발생 환경
- CDC를 위해서 AWS RDS에 Source connector를 연결해두었음
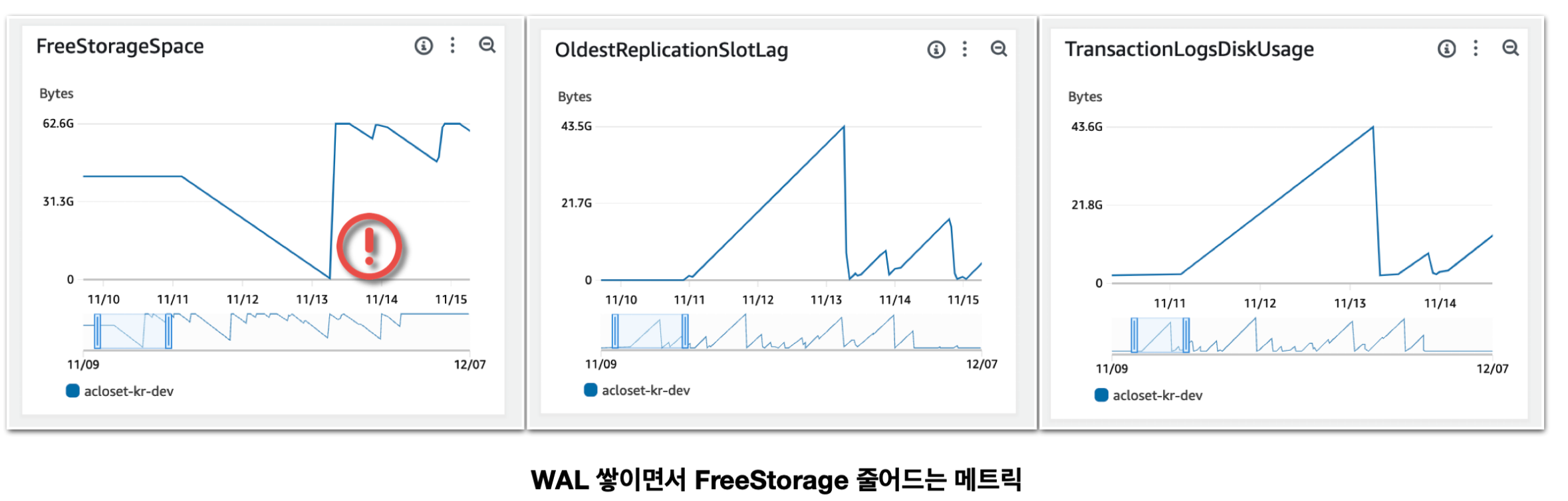
- 트래픽이 작은 환경 (Dev/QA) 에서만 DB의 WAL 쌓이다가 storage 부족으로 DB가 down되는 현상이 발생
OldestReplicationLag/TransactionLogsDiskUsage vs FreeStorageSpace
처음에는 Production환경에서는 문제가 생기지 않는데, dev/qa 환경에서만 불시에 생기고 Storage가 계속해서 선형적으로 줄어들었다. CDC를 붙이고서 부터 해당 현상이 발생했기에 관련이 있다고 생각하여 조사를 하기시작했다.
뭔가 OldestReplicationSlotLag/TransactionLogsDiskUsage와 FreeStorageSpace가 관련이 있어보였다. OldestReplicationSlotLag/TransactionLogsDiskUsage란 무엇인가?
OldestReplicationSlotLag
_
OldestReplicationSlotLag- 지연 시간이 가장 긴 슬롯, 즉 프라이머리에 비해 가장 뒤처진 슬롯을 나열합니다. 이 지연은 읽기 전용 복제본뿐만 아니라 연결에도 관련될 수 있습니다.
TransactionLogsDiskUsage
_WAL 데이터에 얼마나 많은 스토리지가 사용되고 있는지 보여줍니다. 읽기 전용 복제본이 크게 지연되면 이 지표의 값이 크게 증가할 수 있습니다.
https://docs.aws.amazon.com/ko_kr/AmazonRDS/latest/UserGuide/USER_PostgreSQL.Replication.ReadReplicas.html
처음 듣는 개념인데, primary랑 따라가지 못하는 슬롯 중 가장 뒤처진 슬록을 말한다고 한다. 이 슬롯(slot)도 모르겠고, 읽기 전용 복제본도 잘 모르는 개념이다.
slot
_물리적 복제 슬롯은 소스 DB 인스턴스가 모든 읽기 전용 복제본에서 WAL 데이터를 사용하기 전에 WAL 데이터를 제거하지 못하도록 합니다. 각 읽기 전용 복제본은 소스 DB 인스턴스에 자체 물리적 슬롯이 있습니다. 슬롯은 복제본에 필요할 수 있는 가장 오래된 WAL(논리 시퀀스 번호(LSN)별)을 추적합니다. 모든 슬롯과 DB 연결이 지정된 WAL(LSN) 이상으로 진행된 후에는 해당 LSN이 다음 체크포인트에서 제거할 수 있는 후보가 됩니다.
https://docs.aws.amazon.com/ko_kr/AmazonRDS/latest/UserGuide/USER_PostgreSQL.Replication.ReadReplicas.html
읽기 전용 복제본
읽기 전용 복제본은 DB 인스턴스의 읽기 전용 사본입니다. 애플리케이션에서 읽기 전용 복제본으로 쿼리를 라우팅하여 프라이머리 DB 인스턴스의 로드를 줄일 수 있습니다. 이렇게 하면 읽기 중심의 데이터베이스 워크로드에 대한 단일 DB 인스턴스의 용량 제한에서 벗어나 탄력적으로 스케일 아웃할 수 있습니다.
