CHAPTER 07 제네릭과 컬렉션
7.1 컬렉션과 제네릭
7.2 제네릭 컬렉션 활용
7.3 제네릭 만들기
컬렉션의 개념
- 컬렉션
- 요소(element)라고 불리는 가변 개수의 객체들의 모음
- 객체는 데이터 타입도 다르고, 고정된 크기가 아님 고정 크기의 배열로 객체를 다루는 것은 어렵다
- 컬렉션을 사용하여 다양한 객체들의 삽입, 삭제, 검색 등을 관리 배열의 단점을 해결
- 컬렉션에서 다양한 자료구조에 대한 인터페이스와 클래스를 제공 직접 구현 할필요 x
- 인터페이스 : 컬렉션(
Set<E>,List<E>,Queue<E>),Map<K, V>등 - 클래스 :
ArrayList<E>,Vector<E>,LinkedList<E>,HashMap<K, V>등
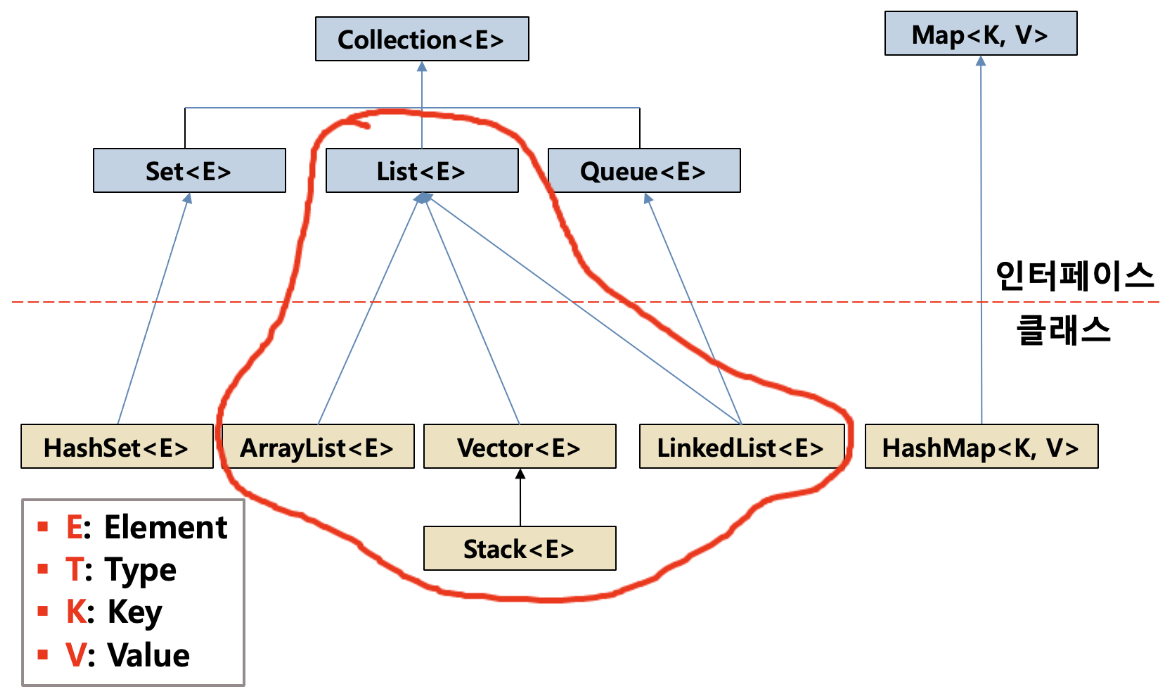
- 인터페이스 : 컬렉션(
컬렉션과 제네릭
- 컬렉션은 제네릭 기법으로 구현됨.
- 컬렉션의 요소는 객체만 사용 가능
- int,char, double 기본 타입 사용 불가 Wrapper 클래스 integer 사용
- JDK 1.5 부터 자동 박싱/언박싱 기능으로 기본 타입 사용이 가능하다
- int,char, double 기본 타입 사용 불가 Wrapper 클래스 integer 사용
- 제네릭
- 개념 : 모든 종류의 데이터 타입을 다룰 수 있도록 일반화된 타입 매개변수로 클래스나 메소드를 작성하는 기법
<E>,<K>,<V>: 타입 매개변수 요소 타입을 일반화한 타입
- 제네릭 클래스 사례 : 제네릭 벡터
Vector<E>- E 에 특정 타입으로 구체화
- 정수만 다루는 벡터
Vector<Integer> - 문자열만 다루는 벡터
Vector<String>
- 정수 스택, 문자열 스택, 이런 설계를 데이터 타입마다 설게하면 너무 번거로움 제네릭 스택 사용
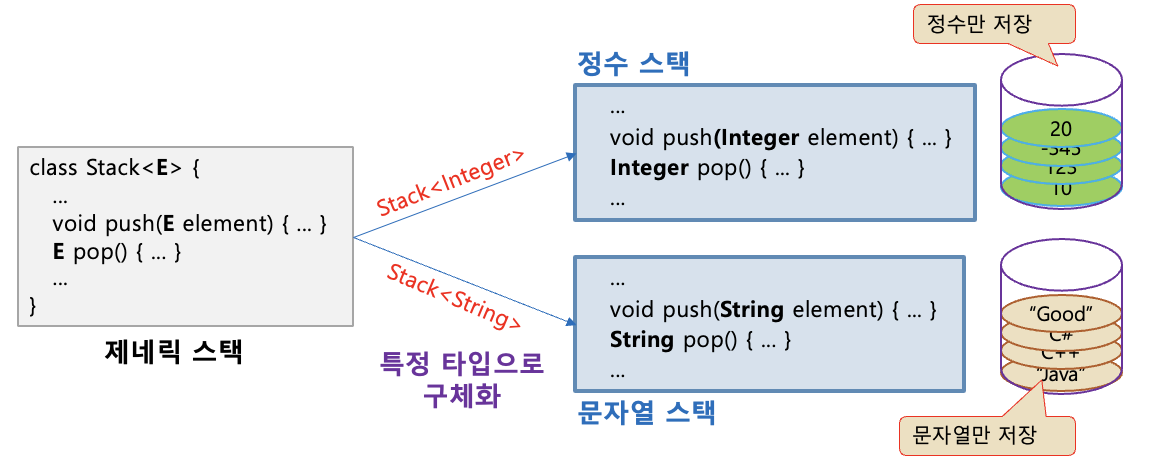
- 개념 : 모든 종류의 데이터 타입을 다룰 수 있도록 일반화된 타입 매개변수로 클래스나 메소드를 작성하는 기법
❶ Vector<E>
- List 인터페이스을 vector 라는 클래스로구현
- 여러 객체들을 삽입, 삭제, 검색 하는 컨테이너 클래스
- 배열의 길이 제한 극복
- 원소의 개수가 넘처나면 자동으로 길이 조절
