
결국 지피티께 헌금 내는 엔딩,, 지피티는 신이야
1. 기본 분포 시각화
숙소 가격 분포
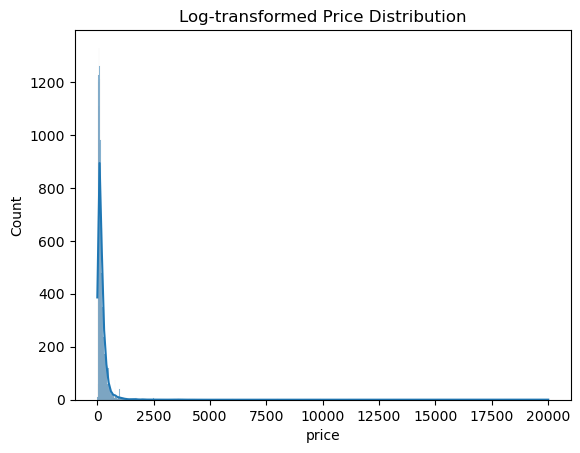
2만달러짜리 숙소 진짜 걍 삭제해버리고 싶다;;;;
1만달러 위로는 싹 날려버리고 싶음 진짜루ㅜㅜ
- 로그 씌운 버전
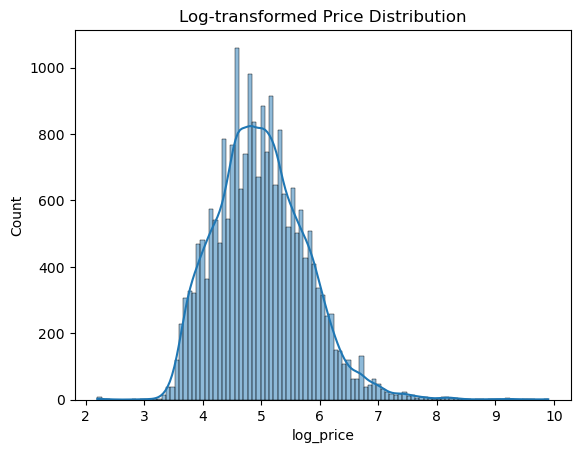
한결 편안,,,
숙소 유형별 가격 비교
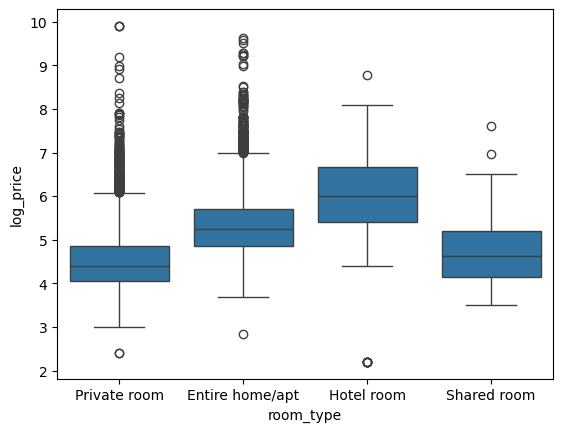
그치.. 아무래도 호텔이 비싸겠지...
room_type 없애기로 해서 필요없어졌지만ㅎ
슈퍼호스트 여부와 가격 비교
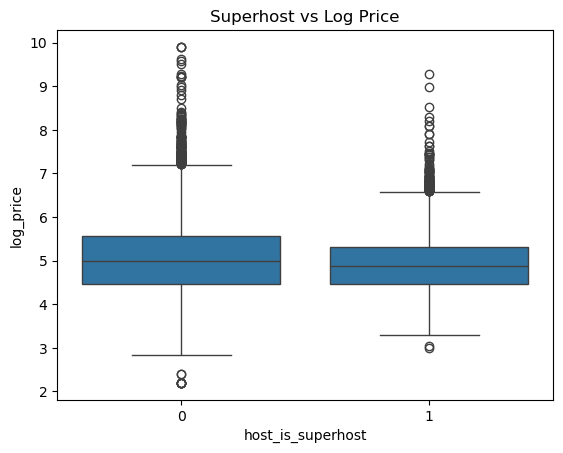
슈퍼호스트 여부가 중요한가...? 아직도 잘 모르겠음
2. 위치 정보 시각화
지역별 숙소 수, 평균 가격 등
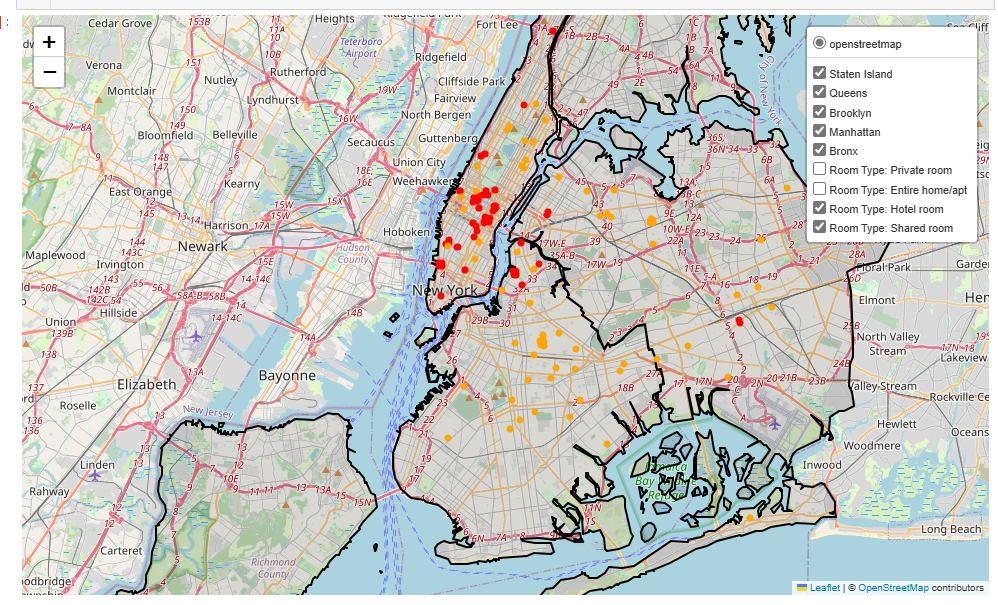
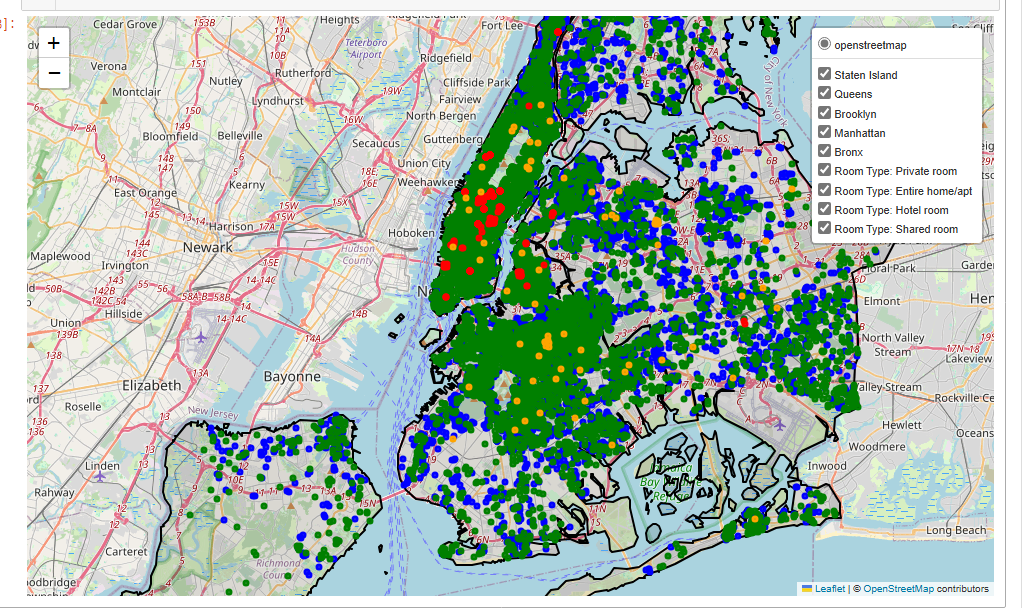
import folium
# 지도 생성
ny_map5 = folium.Map(location=center, zoom_start=11)
################################
# 고유한 property_type 확인
property_types = df['property_type'].unique()
# 색상 지정 (필요 시 더 추가 가능)
property_type_colors = {
'entire_home': 'green',
'private_room': 'blue',
'shared_room': 'orange',
'hotel_type': 'red',
'luxury_space': 'purple',
'unique_space': 'cadetblue',
'other': 'gray'
}
#################################
# 자치구 경계 추가
for feature in boundary_data['features']:
name = feature['properties']['name']
folium.GeoJson(
feature,
