Daily plan
🌞오전
- 코드카타 SQL 5문제
- 데일리 스크럼
- 빅분기 강의 2과목🔥 오후
- 데이터분석 파이썬 강의 3회차 + 4회차
- TIL에 오늘 배운 내용들 정리🌝 저녁
- 데일리 스크럼 + TIL 제출
- 남은 시간 코드카타 풀이SQL 코드카타
Q48 - 즐겨찾기가 가장 많은 식당 정보 출력하기

이 문제로 거의 3~40분을 끙끙거렸는데, 마침 오늘 SQL 라이브세션에서 이 내용을 다뤄주셨다..!! 타이밍 웬말이야,, 감사합니다ㅜㅜ
- GROUP BY를 잘못 이해하고 있었다.
- WINDOW 함수에 대해 잘 몰랐다.
-> WINDOW 함수 복습하면서 한번 더 정리해야겠다.
Q49 - 식품분류별 가장 비싼 식품의 정보 조회하기

48번 문제랑 비슷한 맥락의 문제였다. 한번 더 풀어보니까 조금 더 이해할 수 있을 것 같긴한데, 나중에 다시 한번 정리해야겠다.
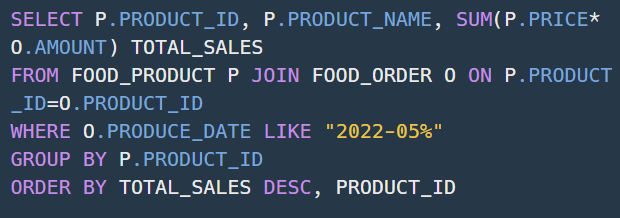
Q50 - 5월 식품들의 총매출 조회하기
Q51 - 없어진 기록 찾기
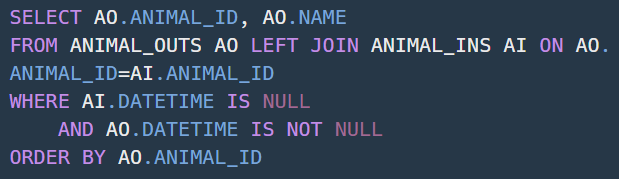
LEFT JOIN이 어떨 때 필요한 건지 이해할 수 있었다.
그냥 JOIN만 했더니 ANIMAL_INS에 없는 ANIMAL_ID에 대해서는 데이터가 나타나지 않아서 오류가 났다.
ANIMAL_OUTS 테이블을 기준으로 LEFT JOIN을 해야 ANIMAL_INS에 없는 ANIMAL_ID가 어떤건지 확인이 가능하다.
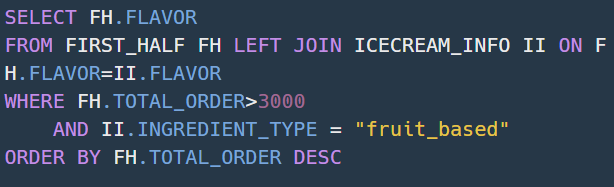
Q52 - 과일로 만든 아이스크림 고르기
SQL 라이브세션 (마지막 7회차...!)
1. WINDOW FUNCTIONS
(1) 정의 및 특징
- 행과 행 간의 관계를 정의하기 위해 제공되는 함수
- 여러 행의 관계를 파악하기 위해 사용하며, 분석함수 또는 순위함수로 알려져 있음
- 순위, 합계, 평균, 행 위치 등을 조작 가능
- 윈도우 함수는 GROUP BY 구문과 병행하여 사용할 수 없다!!!