- Vector에 삽입 가능한 것
- 객체.null
- 기본 타입은 Wrapper 객체로 만들어 저장
Vector<Integer>컬렉션 내부 구성 : 리스트 지원
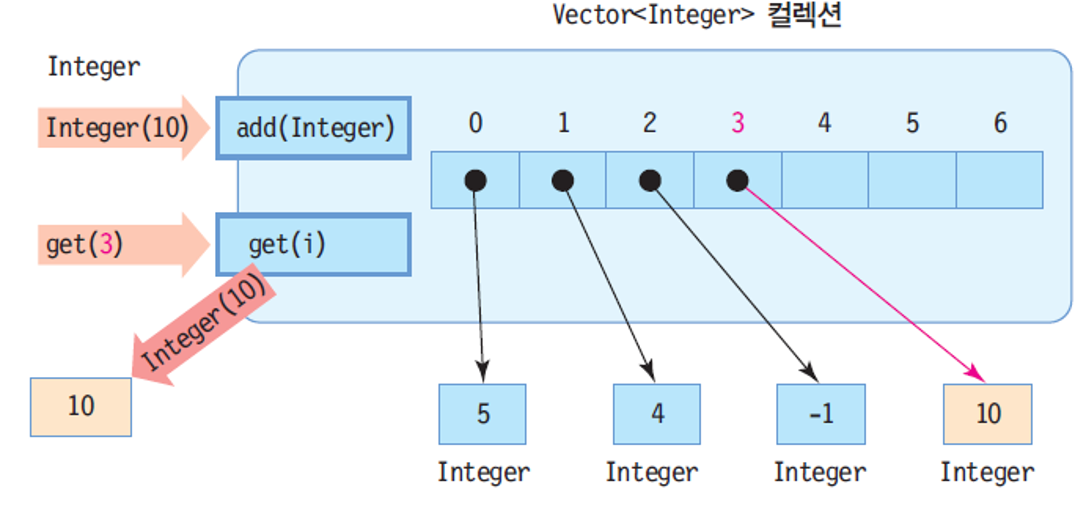
- 컬렉션을 매개변수로 받는 메소드 만들 수 있음.
﹣ 컬렉션과 자동 박싱/언박싱
- JDK 1.5 부터 자동 박싱/언박싱의 기능이 작동하여 기본 타입 값 사용 가능
Vector<Integer> v = new Vector<Integer>(); v.add(4); // -> v.add(Integer.valueOf(4)) 로 자동 박싱함 //**0번 인덱스의 Integer 타입의 정보가 int 타입으로 자동 언박싱됨**, k=4 int k = v.get(0); //int k = (Integer)v.get(0).intValue(); //제네릭의 타입 매개 변수를 기본 타입으로 구체화할 수는 없음 Vector<int> v = new Vector<int>(); //오류
예제 7-1 : 정수만 다루는 Vector <Integer> 컬렉션 활용 (Vector 의 주요 메소드 포함)
import java.util.Vector; //import 해주기
public class VectorEx {
public static void main(String[] args) {
// TODO Auto-generated method stub
//--- 정수 값만 다루는 제네릭 벡터 생성 ---
// 정수 클래스 데이터 타입의 객체 10개(디폴트)를 보관할 수 있는 메모리 생성, 참조변수 v로 관리
Vector<Integer> v = new Vector<Integer>();
//<--- 요소 삽입 v.add() --->
v.add(5); //5 삽입 -> [자동박싱] v.add(Integer.valueOf(5))
v.add(4);
v.add(-1);
// v -> {5(Integer 객체), 4, -1}
//<--- 벡터 중간에 삽입하기 --->
v.add(2, 100); //4와 -1 사이에 정수 100 삽입
//v로 관리하는 영역의 2번 인덱스 위치에, 클래스 타입 Integer 100 삽입
//기존 내용들은 한 칸 씩 밀려난다.
