사내 서비스에서 최근 본 아이템을 조회하는 섹션이 있다. 이를 어떻게 설계하여 pagination을 했는지에 대한 포스팅을 하려고 한다.
여러 플랫폼들의 최근 본 상품 섹션
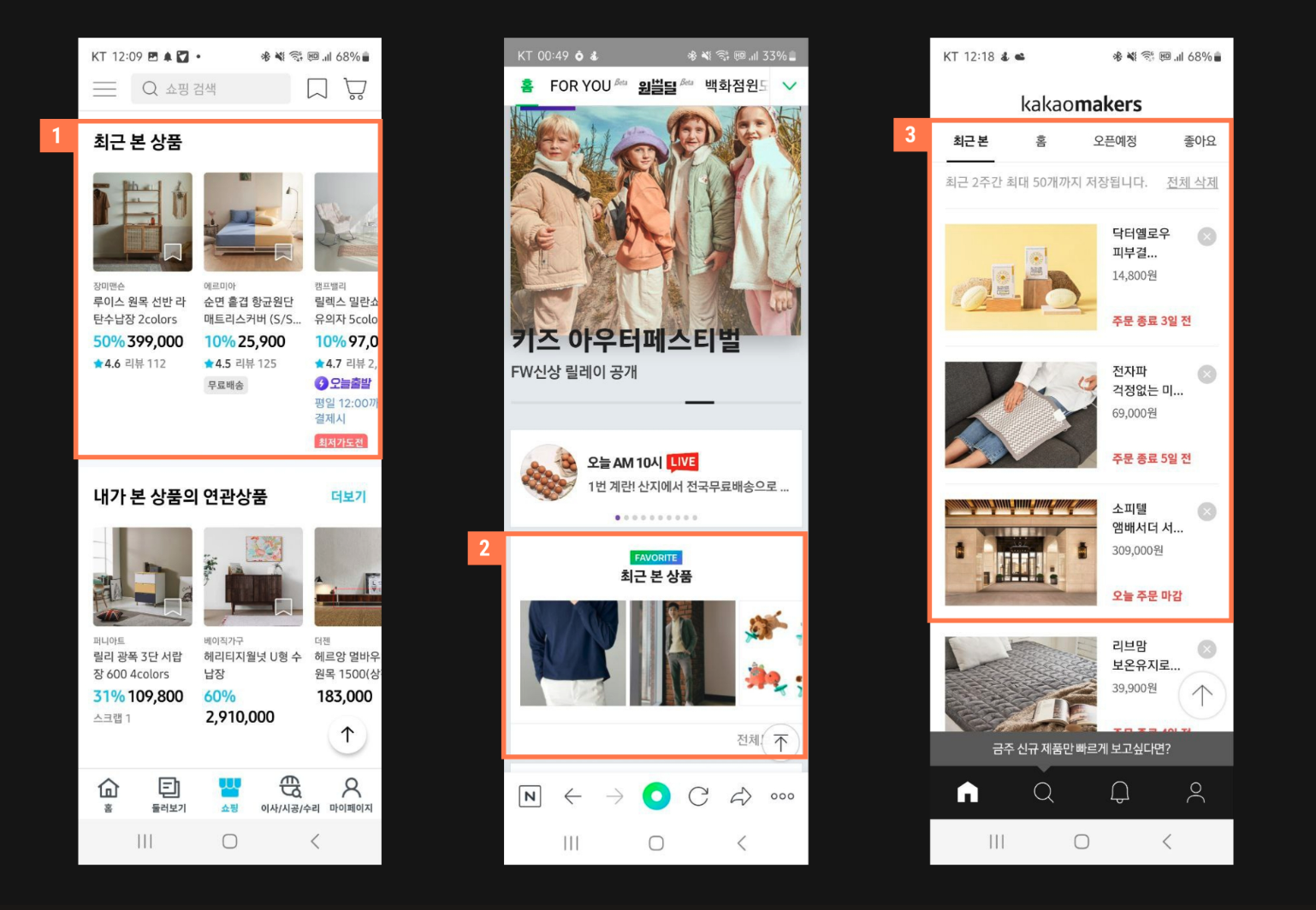
(출처 : https://maily.so/tipster/posts/5a152a48)
이를 클라이언트에서 아이디를 들고 있는 방식이나, 서버에서 Redis에 저장해서 관리하는 방식이 있을 것이다.
클라이언트에서 들고 있으면, 따로 디비에 저장하지 않아서 저장 비용측면에서 좋은면이 있지만, 앱을 지우거나, 아이템이 삭제된 경우에 대한 처리를 해야할 수도 있다. 그래서 서버에서 처리하는 것으로 결정했다.
기존
기존에는 아래와 같은 방식으로 구성했었다.
Key: {domain}:{sumdomain}:{userID}
Value: marketItem{아이템 ID, createDate}의 리스트를 마샬링

문제점
1. 아이템 배열을 코드로 직접 관리해야하는 비효율과 성능 저하
이렇게 구현을 하니 작동은 되지만, 사용자가 상품 상세를 볼 때마다, redis에서 리스트를 가져와서 리스트를 돌면서 이미 리스트에 있는 상품이면 해당 아이템을 삭제하고 리스트에 첫번째에 넣어주는 작업을 해야했기에 리스트의 길이가 길면 매우 비효율적인 작업이 진행된다.
