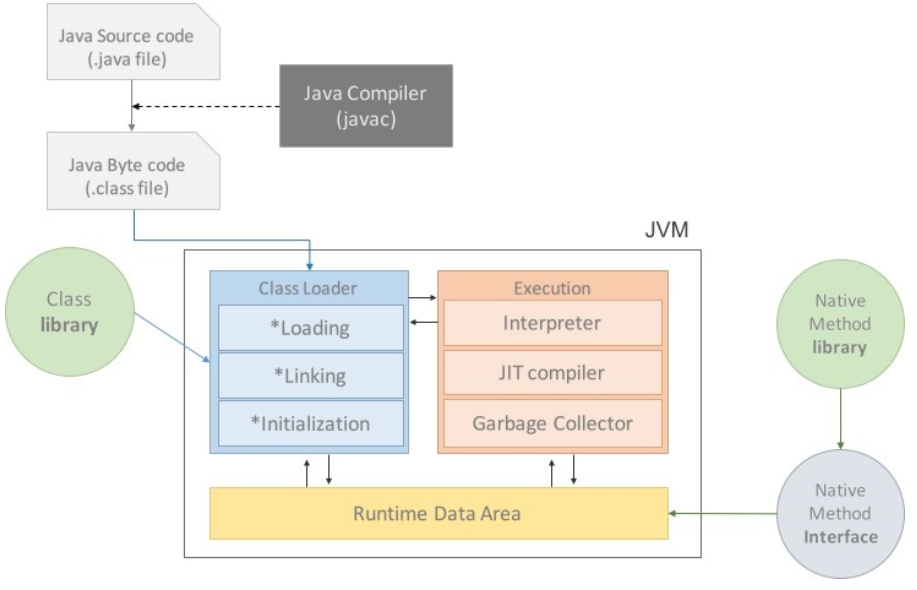
Java Virtual Machine이다. 즉, 자바를 실행하기 위한 가상 기계(컴퓨터)라고 할 수 있다. 이의 역할은 OS에 종속받지 않고 CPU가 자바를 인식 및 실행할 수 있게 하는 것이다.
자바 소스코드, 즉 원시코드인 .java는 CPU가 인식하지 못하므로 기계어로 컴파일 해줘야만한다.
자바는 이 과정에 JVM이 추가되어, 원시코드가 기계어로 바로 컴파일 되는 것이 아니라 JVM이 읽을 수 있는 '자바 바이트코드'(.class)로 변환된다.
'자바 소스코드'(.java) => '자바 바이트코드'(.class)로의 변환은 자바 컴파일러가 담당한다.
자바 컴파일러 = JDK 를 설치하면 bin에 존재하는 javac.exe (즉, JDK에 자바 컴파일러가 포함되어있다.)
JDK = 자바 플랫폼의 등장 이래 가장 널리 사용되고 있는 sw 개발 키트(SDK). 즉, 자바로 SW를 개발할 수 있도록 여러 기능을 제공하는 키트를 의미한다. 자바 어플리케이션의 개발을 위한 툴 세트로서 개발자는 Java EE(Enterprise Edition), Java SE(Special Edition), Java ME(Mobile Edition) 등 Java 버전 및 패키지나 에디션에 따라 JDK를 선택한다. Java 프로그램의 실행이 Java 프로그램 개발 프로세스의 일부이므로 모든 JDK에는 항상 호환 가능한 JRE가 포함된다.
JRE = Java Runtime Environment로서 말 그대로 환경이다. JVM, 자바 클래스 라이브러리 및 기타 인프라를 포함한 컴파일 된 Java 프로그램을 실행하는데 필요한 패키지이다. JRE는 자바 코드를 받아서 필요한 라이브러리와 결합한 다음 이 코드를 실행할 JVM을 시작하는 온디스크 시스템이다.
변환된 바이트코드(.class)는 기계어가 아니므로! OS에서 바로 실행되지 못한다. 바이트코드를 읽을 수 있는 JVM이 이 바이트코드를 OS가 이해할 수 있도록 해석해준다. 따라서 바이트코드는 JVM 위에서 OS에 상관없이 실행될 수 있는 것이다.
바이트코드란
가상컴퓨터(VM)에서 돌아가는 실행 프로그램을 위한 이진 표현법이다. 자바 컴파일러에 의해 변환된 코드의 명령어 크기가 1바이트라서 자바 바이트 코드라고 불린다.
바이트 코드는 다시 실시간 번역기 또는 JIT 컴파일러에 의해 바이너리 코드로 변환된다.
여기서 바이너리 코드란 이진 코드로서, 컴퓨터가 인식할 수 있는 0과 1로 구성된 이진코드를 의미하고 '기계어' 또한 0과 1로 이루어진 바이너리 코드를 의미한다. 하지만 기계어가 이진코드로 이루어졌을 뿐 모든 이진 코드가 기계어인 것은 아니다. 기계어는 특정한 언어가 아니라 CPU가 이해하는 명령어 집합으로서 CPU 제조사마다 기계어가 다를 수 있다.