// v -> {5, 4, 100, -1}
//v.size() : 벡터가 포함하고 있는 요소의 개수
System.out.println("The number of element objects in the vector: " + v.size()); //4
//v.capacity() : 벡터의 현재 용량
System.out.println("The current capacitiy of the vector: " + v.capacity()); //10
// --- 모든 요소 정수 출력하기 ---
for(int i=0; i < v.size(); i++) {
int n = v.get(i); //지정된 index 의 요소 반환 (예외처리 지원하지 않음)
System.out.println(n);
}
//--- 벡터 속의 모든 정수 더하기 ---
int sum = 0;
for(int i = 0; i < v.size(); i++) {
int n = v.elementAt(i); //지정된 index의 요소 반환(예외처리 디폴트로 지원)
sum += n;
}
System.out.println("The sum of the integers in a vector: " + sum);
//--- 벡터 삭제하기 ---
v.remove(1);
//마지막 요소
int last = v.lastElemnet();
//모든 요소 삭제
v.removeAllElement();
}
}
//result
The number of element objects in the vector: 4
The current capacitiy of the vector: 10
5
4
100
-1
The sum of the integers in a vector: 108예제 7-2 : Point 클래스만 다루는 Vector<Point> 컬렉션 활용
import java.util.Vector;
class Point{
private int x,y;
public Point(int x, int y) {
this.x = x;
this.y = y;
}
//'toString 재정의' [6장 참조]
public String toString() {
return "(" + x + "," + y + ")";
}
};
public class PointVectorEx {
public static void main(String[] args) {
// TODO Auto-generated method stub
// Point 객체를 요소로만 가지는 벡터 생성
Vector<Point> v = new Vector<Point>();
//3개의 Point 객체 삽입
v.add(new Point(2,3)); //이후 정수 2개를 처리하는 생성자 호출
v.add(new Point(-5,20)); //셍상지 호출 후 만들어진 정보를 add 로 v에 추가
v.add(new Point(30,-8));
//벡터에 있는 Point 객체 모두 검색하여 출력
for(int i=0; i<v.size(); i++) {
//해시 코드 값이 리턴되는것 꼭 기억
Point p = v.get(i); //벡터에서 인덱스 i 번째에 해당하는 Point 객체의 해시코드 값을 p 에 할당
System.out.println(p); //p.toString() 으로 자동 변환되고, toString() 을 오버라이딩
// 따라서 참조변수 p가 관리하는 Point 인스턴스의 x,y 좌표 출력
}
}
}
//result
(2,3)
(-5,20)
(30,-8) ﹣ 자바의 타입 추론 기능의 진화
//java 7 이전
Vector<Integer> v = new Vector<Integer>();
//java 7 이후
// - 컴파일러의 타입 추론 기능 추가
// - < > (다이아몬드 연산자)에 타입 매개변수 생략
Vector<Integer> v = new Vector<>();
//java 10 이후
// - var 키워드 도입, 컴파일러의 지역 변수 타입 추론 기능
var v = new Vector<Integer>();❷ ArrayList<E>
- 가변 크기의 배열을 구현한 클래스 벡터와 거의 같다
- 벡터와 차이점 : 벡터와 달리 스레드 동기화 지원 않함.
- 예외처리를 신경써서 할거면 elementAt 사용 아니면 get 사용

﹣ ArrayList<E> 클래스의 주요 메소드
//ArrayList 생성
ArrayList<String> a = new ArrayList<String>(7);
//요소 삽입
a.add("Hello"); //0번 인덱스
a.add("Hi"); //1번 인덱스
a.add("Java"); //2번 인겓스
//요소 개수 n, 용량 측정 capacity() 메소드는 없다.
int n = a.size(); //n=3
//요소 중간 삽입
a.add(2, "Sahni"); // a.add(5,"~") -> a.size() 보다 큰 위치에 삽입 불가
//요소 알아내기
String str = a.get(1); //1번 인덱스의 "Hi" 를 받는것이 아닌 "Hi" 를 관리하는 해시값을 str 에 제공
//요소 삭제
a.remove(1); // a.remove(4); -> 요류
//모든 요소 삭제
a.clear();예제 7-3 : 문자열 입력받아 ArrayList 에 저장
- 이름을 4개 입력받아 ArrayList 에 저장하고 모두 출력한 후 제일 긴 이름을 출력하라.
import java.util.*;
public class ArrayListEx {
public static void main(String[] args) {
// TODO Auto-generated method stub
//문자열만 삽입가능한 ArrayList 컬렉션 생성 -> 크기 지정하지 않으면 디폴트 크기 10
ArrayList<String> a = new ArrayList<String>(); //또는 var a = new ArrayList<String>();
//키보드로부터 4개의 이름 입력받아 ArrayList 에 삽입
Scanner scanner = new Scanner(System.in);
for(int i=0; i<4; i++) {
System.out.print("Enter a name >> ");
String s = scanner.next(); //키보드로부터 이름 입력
a.add(s); //ArrayList 컬렉션에 순차적으로 삽입
}
//ArrayList 에 들어 있는 모든 이름 출력
for(int i=0; i<a.size(); i++) {
String name = a.get(i); //ArrayList a 로 참조하는, 리스트 객체의 i 번째 인덱스 문자열 얻어오기
// 인덱스 i 에 해당되는 객체(인스턴스)의 해쉬코드 값을 String 클래스의 참조변수인 name 에 할당
System.out.print(name + " "); // name 참조 변수로 관리하는 문자열 Mike ..출력
}
int longestIndex = 0;
// 가장 긴 이름 출력
for(int i=0; i<a.size(); i++) {
if(a.get(longestIndex).length() < a.get(i).length())
longestIndex = i;
}
System.out.println("\n The longest name is : " + a.get(longestIndex));
}
}
//result
Enter a name >> Mike
Enter a name >> Jane
Enter a name >> Ashley
Enter a name >> Helen
Mike Jane Ashley Helen
The longest name is : Ashley컬렉션의 순차 검색을 위한 Iterator
Iterator<E>인테페이스Vector<E>,ArrayList<E>,LinkedList<E>,HashMap<K, V>가 상속받는 인터페이스- 리스트 구조의 컬렉션에서 요소의 순차 검색 을 위한 메소드를 포함한다.
- 인덱스가 없는 해시맵은 특정한 인덱스로 접근할 수 없기 떄문에, Iterator 활용한 순차적 접근이 필요하다.
