1. 특정 배열에 값들을 넣을 때 , 중복없이 넣는 방법
ArrayList를 선언하고 , 특정 값이 value라고 할 때
If( ArrayList.indexOf(value) < 0 )
Arraylist.add(value);
이런 식으로 해야함. indexOf는 특정 value가 없으면 -1을 리턴하기 때문에
어레이 리스트에 이 값이 없을 때만 add하겠다는 뜻이다.
2. 어레이리스트의 값을 하나씩 가져와서 배열에 넣을 때
String형태면 for문돌리면서 arr[i] = list.get(i); 하면되는데
Int 형태라면 arr[i] = list.get(i).intValue(); 라고 해줘야된다.
3. 특정 정수를 잘라서 사용하고 싶을 때
지금까지는 123이라는 정수를 1, 2, 3 으로 나누어 생각하고 싶을 때 이 정수를
스트링으로 변환하고 substring해서 각각 나눈 다음 나중에 다시 정수로 변환해서 합치고 이랬는데 이럴 필요가 없었음
3을 뽑고싶으면 123 %10 을 하면됨. 그리고 123 / 10 을 한 것 즉 , 12 가 다음 숫자가되고 이를 다시 12 %10 하면 2가 나오고 12 / 10 하면 1이 나옴.
while(value !=0 ){
remain = value % 10 ;
value /= 10;
}이런 반복문을 쓰면 정수를 자리수로 각각 뽑아낼 수 있다.
4. 스트링을 자를 때
스트링을 하나씩 쪼개고 싶을 때 두가지가 있음
첫 번째는 String [] arr = str.split(“”);
이렇게 스트링을 하나씩 잘라서 바로 스트링 배열에 넣는 것이다.
두 번째는 str.substring(); 해서 쓰는 것이다.
세 번째는 charAt(); 을 사용한다.
5. 스트링을 분할하려면 substring , 배열을 분열하려면?
스트링은 str.substring(3,5) 이런 식으로 원하는 부분만 뽑아낼 수 있는데
배열은 substring이 불가능하다. 대신 Arrays.copyOfRange() 메소드를 통해 복사한다.
Arrays.copyOfRange(원본배열, 시작, 끝) 이렇게 사용 가능하다.
6. 배열 특정 값의 index 리턴받기.

7. 배열을 어레이리스트로 변환할 때
List lst = Arrays.asList(arr);
8. Dynamic Programming (DP) 문제 해결방법
1) 보통 누적되어 최대값이 되는 문제는 DP라고 의심해봐야함.
2) 먼저 특정 지점 i번째 에서의 식을 생각해본다.
3) 점화식의 형태로 간단하게 특정 지점에서의 식을 완성해본다
.
4) 이때 예를 들어 dp[i] = max(dp[i-1] , dp[i-2] + arr[i])
이런 점화식을 완성했다면 dp는 첫번째 값부터 이걸 for문 돌리면서
누적값을 구하는 형태인 경우가 많기에
가장 초기값 dp[0]을 지정해줘야한다.
그러고 for문의 i는 1부터 도는 경우가 많음.
9. DFS , BFS 문제 유형파악
1) DFS , BFS 의 개념적인 의미
기본적으로 최소거리는 BFS이다. 목적지를 찾은 순간 최소거리라는 것이 보장되는 알고리즘 이기 때문. DFS는 가능한 모든 경로를 탐색하여 경로를 찾을 때 쓴다.
그리고 DFS는 스택 OR 재귀를 쓰고 , BFS는 큐를 쓴다.

