Daily plan
- 개인별 데이터 살펴보기 - 데이터 전처리(이상치, 결측치 처리), price와 컬럼 간 상관관계 인사이트 도출, 시각화 등
- 13시 중간점검
- 14시 머신러닝 특강
- 19시 팀회의

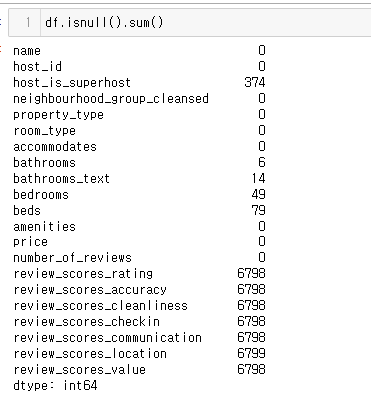
컬럼 확인 및 전처리
-
host_is_superhost
- 결측치
airbnb에서 규정한 superhost 기준이 몇가지 있는데, 데이터 내에서 충분히 확인 가능할 것 같아서 결측치인 행들에 대해 해당 기준을 충족하는지 확인한 후 채워넣으면 되지 않을까.....?라고 생각했지만....!
전체 데이터 22000개 중 374개는 약 1.7% 밖에 안되는 수치이니까 제거해버려도 되지 않을까....?
근데 애초에 이 컬럼이 필요할지 아닐지도 확실하지 않다.
- 결측치
-
bathrooms & bathrooms_text
- 결측치
이건 결측치가 워낙 적기도 하고 bathrooms_text의 결측치 중 일부는 bathrooms 데이터로 채울 수도 있어서 채울 거 채운 뒤 제거하는걸로! - 텍스트 처리
bathrooms는 욕실 개수라서 그대로 사용하면 될 거 같은데
bathrooms_text는 욕실 개수 + private/shared 유무도 함께 담겨 있다.
그래서 private인지 아닌지를 분류하는 새로운 컬럼을 만들기로 했다.
근데 private/shared가 적혀있지 않은 경우도 꽤 많아서 이 부분을 어떻게 처리할지 고민이긴 한데, 일단 숙소 유형(property type)을 확인해서 상식선에 맞게 임의로 분류하는 방식을 선택했다.
예를 들어서 숙소 유형이 entire house라면, 집 하나를 대여하는 거니까 욕실도 private으로 분류할 수 있다.
- 결측치
-
bedrooms & beds
- 결측치
몇개 없으니까 걍 삭제 해버릴게여.... - 이상치
이상치도 좀 잡아야될 거 같긴한게,, 무슨 침실이 15개고 침대가 42개래.. 관광객은 그정도로 필요없는걸료..
아마 tower 같은 숙소 유형을 쳐내면 이런 것도 같이 쳐지지 않을까....?
- 결측치
-
review_scores__
- 결측치
결측치가 6800개 정도로 전체 데이터 중 30%를 차지하는데,, 이건 꽤나 큰 비율이라 함부로 제거하면 안될거 같아서 고민이다 ㅜ.ㅜ
이건ㅈ 나중에 머신러닝 돌릴 때 이 컬럼들을 사용한다면- 중간값 ver.
- 최빈값 ver.
- 결측치 제거 ver.
등 여러 가지 버전으로 돌려보기로 했다.
- 결측치
-
amenities
- 이 자식이 문제야 이 자식이....
- 중복되는 키워드 중심으로 열심히 줄이고 줄여서 5757개를 199개까지 줄였다.
- 전체 어메니티 개수와, 카테고리별 & 주요 어메니티 분류해서 각각의 유형에 포함되는 어메니티 개수도 따로 변수로 만들어 주었다.
- 근데 키워드 변환하는 과정에서 누락된 게 많은지 제대로 변환이 안된 거 같음ㅜㅜ
그말인즉슨 코드를 다시 점검해야 한다는 건데... 코드 보기 싫어서 뻐팅기는 중ㅋ - 내일 아침의 나에게 맡기겠다,,
- 근데 사실 얘가 price와 유의미한 상관관계를 가질지도 잘 모르곘다,, 단순히 개수로 카운팅하기에 그 안에 들어있는 정보들이 너무 디테일하다. 그래도 일단 전처리 해놓고 모델을 돌려봐야 긴지 아닌지 알 수 있겠지,,
내일은 시각화와 통계 분석에 좀 더 많은 시간을 써야겠다. 그러려면 전처리를 빨리 끝내야겠지..허허
울분터진김에 욕심 대방출 했다가 살해당할 뻔했다,,
개인공부보다 플젝이 재밌긴한데,, 확실히 쉽지 않긴 하네...^^
5조 화이팅 !