- Vector 및 ArrayList는 인덱스 정보를 활용하여 특정 위치의 요소에 직접 접근할 수 있지만, LinkedList와 HashMap은 인덱스를 사용하여 직접 접근하는 것이 불가능
Iterator<E>인터페이스 메소드- boolean hasNext() : 다음 반복에서 사용될요소가 있으면 true 반환
- E.next() : 다음 요소 반환
- void remove() : 마지막 반환된 요소 제거
- Iterator() 메소드
- Iterator() 를 호출하면 Iterator 객체 반환
- Iterator 객체를 이용하여 인덱스 없이 순차적 검색 가능
Vector<Integer> v = new Vector<Integer>(); Iterator<Integer> it = v.iterator(); while(it.hasNext()) { //모든 요소 방문 int n = it.next(); //다음 요소 리턴 }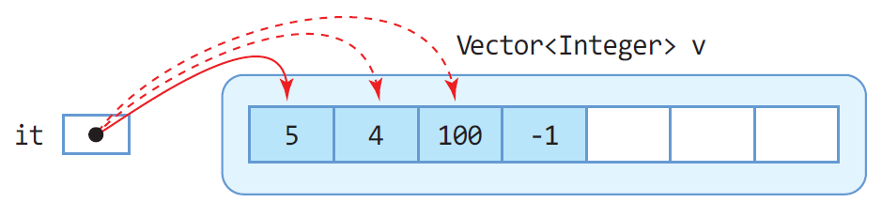
예제 7-4 : Iterator를 이용하여 Vector의 모든 요소 출력하고 합 구하기
import java.util.*;
public class IteratorEx {
public static void main(String[] args) {
// TODO Auto-generated method stub
Vector<Integer> v = new Vector<Integer>(); //정수 값만 다루는 제네릭 벡터 생성, 디폴트 크기 10
v.add(5); //Integer 객체 5 삽입
v.add(4); // " 4 삽입
v.add(-1); // " -1 삽입
v.add(2,100); //4와 -1 사이에 정수 100 삽입
//Iterator 를 이용한 모든 정수 출력하기
//벡터 내부의 정보에 접근할 수 있는 iterator 클래스의 참조변수 it
Iterator<Integer> it = v.iterator(); //Iterator 객체 얻기
while(it.hasNext()) { //나를 기준으로 다음 위치의 벡터가 존재하는지
int n = it.next(); //it 으로 관리하는 영역으로 가서 다름 벡터값을 리턴하라.-> 5리턴 (첫 시도 기준)
System.out.println(n);
}
int sum = 0;
it = v.iterator(); // Iterator 객체 얻기
//(현재 it 위치가 v가 가리키는 벡터의 '마지막'위치이기 떄문에 새로 얻음)
while(it.hasNext()) { //iterator 를 이용하여 모든 정수 더하기
int n = it.next();
sum += n;
}
System.out.println("The sum of the integers in a vector : " + sum);
}
}
//result
5
4
100
-1
The sum of the integers in a vector : 108- 검증하기 위한 it 의 값을 출력하는 추가 코드 *
- it의 주소는 고정되어있음을 확인하기 위한 코드 추가
it.next() 를 수행하면, it 자체의 참조 변수가 다음 벡터의 해쉬코드 값을 갖는 것이 아닌, 내부의 숨겨진 인덱스 정보가 이동(빨간색 화살표)함을 확인하기 위한 코드
- it의 주소는 고정되어있음을 확인하기 위한 코드 추가
❸ HashMap<K, V>
-
key 와 value 의 쌍으로 구성되는 요소를 다루는 컬렉션
- key는 내부적으로 해시맵에 삽입되는 위치 결정에 사용 -> key를 이용하여 value 검색
-
삽입 및 검색이 빠른 특징
- 요소 검색 : get() 메소드
- 요소 삽입 : put() 메소드
Set<K>keySet(): HashMap 에 있는 모든 키를 담은Set<k>컬렉션 리턴
-
key 와 value 로 관리되는 클래스 데이터 타입은 각각 string, string
// 해시맵 생성 HashMap<String, String> h = new HashMap<String, String>(); // 해시맵에 (키, 값) 삽입 h.put("baby", "아기"); h.put("love", "사랑"); h.put("apple", "사과"); //키로 값 검색 String kor = h.get("love"); //kor = "사랑" //키로 요소 삭제 h.remove("apple"); //요소 개수 int n = h.size(); //n=2 // Set<String> keys = h.keySet(); //h로 관리하는 해시맵의 모든 키를 담은 Set<k> 컬렉션 리턴
[주의] 정보가 순차적으로 메모리에 할당되는 것이 아니라
hash() 메소드에 의해 다른 key와 구별이 되는 특정한 메모리 주소 정보가 할당됨
예제 7-5 : HashMap을 이용하여 (영어, 한글) 단어 쌍의 저장 검색
- (영어, 한글) 단어를 쌍으로 해시맵에 저장하고 영어로 한글을 검색하는 프로그램을 작성하여라.
- [풀이]
- 해시맵은 순차적이 아니라 어떤 규칙에 의해서 알아서 메모리를 확보해줌 (연속적인 공간이 아니다) - 10칸의 메모리 중에 적당한 곳에 정보 보관, 즉 우리가 입력한 순서대로 보관되지 않는다
- key 에 해당하는 값을 순차적으로 가져와서 dic.get 으로 value 를 얻어온다.