https://pangsblog.tistory.com/56 기본적인 알고리즘과 JAVA 구현코드는 여기 참고
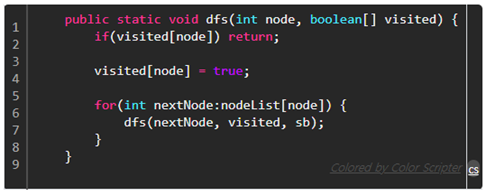
2) DFS 간단 구현 코드
방문배열을 만들고 이미 true라면 패스 , false일땐 true로 바꾸고
다음 노드로 다시 재귀함수를 호출한다
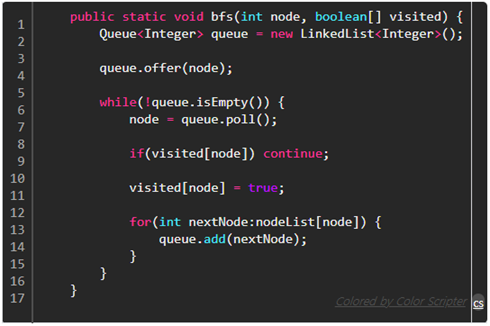
3) BFS 간단 구현 코드
큐에 시작 노드의 자식 노드를 넣는다. 특정 노드를 꺼낼 때 그 자식 노드를 큐에 넣는다고 생각하면 된다.
4) BFS , DFS 노드와 링크 구현하기
그럼 이제 이걸 적용하기 위해 노드와 링크를 구현해야한다.
일단 가장 쉬운 방식으로는 인접행렬을 쓰는 것.
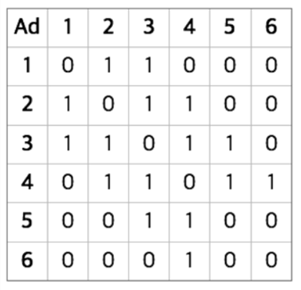
이런 식으로 2차원 배열을 선언하고 arr[2][3] = 1 이면 노드2 , 노드3이 서로 연결되었다고 생각하는 것이다. 0 이면 링크가 없다는 뜻.
만약 링크에 가중치가 필요하다면 1 대신 가중치를 넣어주면 된다.
https://freestrokes.tistory.com/87 (참고 블로그 링크는 여기)
이 방식은 여러 링크를 한번에 확인할 수 있고 구현이 쉽지만 특정 노드와 노드가 연결되어 있는지를 찾으려면 배열을 매번 탐색해야 하므로 시간 복잡도가 높고 노드가 많아지면 배열의 크기도 너무 커지기 때문에 단점이 존재한다.
5) Node 클래스를 사용하여 좌표를 따라가는 BFS 최단거리 응용문제
BFS 를 써야하는 문제가 있다 예를 들어 특정 경로의 정보가 담긴 2차원 배열을 주고 최단거리를 찾는 유형의 문제는 BFS로 풀어야한다. 기본 맵에 대한 정보를 이차원 배열에 담고 방문 여부를 따지는 이차원 배열도 선언한다. 그리고 시작점 좌표 0,0 에서 시작하므로 BFS(0,0) 을 main 에서 선언해준다.
이 때 BFS 는 큐를 써야 하므로 이전엔 그냥 노드 번호를 큐에 담기만 하면 되었는데, 이제는 좌표 값을 넣어야 한다. 이 때 Node 클래스를 선언한다.

Depth 는 문제마다 필요하면 쓰고 아님 안쓰는데, 중요한건 x,y 값을 클래스로 지정해두면 Queue q = new LinkedList<>(); 이렇게 큐를 Node 클래스를 담도록 할 수 있다.
q.add(new Node(a,b)); 이런 식으로 좌표 클래스를 큐에 넣고
Node node = q.poll(); 이렇게 큐에서 뽑을 수 있다.

Node 클래스를 담는 큐를 선언하여 이전의 BFS 알고리즘과 동서남북 방향대로 조건 확인하는 모든 부분이 결합된 코드이다.
마지막 지점 즉, visited[row-1][col-1] 이 true 일 때가 종료되는 시점이다.
이 때까지의 depth 가 바로 최단거리가 된다.
10. 정렬
퀵 , 머지 , 삽입 , 카운팅 , 라딕스 정렬에 대해 공부하고
각각의 장단점 , 어떻게 돌아가는지 , 시간 복잡도에 대해서 공부하기
퀵소트 , 머지 소트 차이점
어떠한 문제가 있을 때 해결하려면 어떤 소트를 쓸 것인가
바이너리 서치에 대해서 정리

11. 해시와 링크드해시
HashMap<String , Integer> hm = new HashMap<>();
이렇게 선언한다.
값 추가 : hm.put(“성재” , 10);
값 변경 : hm.put(“성재” , 30); -> 키 기준이라 그냥 그대로 put하면 값이 변경됨
값 삭제 : hm.remove(“성재”);
Key , value 값 for문으로 뽑아내기

근데 이렇게 for문 돌려서 뽑으면 순서가 랜덤으로 나오는데
만약 put한 순서대로 뽑고 싶다면 LinkedHashMap으로 선언하면된다.


