
처음 스프링 배치를 접한건 인턴십 때 였다. 인턴십과정에서 웹을 만드는 작업을 하였는데 그 중에서 스프링배치를 이용하는 부분이 있었다. 당시에 스프링배치가 무엇이고 어떤 기능에 배치를 적용시켜야 할지 모르는 부분이 많았다. 개념을 잘 정리해주신 블로드도 많이 있지만 내 생각과 느낌을 정리하기 위해 포스트를 한다!
간단한 개념만 정리 할 것이고 적용은 아래 링크를 통해 포스트를 참고하길 바랍니다.
스프링 배치 적용(1)
스프링 배치 적용(2)
📌 Spring Batch
배치프로그램이란?
배치(batch) 프로그램이란 어떠한 데이터를 일괄적으로 모아 처리하는 작업을 의미한다. 이러한 작업을 정기적으로 반복하거나 규칙에 따라 수행한다.
배치 프로그램의 특징
- 대용량 데이터
- 대량의 데이터를 가져오거나, 전달, 계산 등의 처리를 할 수 있어야 한다. - 자동화
- 사용자의 개입없이 일정한 시간, 규격에 맞추어 자동적으로 실행 할 수 있어야 한다. - 견고성
- 잘못된 데이터를 충돌이나 중단 없이 처리할 수 있어야 한다. - 신뢰성
- 배치 실행도중 무엇이 잘못되었는지 추적할 수 있어야 한다. - 성능
- 지정한 시간안에 처리를 완료하거나 동시에 실행되는 다른 어프리케이션을 방해하지 않아야 한다.
Spring Batch란?
이러한 대용량의 자료를 처리하는데 쓰이는 일괄처리를 지원하는 프레임워크로서 Quartz기반으로 동작한다.
🖊Job의 구성
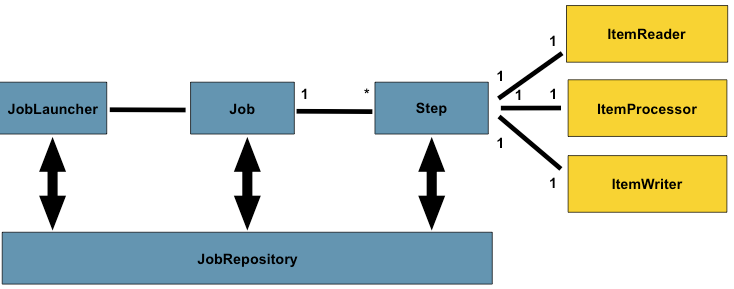
이미지 출처: https://docs.spring.io/spring-batch/trunk/reference/html/domain.html
Job이란?
Job은 배치잡업의 과정을 하나의 단위로 만들어 놓은 객체이다. 배치를 구성할 때 가장 상단에 위치한다.
JobInstance
JobInstances는 Job의 실행단위 이다. 배치가 실행되면 하나의 JobInstance가 생성된다.
JobParameters
JobParameters는 String, Long, Double, Date로 총 4개의 형식을 지원하며, JobInstance를 구별짓는 파라미터 이다.
JobExecution
JobExecution은 JobInstance가 실행될 때 시작시간, 종료시간, 생성시간, 상태 등의 정보를 담고 있다.
🖊 Step
Step이란?
Step은 Reader, Processor, Writer의 묶음이다. Job은 최소 한개 이상의 Step을 가져야한다.
StepExecution
StepExecution은 Step실행 시도에 대한 객체이다. 한 Step이 실패하게 되면 다음 단계로 넘어가지 않는다.
ItemReader
ItemReader는 배치를 실행할 데이터를 읽어오는 인터페이스이다. 많은 종류의 Reader가 존재한다.
ItemProcessor
ItemProcessor는 Reader에서 읽어온 데이터를 가공하는 단계이다. Processor는 필수 요소는 아니고 생략이 가능하다.
ItemWrtier
ItemWriter는 Reader에서 읽어오거나 Processor에서 처리된 데이터를 Write하는 인터페이스이다. 보통 Chunk단위로 묶엇 진행한다.
🖊 Chunk, Tasklet이란?
Spring Batch에는 Chunk지향과 Tasklet처리 방식이 존재한다. 둘의 차이는 처리하는 데이터를 나눌것인가에서 차이가 발생한다. Chunk지향 방식은 ChunkSize라는 것을 통해 데이터를 처리할 갯수를 미리 설정해 둔다. 반면 Tasklet방식은 한번에 데이터를 처리하는 과정이다. 상황에 따라 쓰이는 방식이 다르지만 실무에서는 많은 데이터를 처리 하기 때문에 Chunk지향 방식을 지향한다.
🖊 ChunkSize 와 Paging Size
Setting a fairly large page size and using a commit interval that matches the page size should provide better performance.
페이지 크기를 상당히 크게 설정하고 페이지 크기와 일치하는 커밋 간격을 사용하면 성능이 향상됩니다.
위와 같이 스프링에서는 ChunkSize와 PagingSize를 동일하게 하는것을 권고 한다. 만일 두 값이 다르다고 문제가 되진않지만 효율성이 떨어진다. 만약에 ChunkSize가 20, PagingSize가 10이면 한번의 Read에서 10개의 데이터를 가져오게 된다. ChunkSize가 20이므로 총 두번 Read를 하고 1번의 Transaction이 수행된다.
🖊 Spring Batch vs Scheduler?
처음에 스프링 배치를 접하고 조금 헷갈렸던 개념이다. Scheduler은 Spring Batch를 실행시키는 메소드이므로 비교대상이 아니다.