import java.util.*;
public class HashMapDicEx {
public static void main(String[] args) {
// TODO Auto-generated method stub
// 영어 단어와 한글 단어의 쌍을 저장하는 HashMap 컬렉션 생성
HashMap<String, String> dic = new HashMap<String, String>();
//3개의 (key, value) 쌍을 dic 에 저장
dic.put("baby", "아기"); //"baby" 는 key, "아기"는 value
dic.put("love", "사랑");
dic.put("apple", "사과");
// dic 컬렉션에 들 있는 모든 (key, value) 쌍 출력
Set<String> keys = dic.keySet(); //(중요한 부분) dic로 관리하는 해시맵에 접근하여 모든 키 문자열을 담은 Set<k> 컬렉션 리턴
Iterator<String> it = keys.iterator();
while(it.hasNext()) { //key, value 에 저장되어 있는 문자열 출력 (it 으로 순차적 접근을 한다)
String key = it.next();
String value = dic.get(key);
System.out.println("(" + key + "," + value + ")");
}
//밑에는 iterator 를 사용하지 않고 무한루프를 돌리면서 탈출할 수 있는 조건을 걸어둠
//it 으로 순차적으로 접근하는줄 알았지만, 우리 눈에 보이지 않게 알아서 순차적으로 접근한다.(iterator 사용 하지 않는 부분)
//kor==null : 해당 key 가 없다면 null
// 영어 단어를 입력 받고, 한글 단어 검색
Scanner scanner = new Scanner(System.in);
while(true) {
System.out.print("찾고 싶은 단어는?");
String eng = scanner.next(); //eng 는 내가 입력받은 문자열
if(eng.equals("exit")) {
System.out.println("종료합니다...");
break;
}
//해시맵에서 '키' eng 의 값 'kor' 검색
String kor = dic.get(eng); //해시맵에서 찾을 수 없는 경우에는 null 리턴
if(kor == null)
System.out.println(eng + "는 없는 단어 입니다.");
else
System.out.println(kor);
}
scanner.close();
}
}
//result
(love,사랑)
(apple,사과)
(baby,아기)
찾고 싶은 단어는?apple
사과
찾고 싶은 단어는?babo
babo는 없는 단어 입니다.
찾고 싶은 단어는?exit
종료합니다...예제 7-6 : HashMap을 이용하여 자바 과목의 이름과 점수 관리
- HashMap 을 이용하여 학생의 이름과 자바 점수를 기록 관리해보자.
내부 인덱스 확인하여 String 클래스 객체 "정원석" 의 참조값 리턴하여 name 에 할당
name -> "정원석" 에 연계되는 value 70 을 리턴
import java.util.*;
public class HashMapScoreEx {
public static void main(String[] args) {
// TODO Auto-generated method stub
// 사용자 이름과 점수를 기록하는 HashMap 컬렉션 생성
HashMap<String, Integer> javaScore = new HashMap<String, Integer>();
// 5개의 점수 저장
javaScore.put("한홍진", 97);
javaScore.put("황기태", 34);
javaScore.put("이영희", 98);
javaScore.put("정원석", 70);
javaScore.put("한원선", 99);
System.out.println("HashMap 의 요소 개수 : " + javaScore.size());
//모든 사람의 점수 출력
//javaScore 에 들어 있는 모든 (key,value) 쌍 출력
// key 문자열을 가진 집합 Set 컬렉션 리턴
// HaspMap 메모리 공간에 접근하기 위하여 javaScore.keySet() 메소드 활용
Set<String> keys = javaScore.keySet();
//key 문자열을 순서대로 접근할 수 있는 Iterator 리턴
Iterator<String> it = keys.iterator();
//while(it.hasNext()) {} 위치
while(it.hasNext()) {
//첫번쨰 상황 : 내부 인덱스를 확인하여 String 클래스 객체 "정원석" 의 참조값 리턴하여 name 에 할당
String name = it.next();
int score = javaScore.get(name); //key 인 "정원석" 에 연계되는 value=70 을 리턴
System.out.println(name + " : " + score);
}
}
}
//result
HashMap 의 요소 개수 : 5
정원석 : 70
한원선 : 99
한홍진 : 97
이영희 : 98
황기태 : 34예제 7-7 HashMap 에 객체 저장, 학생 정보 관리
- id 와 전화번호로 구성되는 Student 클래스를 만들고, 이름을 '키'로 하고 Student 객체를 '값'으로 하는 해시맵을 작성
- 우리가 만든 키 맵 구조로 관리하고 싶다고 하여 Student 라는 클래스를 작성해준다.
- HashMapStuendtEx 에 보면 <String 다음이 Student 클래스이다.>
import java.util.*;
class Student { //학생을 표현하는 클래스
int id;
String tel;
public Student(int id, String tel) {
this.id = id;
this.tel = tel;
}
//private 이였다면 이 메소드들은 우회하여 접근해야 할것이다.
public int getId() {return id;}
public String getTel() {return tel;}
}
public class HashMapStudentEx {
public static void main(String[] args) {
// TODO Auto-generated method stub
// 학샐 이름과 Student 객체를 쌍으로 저장하는 HashMap 컬렉션 생성
HashMap<String, Student> map = new HashMap<String, Student>();
// 3 명의 학생 저장
map.put("황기태", new Student(1, "010-111-1111"));
map.put("이재문", new Student(2, "010-222-2222"));
map.put("김남윤", new Student(3, "010-333-3333"));
Scanner scanner = new Scanner(System.in);
while(true) {
System.out.print("검색할 이름?");
String name = scanner.nextLine(); //t사용자로부터 이름 입력
if(name.equals("exit"))
break; //while 문 벗어나 프로그램 종료
Student student = map.get(name); //이름에 해당하는 Student 객체 검색, 못찾으면 null 리턴
if(student == null)
System.out.println(name + "은/는 없는 사람입니다.");
else
System.out.println("id :" + student.getId() + "전화:" + student.getTel());
}
System.out.print("프로그램 종료!"); //코드 추가함!
scanner.close();
}
}
//result
검색할 이름?이재문
id :2전화:010-222-2222
검색할 이름?김남윤
id :3전화:010-333-3333
검색할 이름?이하이
이하이은/는 없는 사람입니다.