- GROUP BY구문은 NULL값이 존재하는 ROW는 제외하고 산출하며 WHERE절 수행 후 실행됨
- GROUP BY 뒤에 오는 속성명은 반드시 SELECT문의 속성 중에 존재해야함
(2) 기본 문법
SELECT WINDOW_FUNC() OVER( PARTITION BY 컬럼 ORDER BY 컬럼 )
FROM 테이블명
(3) 종류
-
집계: SUM, MAX, MIN, AVG, COUNT
-> 집계함수만 GROUP BY 구문과 병행하여 사용 가능
-
순위: RANK, DENSE_RANK, ROW_NUMBER
- RANK: ORDER BY를 포함한 쿼리문에서 특정 컬럼의 순위를 구하는 함수
- PARTITION 내에서의 순위 OR 전체 데이터에 대한 순위
- 동일한 값에 대해서는 같은 순위를 부여하고 중간 순위를 비운 값이 출력됨
- DENSE RANK
- RANK와 작동법은 같지만, 동일한 값에 같은 순위를 부여하고 중간 순위를 비우지 않음
- ROW_NUMBER (가장 많이 사용됨)
- RANK, DENSE_RANK는 동일한 값에 동일 순위를 부여하지만 ROW_NUMBER는 동일한 값이어도 고유한 순위를 부여함
- RANK: ORDER BY를 포함한 쿼리문에서 특정 컬럼의 순위를 구하는 함수
-
순서: FIRST_VALUE, LAST_VALUE, LAG, LEAD
- FIRST_VALUE / LAST_VALUE
- 파티션 별 가장 먼저/마지막에 나온 값을 구하여 출력
- FIRST_VALUE는 처음 행만 가져오며 MIN함수를 쓰는 것과 동일하고, LAST_VALUE는 나중에 나온 행만 가져오며 MAX함수를 쓰는 것과 결과가 동일
- LAG
- 이전 N번째 행을 가져오는 함수로, 별도 명시가 없으면 기본값은 1
- 가져올 행이 없을 경우 DEFAULT값을 지정해주는 것으로, NVL이나 ISNULL 함수의 기능과 동일
- LEAD
- 이후 N행의 값을 가져오는 함수로, 별도 명시가 없으면 기본값은 1
- FIRST_VALUE / LAST_VALUE
-
비율: RATIO_TO_REPORT, PERCENT_RANK, CUME_DIST, NTILE
- RATIO_TO_REPORT
- 파티션 내 전체 SUM값에 대한 행별 백분율을 소수점으로 출력
- 결과값은 0~1 사이, 비율의 합은 1
- MySQL에서 지원하고 있지 않음!
- PERCENT_RANK
- 파티션별로 구간을 나누어 백분율을 출력
- (파티션 내 순위-1) / (파티션 내 전체 행 개수-1)
-> 순위는 RANK함수 기반
- CUME_DIST
- 파티션별 전체 건수에서 현재 행보다 작거나 같은 건수에 대한 누적 백분율 출력
- NTILE
- 파티션별 전체 건수를 계산한 값에 대해 N등분한 결과를 출력
- RATIO_TO_REPORT
2. WITH 구문
-
SQL 구문에서 사용되는 임시(가상)테이블
-
쿼리의 가독성 및 쿼리 성능의 향상을 목적으로 함
-
특징
- 임시테이블의 개념으로, 작성한 쿼리 내에서만 실행 가능
- 하나의 SQL 구문에서 여러 개의 WITH문 선언 가능
- 하나의 테이블에 대한 여러 조회가 필요할 때 WITH절을 사용하여 1회 조회 및 선언이 가능
- 복잡한 연산을 보다 효율적으로 처리 (EX. JOIN, UNION 등의 결과를 WITH문에 저장)
-
문법
WITH 임시테이블명 AS
(
SELECT 컬럼
FROM 테이블명
)
SELECT 임시테이블에서 필요한 컬럼
FROM 임시테이블명
3. 그 외 주요 함수들
String 함수
- CONCAT: 문자열을 병합할 때
- SUBSTRING: 문자열을 자를 때
- SUBSTRING_INDEX: 문자열을 특정 구분 기호로 출력할 때
- REVERSE: 문자열을 뒤집을 때 (특정 문자를 찾고자 할 때 이용하기도 함)
- LEFT, RIGHT: 문자열을 기준에서부터 N개 출력
Math 함수
- ABS: 절댓값
- ROUND: 소수점 이하 자릿수에서 올림
- CEILING, FLOOR: 소수점 올림, 내림
- TRUNCATE: 소수점 버림
- RAND: 지정 숫자 범위 중 하나를 랜덤으로 출력
- ROUND(RAND()* 100, 0) : 0~100 사이 랜덤값 출력
날짜 함수
- NOW / SYSDATE / CURRENT_TIMESTAMP: 현재 시간 및 날짜 출력
- DATE_ADD: 날짜에서 기준값만큼 덧셈하여 출력
- DATE_SUB: 날짜에서 기준값만큼 뺄셈하여 출력
- DATEDIFF: 두 날짜를 뺄셈하여 출력
- DATE_FORMAT: 날짜를 형식에 맞게 출력
- UNIX_TIMESTAMP: 현재 시간을 UNIXTIME으로 구함 (정수 출력)
- CURDATE / CURRENT_DATE: 현재 날짜 출력
- CURTIME / CURRENT_TIME: 현재 시간 출력
- YEAR, MONTH, DAY: 연도, 월, 일 출력
UNIXTIME (유닉스 시간)
- 운영체제 유닉스 등 컴퓨터에서 사용하는 시간 표현 방식 (UNIX TIMESTAMP라고도 함)
- UTC(협정 체계시) 기준 1970년 1월 1일 00:00:00로부터 몇 초가 지났는지 나타냄
아티클 스터디
양질의 데이터를 판별하는 5가지 방법 (2) 믿을 수 있는 데이터인가?