name=name,
tooltip=name,
style_function=lambda x: {
'fillOpacity': 0.1,
'color': 'black',
'weight': 2
}
).add_to(ny_map5)
# 고유 room_type 목록
room_types = df['room_type'].unique()
# 색상 지정 (더 추가 가능)
room_type_colors = {
'Entire home/apt': 'green',
'Private room': 'blue',
'Shared room': 'orange',
'Hotel room': 'red'
}
#################################
# room_type별 FeatureGroup 생성
for room in room_types:
group = folium.FeatureGroup(name=f"Room Type: {room}")
filtered = df[df['room_type'] == room]
for _, row in filtered.iterrows():
folium.CircleMarker(
location=[row['latitude'], row['longitude']],
radius=1.5,
color=room_type_colors.get(room, 'gray'),
fill=True,
fill_color=room_type_colors.get(room, 'gray'),
fill_opacity=0.4,
tooltip=f"{room} / {row['property_type']}"
).add_to(group)
group.add_to(ny_map5)
# 레이어 컨트롤 추가
folium.LayerControl(collapsed=False).add_to(ny_map5)
ny_map5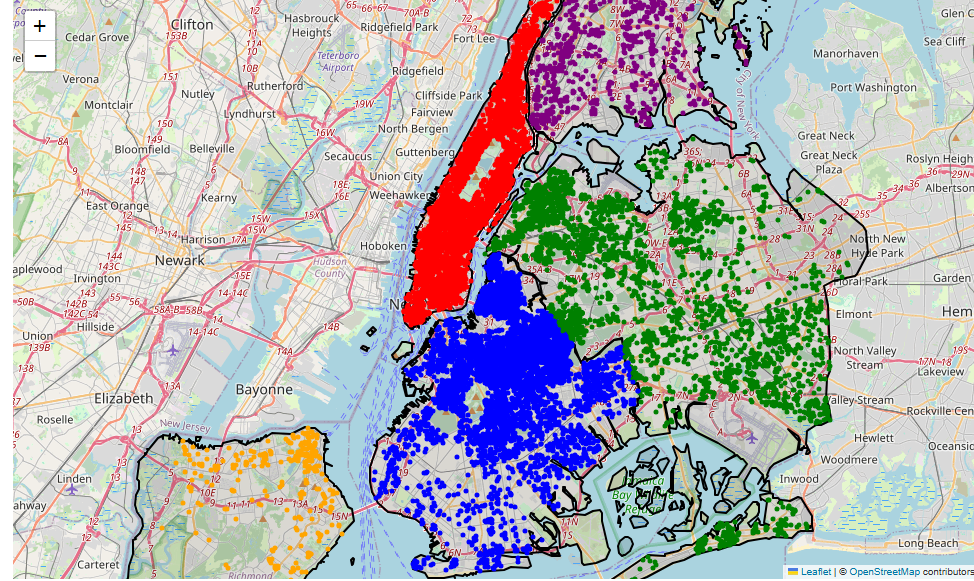
# 자치구별 색상 지정
borough_colors = {
'Manhattan': 'red',
'Brooklyn': 'blue',
'Queens': 'green',
'Bronx': 'purple',
'Staten Island': 'orange'