검색할 이름?exit
프로그램 종료!
❹ LinkedList<E>
- List 인터페이스를 구현한 컬렉션 클래스
- Vector,ArrayList 클래스와 매우 유사하게 작동
- 요소 객체들은 양방향으로 연결되어 관리됨
- 요소 객체는 맨 앞, 맨 뒤에 추가 가능
- 요소 객체는 인덱스를 이용하여 중간에 삽입 가능
- 맨 앞이나 맨 뒤에 요소를 추가하거나 삭제할 수 있어 스택이나 큐로 사용 가능.
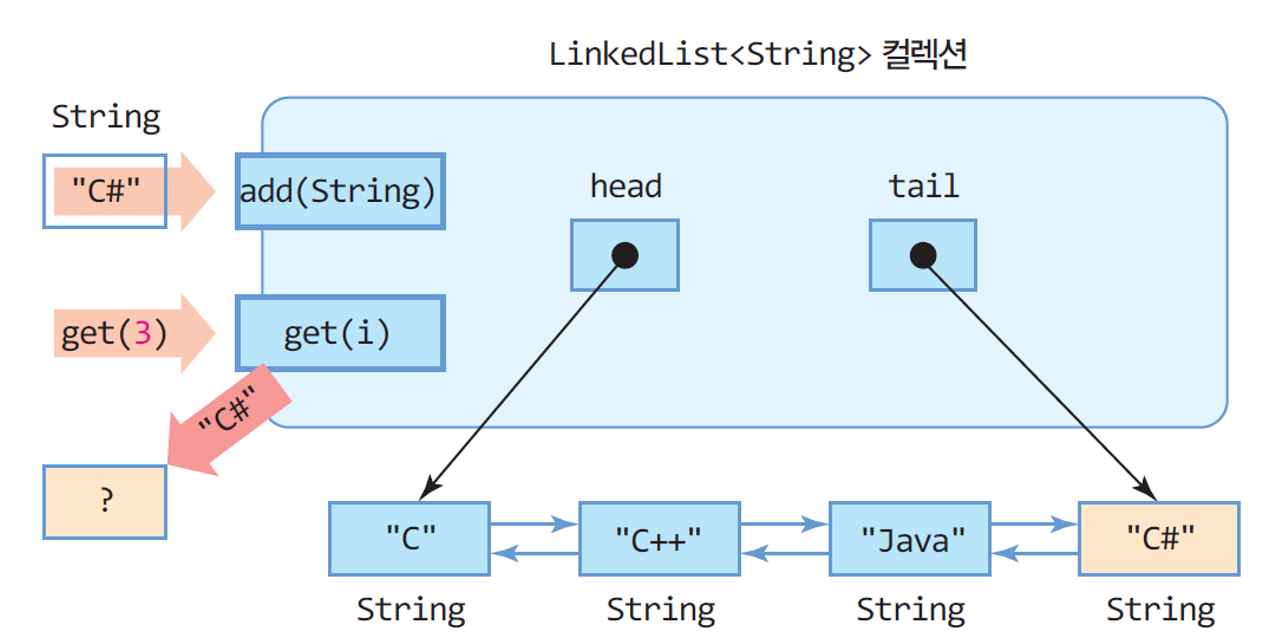
Vector vs ArrayList vs LinkedList 차이
1) Vector 와 List 의 차이점
- 동기화 처리 : 한개의 공용 자원을 두개의 스레드가 사용할때 반드시 한번에 하나씩 접근하도록
- 한개의 자원을 하나의 스레드가 사용할 떄는 굳이 동기화를 고려하지 않아도 됨
- Vector 는 무조건 동기화를 지원을 하기 떄문에, 단일 스레드를 사용하는 경우에는 ArrayList 나 LinkedList 보다 성능이 떨어진다.
2) Vector
- 자바 초기부터 제공하던 컬렉션
3) ArrayList
- 데이터를 배열의 복사에 의한 방법을 내부적으로 수행
- 데이터의 추가/삭제 시에 임시 배열을 내부적으로 생성하고 추가/삭제를 수행함
- -> 대용량 데이터 사용시에는 임시 배열에 복사를 수행해야 하는 관계로 성능이 떨어질 수 있다
- 각 데이터에 대한 인덱스를 이용할 수 있다는 장점이 있다.
4) LinkedList
- 시작과 끝 위치 정보를 가지고 있다.
- 현재 자료는 다음 자료의 위치 정보를 가지고 있으며, 내부적으로 모든 자료의 인덱스 정보를 가지고 있지는 않다
- 새로 샹성된 정보는 서로서로 연결된 참조값만 관리
- 데이터의 추가/삭제는 위치 정보만의 수정만으로 가능하기 떄문에 데이터의 추가/삭제 시 매우 유용
- 단점 : 순차적으로 자료를 찾는 과정에서 느려질 수 있다.
- 메모리를 생성하고 합치고 이런 과정이 없다!
﹣ Collection 클래스 활용
- 링크드 리스트를 하기 위해 다음 Collection 클래스 사용
- Collection 클래스
- java.util 패키지에 포함
- 컬렉션에 대해 연산을 수행하고 결과로 컬렉션 리턴
- 모든 메소드는 static 타입
- 주요 메소드
- 컬렉션에 포함된 요소들을 소팅하는 sort() 메소드
- 요소의 순서를 반대로 하는 reverse() 메소드
- 요소들의 최대, 최솟값을 찾아내는 max(), min() 메소드
- 특정 값을 검색하는 binarySearch() 메소드
예제 7-8 : Collections 클래스의 활용
[풀이]
- 참조변수 myList로 동적 메모리 공간에 문자열을 관리하는 링크드 리스트 공간을 관리!