배열에 담겨있는 스트링을 차례로 담으면서 getOrDefault 쓰는 예제
HashMap의 경우 같은 key에 해당되면 값이 그대로 덮어쓰기가 되어버린다.
근데 같은 key값이면 value를 하나씩 늘리거나 빼고 싶은 경우가 생긴다.
동일한 이름의 key를 가지고있다면 인원 수 value를 1씩 증가 시키는 등등
이런 경우에는 getOrDefault(key, defaultValue) 라는 메소드를 쓴다.

For(String key : hm.keyset() )
Hm.put(key , getOrDefualt(key , 0) + 1);
keyset() 에서 key를 받아와서 해시맵에 해당 키가 있으면
value값 가져와서 1추가해주고 , 없으면 기본값설정해둔 0 을
https://codechacha.com/ko/java-map-hashmap/


https://codevang.tistory.com/289
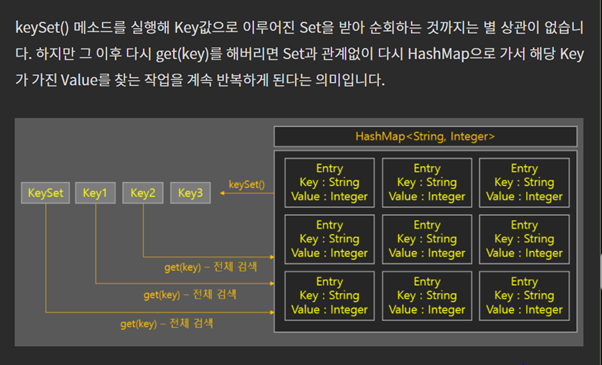
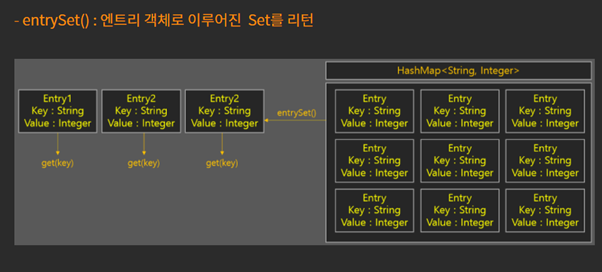
keyset 을 가져오는것보다 내부의 entrySet자체를 가져오는게 더 빠르다.
12. StringBuffer 클래스 이용하기
그냥 String 클래스는 공간 , 시간 낭비도 심한데 StringBuffer 클래스를 활용하면 낭비도 줄이고 다음과 같은 메소드도 코테에서 유용하게 사용가능.

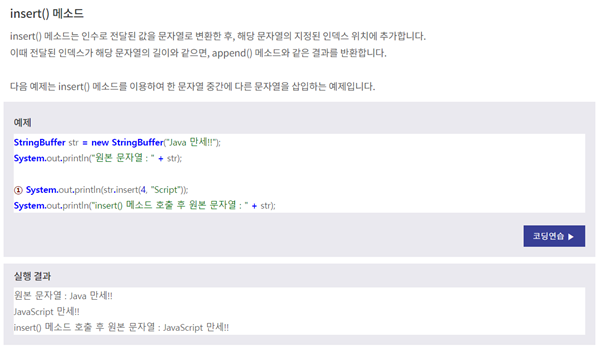

이런 식으로 문자열을 추가하거나 변경할 때 많이 쓰이는데
마지막에 toString() 을 꼭 해줘야 함.
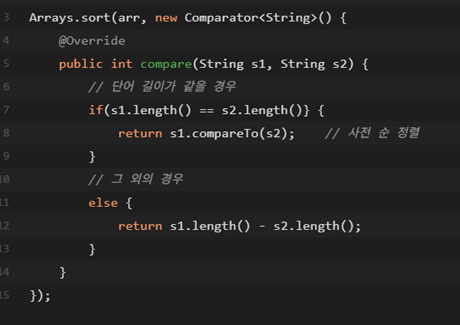
13. Comparator 를 이용한 Arrays.sort() 커스터마이징
https://st-lab.tistory.com/112
여기 블로그를 참고해보면 좋음.