}
# 지도 초기화
ny_map3 = folium.Map(location=center, zoom_start=10.5)
# Borough 폴리곤 추가 ---
for feature in boundary_data['features']:
name = feature['properties']['name']
folium.GeoJson(
feature,
name=name,
tooltip=name,
style_function=lambda x: {
'fillOpacity': 0.1, # 폴리곤은 조금 투명하게
'color': 'black',
'weight': 2
}
).add_to(ny_map3)
# 자치구별 마커 찍기
for _, row in df.iterrows():
borough = row['neighbourhood_group_cleansed'] # 자치구 정보 컬럼
color = borough_colors.get(borough, 'gray') # 혹시 모를 예외처리
folium.CircleMarker(
location=[row['latitude'], row['longitude']],
radius=1,
color=color,
fill=True,
fill_color=color,
fill_opacity=0.3
).add_to(ny_map3)
ny_map3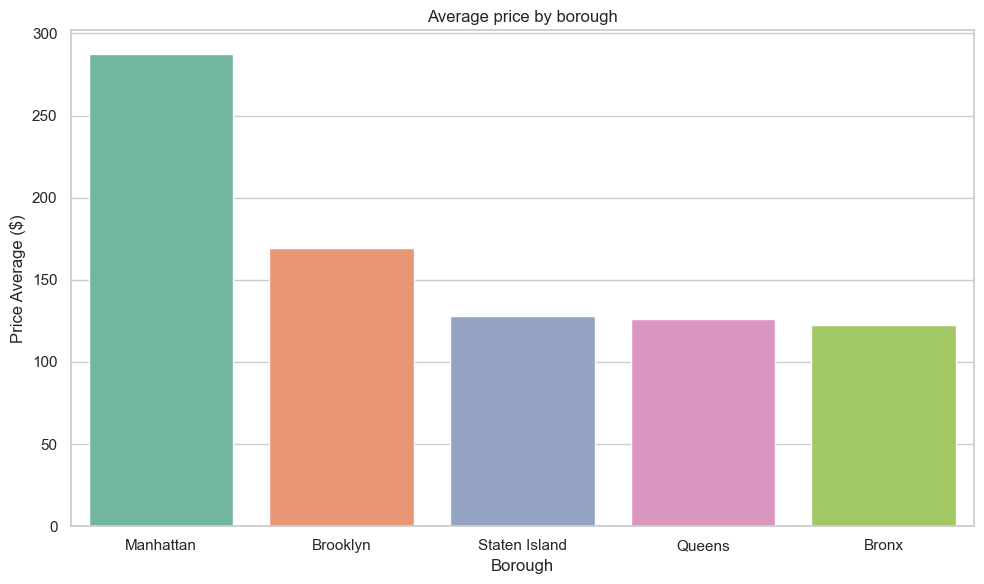
3. 변수 간 관계 파악 (통계 분석)
- 다변량 변수인 neighbourhood_group_cleansed와 연속형 변수인 price의 관계 분석
ANOVA (F-test)
import scipy.stats as stats
# 각 그룹의 price 리스트 만들기
groups = [group['price'].values for name, group in df.groupby('neighbourhood_group_cleansed')]
# 일원분산분석 (one-way ANOVA)
f_stat, p_val = stats.f_oneway(*groups)
print("F-statistic:", f_stat)