읽기 전용 복제본이란, 사본을 떠서 스케일 아웃을 하기 위해서 사용하는 복제 DB라고 보면 된다. 그럼 slot은 WAL 데이터가 사용하기 전에 사라지면 안되기 떄문에 제거하지 않도록 유지해주는 물리적 공간인가보다.
LSN이란,
The
pg_lsndata type can be used to store LSN (Log Sequence Number) data which is a pointer to a location in the WAL. This type is a representation ofXLogRecPtrand an internal system type of PostgreSQL.
pg_lsn데이터 타입은 LSN(Log Sequence Number)를 저장하기 위해서 사용된다. LSN은 WAL 위치를 가리키는 포인터다.XLogRecPtr와 동일한 타입이다. 64 bit 정수다.
위에 알아본 바로는 복제본이 가져가지 않은 LSN부터 슬롯은 계속 저장을 하고 있다. 그래서 위에 메트릭으로 알 수 있는 것은 복제본에서 가져가지 않았다는 것을 알 수 있다. 여기서 말하는 복제본은 source connector를 의미한다.
Source Connector는 왜 WAL 가져가지 않는가?
source connector 동작 원리
내가 사용한 source connector는 debezium을 사용하였다. PostgeSQL의 logical decoding 은 version 9.4에서 도입되었다. 트랜잭션 로그에 커밋된 변경 사항을 추출하고 출력 플러그인을 사용하여 사용자 친화적인 방식으로 이러한 변경 사항을 처리할 수 있는 메커니즘입니다 .
커넥터는 insert, update, delete operation에 대해서 행 수준으로 변경 이벤트를 생성하고 각 테이블 단위로 카프카 토픽에 전송한다.
insert, update, delete operation에서만 이벤트를 생성하면 당연히 트래픽이 낮은 환경의 db 경우에는 이벤트 생성없이 지연될 것이다. 그래서 Lag가 계속 쌓일 것이다.
WAL disk space comsumption
debezium 공식 문서에서도 이런 문제에 대해 자세하게 적혀있다.
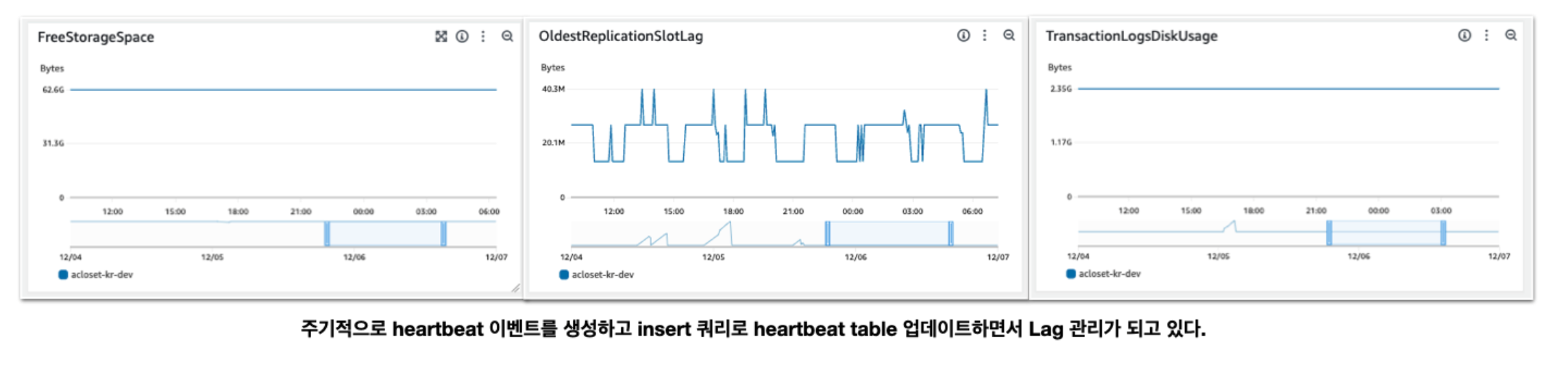
- 하트비트 이벤트 사용:
heartbeat.interval.ms커넥터 설정을 통해 주기적인 하트비트 이벤트를 생성합니다. 이것은 데이터베이스에 변경 사항이 적은 경우에도 Debezium이 계속해서 LSN을 확인하고 데이터베이스가 필요하지 않은 WAL 공간을 회수하도록 합니다. - pg_replication_slots 모니터링:
confirmed_flush_lsn과restart_lsn값을 모니터링하여,confirmed_flush_lsn이 지속적으로 증가하고restart_lsn이 뒤처지지 않는지 확인합니다. 이를 통해 데이터베이스가 적절히 공간을 회수하고 있는지 감시합니다. - 하트비트 테이블 추가: PostgreSQL 퍼블리케이션에 하트비트 테이블을 추가합니다. 이를 위해
ALTER PUBLICATION <publicationName> ADD TABLE <heartbeatTableName>;명령어를 사용하여 하트비트 테이블을 퍼블리케이션에 포함시킵니다. - 주기적인 데이터베이스 업데이트: 하트비트 또는 다른 방법을 통해 데이터베이스에 주기적으로 변경 사항을 발생시켜 Debezium이 최신 LSN을 확인하고 데이터베이스가 WAL 공간을 회수할 수 있도록 합니다.
- 적절한 설정 조정: Debezium 및 PostgreSQL 설정을 적절히 조정하여, 데이터베이스가 효율적으로 디스크 공간을 관리하고 필요하지 않은 WAL 파일을 정리할 수 있도록 합니다.