- 인덱스를 지정해서 추가를 하고 있는데, 입력할때 인덱스가 지정 가능하다 정도 이해
- 원래 우리가 정렬을 해야하는데, Collections 라는 클래스로 정렬 메소드 사용
- 그 정보를 순차적으로 접근해서 출략을 하는데, 출력할 때 연속으로 정보가 존재하면 화살표
- next() 로 꺼내서 사용하면, 내부 인덱스가 바뀌고 나서 e 라는 참조 변수로 관리
- 내부 인덱스 하나 지정했고 -> 매트릭스
- 다음 요소를 연결하기 위해서 if 문으로 다시 한번 다음 요소가 있는지 체크하고 화살표와 newline 출력할지 분기
import java.util.*;
public class CollectionsEx {
static void printList(LinkedList<String> list) { //myList 라는 참조변수를 인자 list 라는 참조변수가 전달 받아 함수 역할 수행
Iterator<String> iterator = list.iterator(); //LinkedList 는 0,1,2 와 같은 인덱스로 관리 불가! 입력할 때만 사용 가능
while(iterator.hasNext()) { //따라서, 시작점에서 출발하여 다음 정보가 있는지 순차적으로 확인
String e = iterator.next();
String separator;
if(iterator.hasNext())
separator = "->";
else
separator = "\n";
System.out.print(e+separator);
}
}
public static void main(String[] args) {
// TODO Auto-generated method stub
LinkedList<String> myList = new LinkedList<String>();
myList.add("트랜스포머");
myList.add("스타워즈");
myList.add("매트릭스");
myList.add(0,"터미네이터");
myList.add(2,"아바타");
Collections.sort(myList); //요소 정렬
//sort(): static 메소드 이므로 클래스 이름으로 바로 호출
printList(myList); //정렬된 요소 출력
Collections.reverse(myList); //요소의 순서를 반대로
printList(myList); //요소 출력
int index = Collections.binarySearch(myList, "아바타")+1; //"d아바타" 의 인텍스 검색
System.out.println("아바타는" + index + "번째 요소입니다.");
}
}
//result
매트릭스->스타워즈->아바타->터미네이터->트랜스포머
트랜스포머->터미네이터->아바타->스타워즈->매트릭스
아바타는3번째 요소입니다.제네릭 만들기
- 제네릭 클래스와 인터페이스
- 클래스나 인터페이스 선언부에 일반화된 타입 추가

- 제네릭 클래스 레퍼런스 변수 선언

- 데이터 타입 2개인 경우는 T1, T2 로 여러개 사용가능
- 클래스나 인터페이스 선언부에 일반화된 타입 추가
- 구체화
- 제네릭 타입의 클래스에 구체적인 타입을 대입하여 객체 생성
- 컴파일러에 의해 이루어짐

- 구체화된 MyClass
<String>의 소스 코드 - T 라고 했었던 일반화 데이터 타입이 String 으로 자동으로 바뀐다
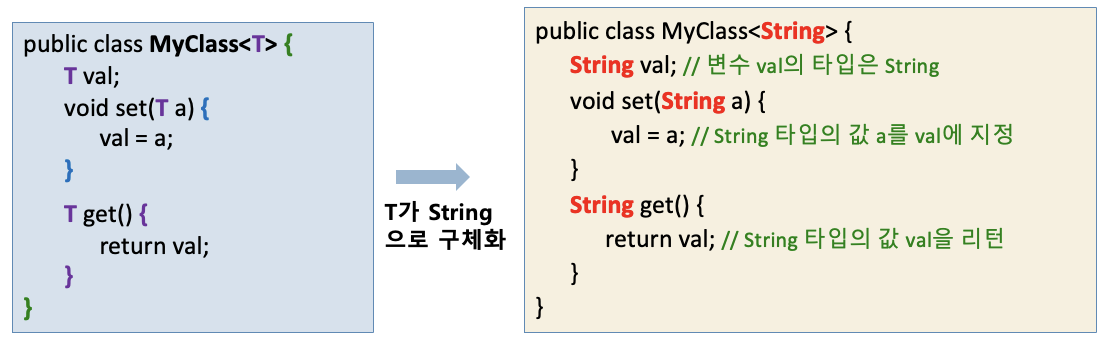
﹣ 구체화 오류
- 타입 매개 변수에 기본 타입은 사용할 수 없음
- 클래스 설계를 한번만 해도 다양한 데이터 타입 사용 가능 하지만 Integer 는 안된다, 혹은 Integer 같은 Wrapper 클래스는 가능

﹣ 타입 매개 변수
- 타입 매개 변수
- '<' 과 '>' 사이의 문자로 표현
- 하나의 대문자를 타입 매개 변수로 사용
- 많이 사용하는 타입 매개 변수 문자
- E : Element 를 의미하며 컬렉션에서 요소를 표시할 때 많이 사용
- T : Type 을 의미
- V : Value 를 의미
- K : Key 를 의미
- 타입 매개 변수가 나타나는 타입의 객체 생성 불가
ex) T a = new T()
- 타입 매개 변수는 나중에 실제 타입으로 구체화
- 어떤 문자도 매개 변수로 사용 가능
- 구체화 되고 나서는 사용가능한데 설계시에는 안된다.