print("p-value:", p_val)F-statistic: 143.90693571553652
p-value: 1.175661940261546e-121
groups = [group['log_price'].values for name, group in df.groupby('neighbourhood_group_cleansed')]F-statistic: 822.652824790553
p-value: 0.0
Eta-squared 계산 (효과 크기)
# 그룹별 평균 계산
group_means = df.groupby('neighbourhood_group_cleansed')['price'].mean()
grand_mean = df['price'].mean()
# 그룹별 샘플 수
group_counts = df['neighbourhood_group_cleansed'].value_counts()
# SSA (그룹 간 제곱합)
ssa = sum(group_counts[group] * ((group_means[group] - grand_mean) ** 2) for group in group_means.index)
# SST (전체 제곱합)
sst = ((df['price'] - grand_mean) ** 2).sum()
eta_squared = ssa / sst
print("η² (Eta-squared):", eta_squared)
- price
- 이상치 제거 전) η² (Eta-squared): 0.025648856696169363
- 이상치 제거 후) η² (Eta-squared): 0.09607592697896117
- log_price
- 이상치 제거 전) η² (Eta-squared): 0.1307998307165115
- 이상치 제거 후) η² (Eta-squared): 0.1342010388141418
log_price 기준으로 봤을때, 자치구 간 숙소 가격 수준의 체계적인 차이가 존재하며 그 차이가 전체 가격 분산의 약 13%를 설명할 수 있다고 해석 가능
5. 예측 모델
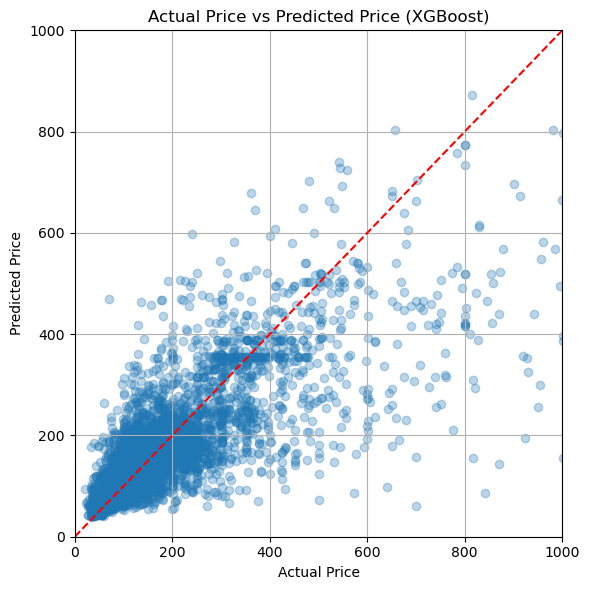
이게 최선이야...? 정말로...?
