(row)의 수
- seq num : 쿼리 수행 순서
EXPLAIN ANAYLIZE
- 추정되는 수행 시간
- 추정되는 결과 열(row)의 수
- 처음 열을 얻는데 걸리는 시간
- 모든 결과를 얻는데 걸리는 시간
- 루프 수
실행계획 주요 지표
Cost (비용)
- 쿼리 실행에 소요되는 논리적 비용
- 비용이 클수록 무거운 쿼리를 의미
- 옵티마이저가 산출한 값으로, 플랜 비교 시 기준값으로 활용
Cardinality (카디널리티)
- 쿼리 조건에 맞는 레코드 건수
- 단위: K(10³), M(10⁶), G(10⁹)
- 예시: 42M = 4,200만 건
Bytes (바이트)
- 쿼리 실행 시 발생하는 네트워크 트래픽량
- 계산방법: (1Row의 컬럼 길이 총합) × (카디널리티)
쿼리 개선하기
다음과 같은 쿼리를 개선하고자 한다.
EXPLAIN select
t1_0.id,
c1_0.id,
c1_0.created_at,
c1_0.modified_at,
c1_0.name,
c1_0.type,
c2_0.thread_id,
c2_0.id,
c2_0.message,
c2_0.user_id,
t1_0.created_at,
e1_0.thread_id,
e1_0.id,
e1_0.body,
e1_0.user_id,
m1_0.thread_id,
m1_0.user_id,
m1_0.created_at,
m1_0.modified_at,
t1_0.message,
t1_0.modified_at,
t1_0.user_id
from
thread t1_0
left join
channel c1_0
on c1_0.id=t1_0.channel_id
left join
thread_emotion e1_0
on t1_0.id=e1_0.thread_id
left join
comment c2_0
on t1_0.id=c2_0.thread_id
left join
thread_mention m1_0
on t1_0.id=m1_0.thread_id
left join
thread_mention m2_0
on t1_0.id=m2_0.thread_id
where
exists(select
1
from
thread_mention m3_0
where
m3_0.user_id=1
and t1_0.id=m3_0.thread_id)
order by
m2_0.created_at desc;
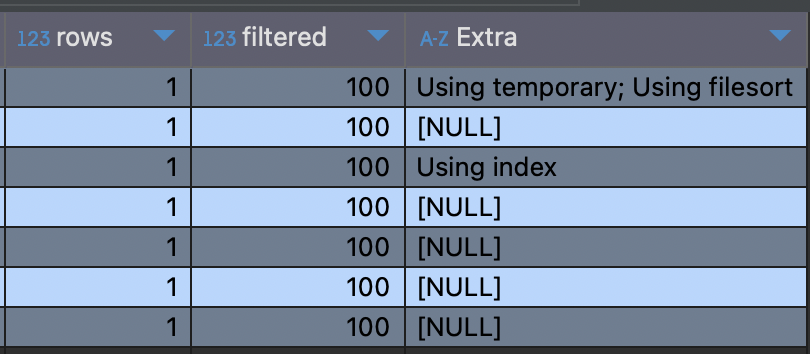
위와 같은 결과가 나온다.
ANALYZE 를 추가하면
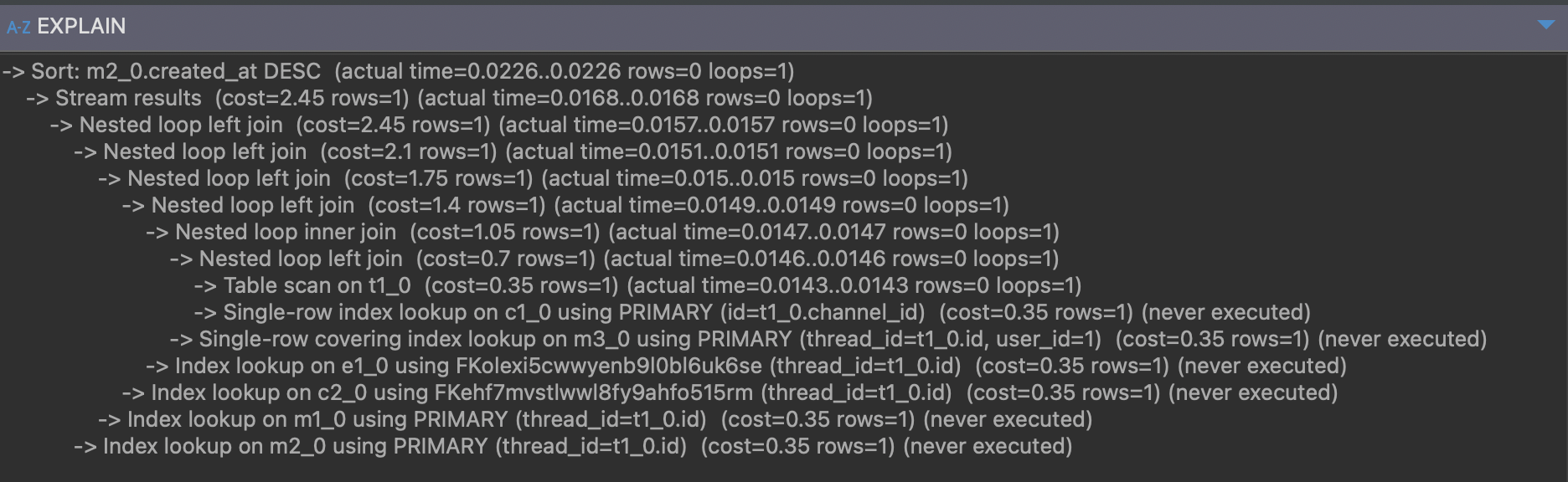
위와 같은 결과가 나온다.
- 쓸모없는 JOIN 없애기
쿼리를 보면
left join
thread_mention m1_0
on t1_0.id=m1_0.thread_id
left join
thread_mention m2_0
on t1_0.id=m2_0.thread_id 같은 테이블이 두 번 JOIN 되고 있는 것을 확인할 수 있다.
하나를 제거하고 결과를 보면