2. offset/limit 문제
서비스 중에서는 상세 페이지에서 다른 상품을 추천해주는 서비스가 있다.
아이템 2 상세페이지에서 다른 상품을 보고 뒤로 가기를 하면 문제가 될 수 있다.
=> 흔히 offset limit 기법은 새로운 아이템의 추가/삭제시 문제를 야기한다고 한다. (https://binux.tistory.com/148)
새로운 아이템 생성 (아이템 103)
- 아이템 1번이 중복되어 서빙

기존 아이템 삭제
- 아이템 3번이 서빙되지 못한다.

3. 동시성 문제
Get - 배열 순서 변경 - Set 을 atomic하게 처리해야하는 문제도 있다.
개선
1. pagination 개선
Naver, Twitter의 pagination 방식을 찾아보았다. 대부분 cursor-pagination으로 구현되어있는 것으로 확인했다.
https://developers.worksmobile.com/kr/docs/pagination
https://developer.twitter.com/en/docs/twitter-api/pagination
2. Sorted Set 자료구조 적용
- 추가적으로 최근 본 아이템 조회를 흔히 redis의 sorted set 자료구조를 사용하여 구현한다.
-
Redis 자료구조 중 하나
-
Key-Member 값을 중복 허용하지 않고, Score 기준으로 정렬해준다.
-
ZADD Key, Member, Score를 추가
-
ZRANGE, ZRANGEBYSCORE 범위 조회도 가능
-
ZINCRBY score를 더하거나 빼거나 할 수 있음
-
Sorted set에서의 아이템 하나 추가당 시간 복잡도는 O(log(N)) 이다. 하나의 set당 최대 2^32 - 1(약 40억)개의 아이템을 저장 할 수 있다.
-
이러한 특징으로, 실시간 순위나 통계, 최근 본 상품에 많이 쓰인다고 한다.
XX: Only update elements that already exist. Don't add new elements.
NX: Only add new elements. Don't update already existing elements.
LT: Only update existing elements if the new score is less than the current score. This flag doesn't prevent adding new elements.
GT: Only update existing elements if the new score is greater than the current score. This flag doesn't prevent adding new elements.
CH: Modify the return value from the number of new elements added, to the total number of elements changed (CH is an abbreviation of changed). Changed elements are new elements added and elements already existing for which the score was updated. So elements specified in the command line having the same score as they had in the past are not counted. Note: normally the return value of ZADD only counts the number of new elements added.
INCR: When this option is specified ZADD acts like ZINCRBY. Only one score-element pair can be specified in this mode.
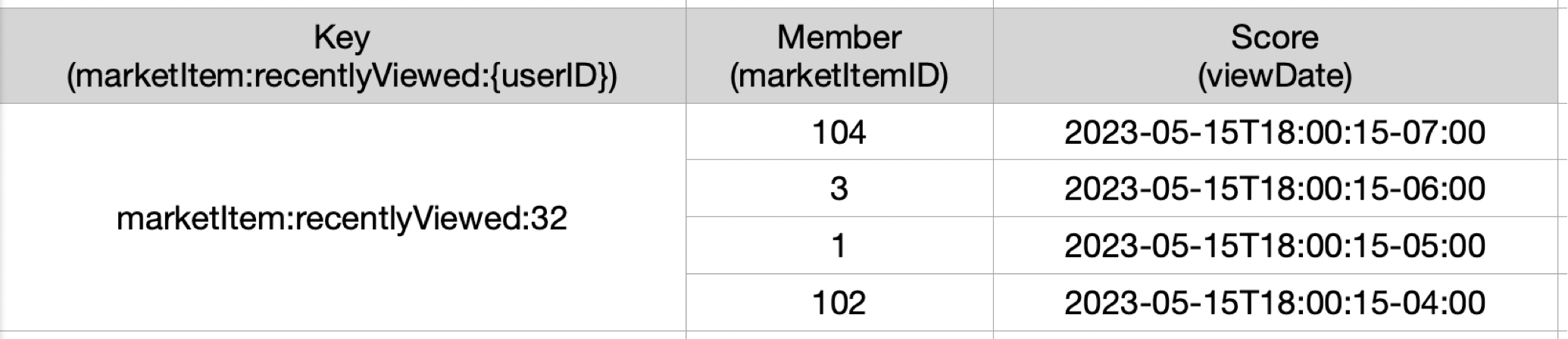
쉽게 설명하고자 예시를 가져왔다.
user가 가진 최근 아이템은 중복으로 값이 들어가지 않고 score가 overwrite된다. 그리고 score(viewDate)는 정렬이 되어있어서, 오름차순, 내림차순, score 기준으로 min max 설정을 하여 조회할 수 있기 때문에 최근 본 상품 조회 피쳐를 구현하기에 적합해 보인다.