선형 회귀
- 이상치 제거 전
R² score: 0.3769480021124185
RMSE: 0.6202153885327946- 이상치 제거 후
R² score: 0.3634814695493267
RMSE: 0.5868280594687393
원래도 성능 안 좋았는데 이상치 제거하니까 더 안좋아짐ㅜ.ㅜ
선형 회귀는 역시나 탈락
RandomForest
- 이상치 제거 전
R²: 0.6590698408063641
RMSE: 0.4587891110104962- 이상치 제거 후
R²: 0.6615492205596732
RMSE: 0.4279106596047909
여기부터 좀 괜찮아짐
XGBoost
- 이상치 제거 전
R²: 0.5289548878787302
RMSE: 1.6890156101009202- 이상치 제거 후
R²: 0.6615492205596732
RMSE: 0.4279106596047909
하이퍼파라미터 튜닝 (GridSearchCV)
- 최적 모델 테스트셋 성능
R²: 0.6716889768268112
RMSE: 0.42145196032925114
일단 오늘은 이정도에 만족하는걸로...^^
이상치 제거를 z-score로만 했는데 KNN으로도 한번 해봐야겠다. 사실 살짝 해봤는데 딱히 큰 기대는 안됨
Feature Importances
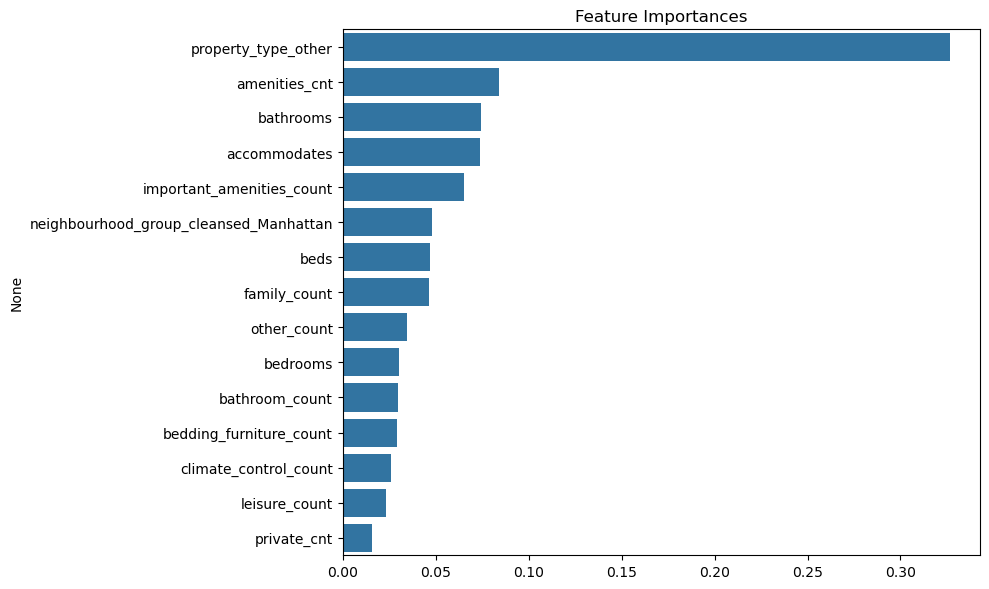
- property_type에 크게 주목 안하고 있었는데 이거 보니까
내일은 property_type을 대용님이 새로 잡아주신 기준대로 수정해서 전처리 통합본 csv파일을 한번 수정해야겠다. (사실 오늘해야됨,, 오늘해서 내일 바로 쓸 수 있게 만들어야겠다...^^)
일기
지도 그리는 거 정말 쉽지 않다.. 나는 괜찮아도 내 노트북이 죽을라 함ㅋ
아직도 해야할 게 너무 많다
- 전처리 통합본 수정하고 (property_type 바꾸기! amenities도 한번 더 보고,, beds 결측치 없애기...ㅋㅋ;;)
- 변수들 간의 상관관계 좀 더 보고
- 모델 무한 돌리기 하면서 성능 높이기,,
- 그리고 무엇보다 중요한건!!! 스토리텔링 어떻게 할지, 예측 모델을 어디에 쓸지, 인사이트를 어떻게 활용할지 등등 발표 개요를 짜야한다는 것!!!
머신러닝은 도구일 뿐이라는 걸 잊지말자,,
중요한 건 인사이트!
그리고 그 인사이트를 어떻게 서비스화 하거나 현실에 적용시킬지 고민하는 것도 중요하다는 걸 잊지말자,,

아자아자🤩