- 요약 : 데이터의 신뢰성에 영향을 주는 요인들
- 데이터 오류
- 사실이 아닌 잘못된 정보를 적재하는 경우
- 수집 당시의 오류와 데이터 조작 중 발생하는 오류로 구분 가능
- 결측 데이터
- 데이터 수집이나 적재 과정에서 누락된 데이터
- 제거하거나 다른 값으로 대체하는 등의 방법이 있지만, 결측 데이터가 많을수록 데이터의 신뢰성은 낮아짐
- 데이터 가공 정도 (원천 데이터 VS 가공 데이터)
- 가공하지 않은 원천 데이터는 보통 오류가 적은 편
- 복잡한 형식이나 내용을 가지는 경우가 많으므로, 때로는 최소한의 가공을 거친 데이터가 가장 신뢰성이 높을 수도 있음
- 가공을 할수록 신뢰성이 떨어지기 쉬움. 아무리 좋은 AI 알고리즘도 결국은 추정값, 예측값을 만들어내므로 많이 가공된 데이터는 틀린 정보를 담게 됨.
- 데이터 오류
- 주요 포인트 :
- 데이터 분석가는 반드시 분석 초기에 데이터를 꼼꼼히 살펴보고, 수집 방법을 파악해야 함
- 애초에 결측 데이터가 최대한 없는 데이터를 선택해야 높은 신뢰성을 가질 수 있음
- 원천데이터(신뢰성)와 가공데이터(활용성) 사이의 균형을 잘 잡는 것이 중요
- 허용 가능한 오류 정도를 명확히 정하고, 가공의 정도와 내용에 따라 데이터를 선택해야 함인사이트
데이터 분석을 공부하면서 캐글이나 공공데이터 등 비교적 깔끔하게 잘 정리된 데이터들만 다루어봤기 때문에 데이터를 준비하는 과정에 대해서는 크게 고민해보지 않았다. 하지만 데이터를 분석하는 과정만큼 데이터를 준비하는 과정도 아주 중요하고 번거로운 일이라는 것을 깨달았다. 분석을 잘 하기 위해서는 분석 초기에 데이터를 하나하나 꼼꼼히 살펴보고, 수집 방법을 파악하며 오류값, 결측값, 가공 정도 등도 주의 깊게 봐야 한다는 것을 명심해야겠다.
빅데이터분석기사
SQL에서 힘을 너무 빼서 그런지 강의가 듣기 싫어져서 오늘은 패스....^^;;
주말에 업보 청산 해야겠다.
데이터분석 파이썬 종합반(3),(4)
이것도 강의는 다 들었는데 정리하기가 싫어서 내일로 미뤄야겠다..ㅎ
일기
아침에 SQL 코드카타를 하면서 어제 못풀고 미뤄둔 문제가 생각보다 어려워서 당황했다. 슬랙 질문방에 역시나 똑같은 질문을 한 사람이 있었다. 튜터님 댓글을 보고 간신히 조금 이해를 했는데, 곧바로 SQL 라이브 세션에서 윈도우함수에 대해 강의하면서 그 문제에 대해 설명해주셨다. 내가 GROUP BY를 제대로 이해하지 못하고 있었고, 윈도우 함수에 대한 기본적인 지식이 부족해서 그 문제가 어려웠다는 걸 깨달았다. JOIN함수를 사용해서 해결하는 방식으로 일단은 이해를 했지만, 윈도우 함수를 이용해서 다시 답안을 작성해봐야겠다. (48, 49번)
저녁먹고 온 이후에 집중력이 완전히 나가리돼서 한시간은 딴짓하고, 한시간은 팀원들이랑 수다떨었다. 그 업보로 지금 뒤늦게 TIL 작성 중...^^:;
내일 있을 QCC가 약간 걱정되기도 하고 이번주안에 코드카타 60번까지 풀고 싶어서 오늘은 나머지 공부 좀 더 하다 자야겠다.
온보딩 주차 팀원분들도 매일 슬랙에서 소통을 해주셔서 너무 좋다. 뭔가 팀이 2개라 든든한 느낌?ㅎㅎ 앞으로 팀이 바뀔 때마다 이렇게 이전 팀들끼리의 소통도 유지되었으면 좋겠다. 온라인 세상이라 사람들이랑 친해지는 건 생각도 못했는데, 생각보다 다들 재밌고 활발하셔서 덕분에 부캠을 즐겁게 하고 있는 것 같다! 빨리 또 팀프로젝트 하고 싶어,,,