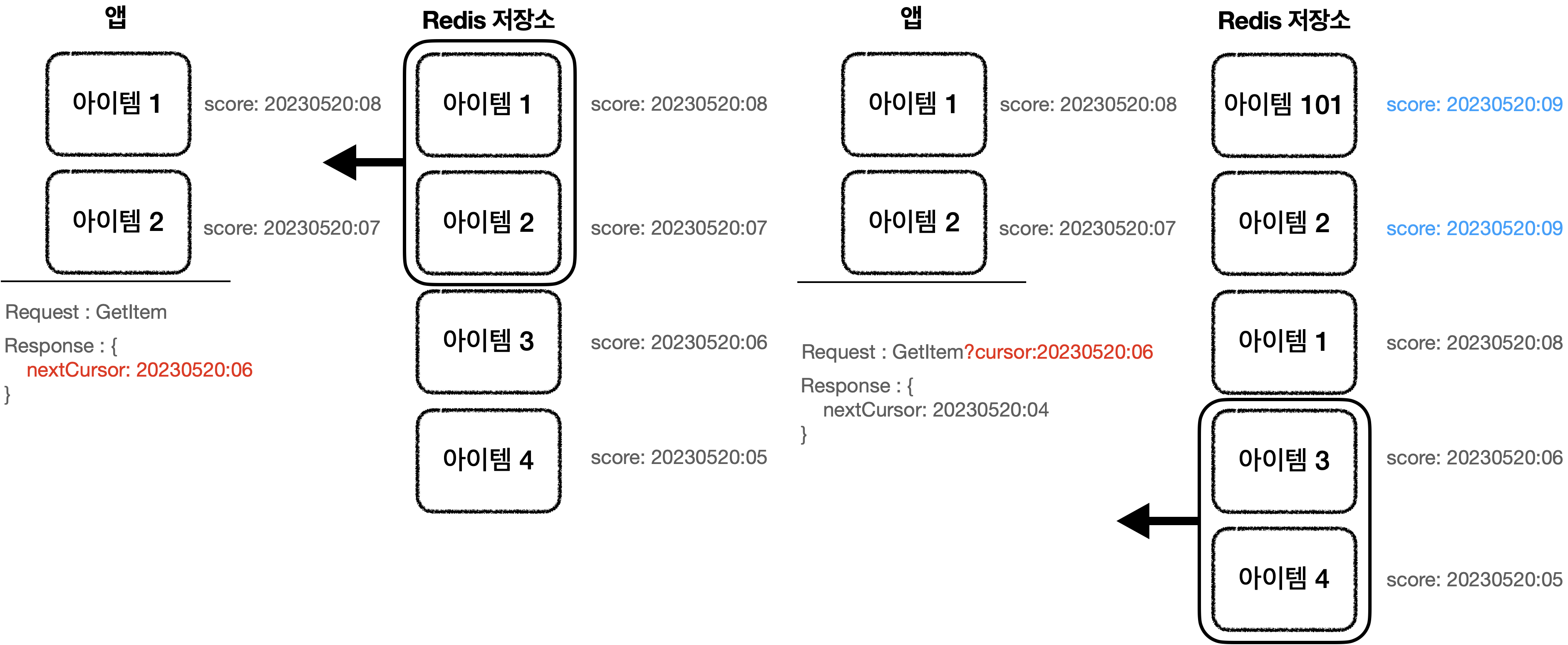
redis sorted set 자료구조와 cursor pagination을 통해서 최근 본 상품을 쉽게 구현할 수 있다.

Get 요청을 하면 response에 nextCursor를 내려준다. 이는 내려줬던 viewDate를 의미한다. 다음 페이지를 요청할 때, nextCursor를 query string으로 요청하면 해당 상품부터 내려주게 된다.
그러면 이 방식은 데이터 생성/삭제에도 어떻게 데이터 일관성 문제를 해결할 수 있을까?
갑작스럽게 101번 아이템을 보게된 경우에도 score가 현재일시로 변경되고, next cursor에 해당하는 날짜부터 조회를 하기 때문에 문제가 되지 않는다.
마지막으로,,,
maxItemSize, TTL도 아래와 같은 방식으로 가능하기 때문에 서비스에 활용하면 좋을 듯 하다.
maxItemSize : zremrangebyrank market:view:1513035 0 -4
log(N) * M // N은 sorted set 원소 갯수, M 삭제 갯수
TTL : zadd myzset (get key) ex 10
최근 피드 좋아요 많은 유저 순위 역시 다음과 같은 방식으로 구현한다고 하면 materialized view를 하지 않고 실시간 순위를 뽑을 수 있을 것이라 생각한다.
느낀점
- 여러 제품의 자료구조를 익히고 장단점을 파악하고 있어야 적재적소에 사용할 수 있다.
참고
https://redis.io/docs/data-types/sorted-sets/
https://developers.worksmobile.com/kr/docs/pagination
https://developer.twitter.com/en/docs/twitter-api/pagination
https://server-talk.tistory.com/485
https://binux.tistory.com/148
https://www.joinc.co.kr/w/man/12/REDIS/RedisWithJoinc/part04
http://redisgate.kr/redis/configuration/internal_skiplist.php
https://ict-nroo.tistory.com/133