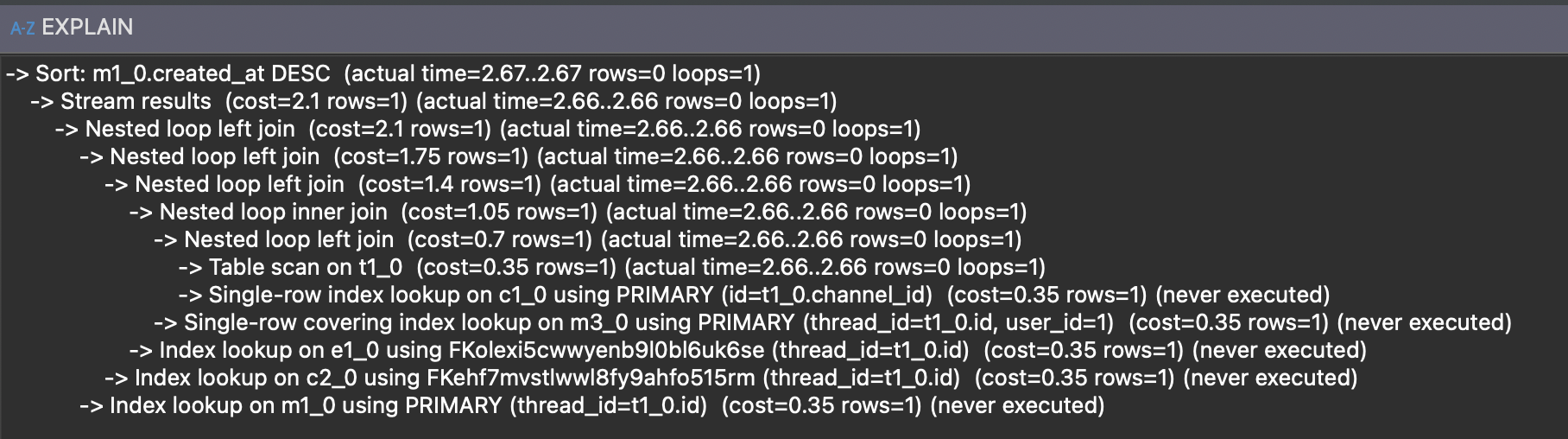
- 불필요한 필드 삭제
select
t1_0.id,
c1_0.id,
c1_0.created_at,
c1_0.modified_at,
c1_0.name,
c1_0.type,
#c2_0.thread_id, # join on t1_0.id = c2_0.thread_id -> t1_0.id 중복
c2_0.id,
c2_0.message,
c2_0.user_id,
t1_0.created_at,
#e1_0.thread_id, # join on t1_0.id = e1_0.thread_id -> t1_0.id 중복
e1_0.id,
e1_0.body,
e1_0.user_id,
#m1_0.thread_id, # join on t1_0.id = m1_0.thread_id
m1_0.user_id,
m1_0.created_at,
m1_0.modified_at,
t1_0.message,
t1_0.modified_at,
t1_0.user_id
from주석에 설명한 이유로 불필요한 필드를 삭제해 비용을 줄였다.
- 서브쿼리 없애기
where
exists(select
1
from
thread_mention m3_0
where
m3_0.user_id=1
and t1_0.id=m3_0.thread_id)위와 같은 서브쿼리는 Using temporary; Using filesort 풀스캔을 돌리기 때문에 효율적이지 못하다.
위의 쿼리는 m1_0.user_id = 1 로 대체할 수 있다.
결과는


- 인덱스 적용
m1_0 테이블의 정렬(ORDER BY m1_0.created_at DESC)에서 파일 정렬이 발생하므로 user_id와 created_at에 복합 인덱스를 생성할 수 있다.
CREATE INDEX idx_user_id_created_at ON thread_mention (user_id, created_at DESC);결과는 다음과 같다.

최종 쿼리
-- CREATE INDEX idx_user_id_created_at ON thread_mention (user_id, created_at DESC);
EXPLAIN select
t1_0.id,
c1_0.id,
c1_0.created_at,
c1_0.modified_at,
c1_0.name,
c1_0.type,
c2_0.id,
c2_0.message,
c2_0.user_id,
t1_0.created_at,
e1_0.id,
e1_0.body,
e1_0.user_id,
m1_0.user_id,
m1_0.created_at,
m1_0.modified_at,
t1_0.message,
t1_0.modified_at,
t1_0.user_id
from
thread t1_0
left join
channel c1_0
on c1_0.id=t1_0.channel_id
left join
thread_emotion e1_0
on t1_0.id=e1_0.thread_id
left join
comment c2_0
on t1_0.id=c2_0.thread_id
left join
thread_mention m1_0
on t1_0.id=m1_0.thread_id
where m1_0.user_id = 1
order by
m1_0.created_at desc;
어렵다 어려워
웹서핑부터 질의까지 이래저래 힘들었지만 어느정도 개선이 된 것 같다.
틀렸으면 나가죽어버려야지
화이팅!

.