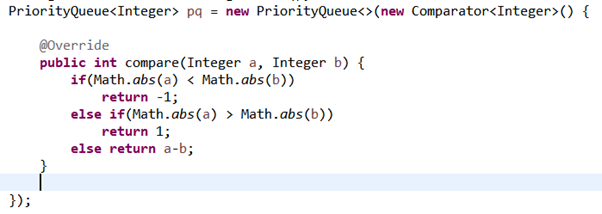
이건 우선순위큐에서 뽑는 순서를 커스터마이징 한 것이다.
음수는 순서를 바꾸고 양수는 그대로이므로 순서가 앞으로가면 먼저 뽑힌다는 의미임.
절대값이 작은 값이 우선적으로 나오고 , 절대 값이 같으면 작은 값이 먼저 나오도록 한 것. 전체적인 구조는 거의 비슷하다고 보면 된다.
14. 시간초과나 메모리초과 날 때
1) 입력 시 BufferedReader , StringTokenizer 사용하기
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st = new StringTokenizer(br.readLine());
정수 받기 : row= Integer.parseInt(st.nextToken());
스트링 받기 : String line = st.nextToken();
2) 출력 시 StringBuilder 사용하기
15. 순열 Permutation 사용하기
먼저 순열이란 중복을 허락하지 않는 것이기 때문에 중요한 건 visited[] 를 이용해서 방문했는지 여부를 체크하는 것이다.
1) 순열을 담을 배열 arr[] , 방문체크 할 visited[]를 전역으로 처리한다.

이러면 나중에 순열 함수를 호출할 때 배열 두개를 안넘겨도 되기 때문에 간결하다.
또한 arr 의 크기는 M , visited 의 크기는 N으로 해야한다.
2) 두 개의 정수를 받는다.( N 개 중에서 M 개를 중복없이 뽑는다.)
3) 방문 배열을 false로 초기화하고 permutation(0)을 호출한다.
4) Permutation( int depth) 로 구성되는데 depth가 M이 되면 종료한다.
5) Depth가 아직 M이 아니라면

총 N개의 경우만큼 for문을 돌리면서 현재 idx에서 방문 배열이 false라면 true로 바꾸면서 값을 채워준다. 그 다음 재귀 함수를 depth+1 로 호출한다.
이 때 depth++로 하면 depth—를 해줘야 하므로 depth+1로 하는 것이 편하다.
재귀 호출하면 다시 visited방문배열을 false로 바꿔줘야 한다.
17. 조합 Combination 사용하기
조합은 순열 중에서 순서 상관없이 같은 숫자가 포함되어 있으면 다 똑 같은 것으로 생각한다. 근본적으로 순열과 구조는 거의 동일한데, 사실상 오름차순으로 뽑는 것과 유사하다.
1) 먼저 조합을 담을 배열 arr[] , 방문 체크할 visited[] , 그리고 숫자 N, M을 전역으로 선언하여 함수 넘길 때 간결하게 한다.
또한 arr 의 크기는 M , visited 의 크기는 N으로 해야 한다.
2) 두 개의 정수를 받고 방문배열을 초기화한다.
3) Combination(0,0) 을 호출한다
4) Combination( int depth , int position) 에서 depth는 M이 되면 출력할 때 쓰이고
Position은 이미 뽑은 놈은 다시 안 뽑기 위해 위치를 지정해준다.
5) 출력하는 부분이 조금 다르다 , 오름차순이 아닌 건 거르고 출력한다
거를 때 return으로 없애 버리는게 핵심

6) For문 돌릴 때 I = position으로 돌리는 것이 핵심이다.