예제 7-9 : 제네릭 스택 만들기
스택을 제네릭 클래스로 작성하고, String 과 Integer 형 스택을 사용하는 예를 보여라.
class GStack<T>{
int tos;
Object [] stck; //제네릭에서는 제네릭 타입으로 배열 생성 할 수 없음
public GStack() {
tos = 0;
stck = new Object[10]; //제네릭에서는 제네릭 타입으로 배열 생성 할 수 없음
}
public void push(T item) {
if(tos == 10)
return;
stck[tos] = item;
tos++;
}
public T pop() {
if(tos == 0)
return null;
tos--;
return (T)stck[tos];
}
}
public class MyStack {
public static void main(String[] args) {
// TODO Auto-generated method stub
GStack<String> stringStack = new GStack<String>();
stringStack.push("seoul");
stringStack.push("busan");
stringStack.push("LA");
for(int n=0; n<3; n++)
System.out.println(stringStack.pop());
GStack<Integer> intStack = new GStack<Integer>();
intStack.push(1);
intStack.push(3);
intStack.push(5);
for(int n=0; n<3; n++)
System.out.println(intStack.pop());
}
}
//result
LA
busan
seoul
5
3
1[주의]
- 제네릭에서는 제네릭 타입으로 배열 생성 불가
Gstack ref = new Gstack- 위와 같이 작성할 수 없음(원칙)
- 따라서 Object 라는 데이터 타입을 이용하여 배열을 생성해야한다.
- Object 데이터 타입)
- 모든 데이터 타입의 최상위 클래스!
- Object 클래스를 이용하여 제네릭 타입 대신 배열을 생성한다
- Object 데이터 타입)
[풀이]
- 쌓을 수 있는 양을 10개로 지정
- 정보를 10개를 추가(push), 꺼내기(pop) 가능
- pop 으로 실제 정보가 삭제되는건 아님
- top of stack : tos -> 스택에 몇개가 쌓였는지 확인 가능
- tos == 10 개 쌓으면 더이상 쌓을 수 없음 -> return
- tos == 0 개면 꺼낼게 없으므로 null 리턴
바뀐코드
class GStack<T>{
int tos;
Object [] stck;
public GStack() {
tos = 0;
stck = new Object[2]; //추기 -> 2 로 변경
}
public void push(T item) {
if(tos == 2) { //추기 -> 2 로 변경
System.out.println("Stack is full, Unable to save[" + item + "]"); //추기
return;
}
stck[tos] = item;
tos++;
}
public T pop() {
if(tos == 0) {
System.out.println("Stack is empty:"); //추기
return null;
}
tos--;
return (T)stck[tos]; //stck[tos] 의 해시 코드 리턴
}
}
public class MyStack {
public static void main(String[] args) {
// TODO Auto-generated method stub
GStack<String> stringStack = new GStack<String>();
stringStack.push("seoul");
stringStack.push("busan");
stringStack.push("LA");
System.out.println("--1. Content stored in the stack --"); //추기
for(int n=0; n<2; n++) //3 을 2 로 수정
System.out.println(stringStack.pop());
System.out.println(); //추기
GStack<Integer> intStack = new GStack<Integer>(); //동적인 메모리 영역에 현재 설계한 Gstack 객체 매모리를 확보
// 기본 생성자가 자동 호출되어
// tos 가 0으로 초기화, oBject 객체가 관리하는 2개의 배열 참조 공간을 생성하고, 배열을 관리할 수 있는 stack[] 참조변수로 할당
intStack.push(1);
intStack.push(3);
intStack.push(5);
System.out.println("--2. Content stored in the stack --"); //추기
for(int n=0; n<3; n++)
System.out.println(intStack.pop());
}
}
//result
Stack is full, Unable to save[LA]
--1. Content stored in the stack --
busan
seoul
Stack is full, Unable to save[5]
--2. Content stored in the stack --
3
1
Stack is empty:
null[바뀐코드 풀이]
GStack<String> stringStack = new GStack<String>();- T 는 String 으로 변경
- 스택을 쌓을 수 있는지 확인,
- item 은 참조변수, item 은 참조 값을 스택 0번 요소에 제공 -> 스택 0번요소는 "seoul" 에 접근 가능
- tos 값 하나 증가 , tos=1
- push 함수의 역할이 다 끝나서 다시 되돌아 가, 다음 라인 수행
- StringStack 이 관리하는 영역에 push 를 호출, busan 이라는 item 이라는 참조 변수가 관리하게 되고
- 다시 검사 진행, 1번 인덱스 요소의 정보를 item(="busan")의 참조변수값 제공하여 스택 1번이 문자열 busan 관리 가능(반복)
- LA 를 push 하려고 해서 item="LA" 를 넣고, 값을 추가할 수 있는지 체크했더니, tos = 2 이기 때문에
스택이 찾다는 안내 구문 나옴 - return 만 사용하면 호출한곳으로 그냥 되돌아가기
- stringStack 영역이 관리하는 곳으로 가서 스택에 있는 내용을 2번 pop 하기 위해 tos 값 확인, 0 인지 확인
아니면, tos 값 감소 (tos : 2->1) - 참조가 리턴, 그 다음 1번 인덱스 정보로 가서 문자열을 리턴
- 반복 후 tos = 0 이먄 스택이 비었다는 내용 출력하는데, 반환된 null 출력
(정말 중욯하기 떄문에 메모리 변화를 세세하게 설명해주심)
제네릭과 배열
- 읽어보기
- 제네릭 메소드 선언 가능
- 클래스만 제네릭 기법을 사용할 수 있는줄 알았는데? 메소드도 제네릭 기법으로 만들 수 있다

- 제네릭 메소드를 호출할 때는 컴파일러가 메소드의 인자를 통해 이미 타입을 알고 있으므로 타입을 명시하지 않아도 됨

예제 7-10

따로 설명 안함, 우리가 해보기
분석하는 코드로 과제 나감
과제 피드백
[과제 일부 7-2. 7-8]
7-2
length 가 1보다 크면 Not character 라고 해서 return 종료하도록 하고
알파벳 범위에 있는지 설정하고, 그 범위를 벗어나면 Invalid 출력하도록
switch 로 ch => case = A 로 접근
7-8
해시맵을 활용하는 방법
똑같은 이름이존재하면 해당 정보를 업데이트 부분이 중요

공부한 것 기록용