18. 행렬의 곱
N M 행렬 , M K 행렬을 곱하면 결과는 N K 크기의 행렬이 만들어진다.
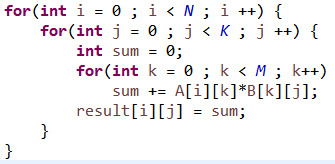
3중 포문을 돌려야 한다. 결과 배열이 N K 배열이니까 위에 두개의 포문은 N , K로 돌면서 결과 배열에 하나씩 값을 넣어주어야 한다.
그 다음 행렬의 곱한 값을 임시로 담아주면서 M을 도는 포문이 추가되어야 한다.
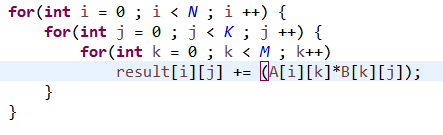
이렇게 해도됨
19. 이분탐색 , BinarySearch의 두가지 유형
1) 어떤 배열에 특정 값이 있는지 없는지를 검사하는 방법
이 방식은 특정 input 값이 배열에 있는지 없는지를 알아내는 것이다.
이 방식을 위해 배열은 먼저 오름차순으로 정렬되어야한다.
Public static int [] arr; // 전역으로 배열 선언
arr = new int [size];
Arrays.sort(arr); // 배열을 정렬
binarySearch(findValue); // 찾으려는 값을 인자로 함수 호출
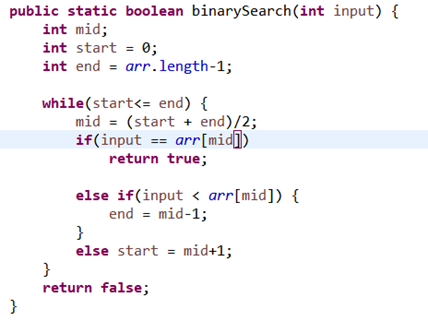
함수는 값이 있으면 true , 없으면 false를 반환하는 Boolean 형 함수형태를 가진다.
먼저 배열의 시작점 끝점을 start , end로 잡고 그 중간 값을 mid로 잡는다.
재귀로 다시 호출하는 것이 아니라 함수 자체에서 while문을 돌리는 것이 핵심이다.
While의 종료 조건은 start가 end보다 커지면서 포인터가 역전되는 경우이므로
While(start <= end) 일때 돌아간다. 이 안에서 mid 값은 중간값으로 계속 초기화해준다.
중간값 mid 가 찾는 값이라면 바로 true를 리턴하면되고
아니라면 두 포인터의 값을 mid 중심으로 바꿔주면 끝이다.
2) 이분탐색을 응용하여 parametric search 를 풀 수 있다.
이분탐색을 응용하여 최대값이나 최소값을 구하는 방식인데, 이것은 특정 input이 주어지지 않는다.
예를 들어 나무 길이가 각각 408 , 742 , 568 , 802 cm인 4개의 조각이 있을 때 최대의 길이로 잘라서 11개의 조각으로 만들려면 200cm 씩 자르면 2, 3 , 2, 4 개씩 잘려서 11개를 만들 수 있다. 이때의 최대로 자르는 길이 200cm를 찾는 문제다.
이 것은 주어진 길이들을 일단 배열에 담고 정렬하는 것 까지는 동일하다.
다만, input이 없기에 start는 1 , end 는 배열 마지막 즉, 가장 큰값 mid 는 그 중간 값으로 임의로 잡아줘야 한다.

while문의 조건과 mid를 잡는 방식은 동일한데, 원래는 특정 값이 딱 나오면 바로 리턴이지만 그보다 최대값이나 최소값이 더 있을 수 있기 때문에 조건이 조금 다르다.
그리고 마지막으로 mid값을 리턴하는게 아니라 최대값이라면 end를 최소값이라면 start를 리턴해줘야 한다.
20. 4가지 방향을 탐색(동서남북) 하는 방법
먼저 static int [] dx = {1, -1 , 0, 0};
Static int [] dy = {0, 0, 1, -1};
이렇게 두개의 int 배열을 선언한다. 보통 특정 지점 x , y 에서 동서남북으로 진행방향을 고르거나 주변 4개 배열 블록의 조건을 따져보고 싶을 때 쓴다.
먼저 4가지 방향이 있기 때문에 포문을 기본적으로 4번 돌아간다.

이 코드는 dx[i] , dy[i] 가 for문에 따라 방향이 바뀌고 이를 변수 nx , ny에 담은 후
X , y 지점에 대해서 nx , ny 좌표는 동서남북으로 한 칸씩 움직인 좌표가 되는 것이다.
이 4개의 좌표가 배열의 범위를 벗어나지 않고 , 배열의 값이 1이면 dfs를 호출한다는 코드이다.
즉, 정리하면 x, y 좌표에 대해서 동서남북 방향을 체크하려고 nx, ny 좌표를 만든 것이며 이 때, for문 4번 돌려서 dx[i] , dy[i]를 활용하는 것이다.


꿀정보들 감사합니다!