즉, CPU가 이해하는 언어는 바이너리 코드, VM이 이해하는 코드는 바이트 코드이다.
JIT 컴파일러란
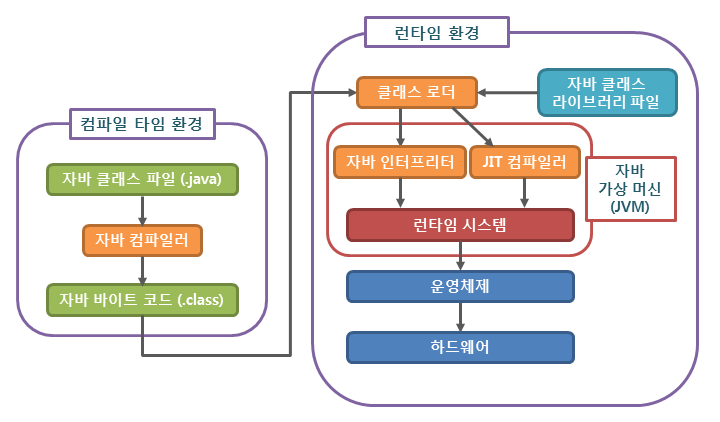
JIT 컴파일(just-in-time compliation) 또는 동적 번역(dynamic translation)이라고 한다. 런타임시 자바 애플리케이션의 성능을 향상시키는 JRE의 구성요소로서, JVM의 어떤 것도 컴파일러보다 성능에 더 큰 영향을 미치지 않으며 컴파일러를 선택하는 것은 자바 애플리케이션 실행시 내릴 첫 번째 결정 중 하나이다.
기계어로 변환해주는 방법에는 크게 두 가지 방식이 있는데 첫 번째는 실행시키기 전에 작성된 소스코드 전체를 컴퓨터가 실행할 수 있도록 기계어 형태의 명령들로 변환하는 Compilation 방식 이고 두 번째는 소스코드를 읽어가며 해당 기능에 대응하는 중간 코드(intermediate code)로 변환하여 이를 실행하는 Interpretation 방식 이다.
Compilation은 컴파일 후 링크(link=서로 연관된 오브젝트 파일들을 라이브러리 파일들과 연결하여 하나의 실행 파일을 만드는 절차)를 거쳐 .exe라는 실행 파일을 만들게 된다. (컴파일과 링크의 두 단계로 분리시켜서 실행 파일을 만드는 이유는 여러 개의 파일로 구성된 프로그램에서 변경되지 않은 소스 파일을 다시 컴파일 하지 않기 위함이다.)
Interpretation은 컴파일 언어와 다르게 별도의 실행 파일이 생성되지 않는다.
JIT 컴파일러 는 프로그램을 실제 실행하는 시점에 기계어로 번역하는 컴파일러이다. 이는 인터프리터 방식의 단점 보완을 위해 도입되었다. OS에 영향받는 부분을 없애고자 컴파일을 진행하고 인터프리터로 변환하는 작업을 진행하는 자바의 속도 측면에서의 취약점을 해결하고자 등장한 것이다. JIT 컴파일러는 기본적으로 자주 읽게 되는 소스에 대해 해당 부분을 캐싱해두고 이를 읽어야하는 시점에 덩어리째로 반환을 해주는 방식을 사용했다. 따라서 한 번 컴파일된 코드는 빠르게 수행하게 된다. 물론 JIT 컴파일러가 컴파일 하는 과정은 바이트 코드를 인터프리팅 하는 것보다 훨씬 오래 걸리므로 한 번만 실행되는 코드라면 인터프리팅만 하는 것이 유리하다. 따라서, JIT 컴파일러를 사용하는 JVM들은 내부적으로 해당 메서드가 얼마나 자주 수행되는지 체크하고, 일정 정도를 넘을 때에만 컴파일을 수행한다.
자바에서 컴파일을 하면 바이트 코드로 변환된다. 이 바이트 코드는 기계가 바로 읽을 수 있는 형태가 아니며 실제 실행될 때 다시 한 번 기계가 읽을 수 있는 형태로 인터프리터를 통해 해석되어야한다. 이렇게 두 번의 과정을 거치는 이유는 machine-independent 특성 때문이다. 즉, 개발자들은 별 걱정 없이 프로그램을 작성해서 바이트 코드로 컴파일을 하고, JVM이 이 바이트코드를 해당 기계에 맞는 기계어로 다시 번역하는 작업을 하는 것이다.
JVM이 바이트코드 -> 기계어로 변환(interpret, 해석)할 때 반복되는 내용은 컴파일 해서 사용하곤 한다.(한 번만 컴파일 된다) 이 과정을 JIT 컴파일링 이라고 한다. JIT 컴파일러를 사용하는 컴파일 없이 interpret만 하는 경우보다 반복적인 작업을 할 때 훨씬 높은 성능을 낼 수 있다.
자바 코드를 입력하고 실행 버튼을 누르면
1. 자바 코드는 java compiler를 통해 바이트 코드로 변환된다.
2. 인터프리터를 통해 한 줄 한 줄 해당 OS에서 이해할 수 있는 기계어로 변환된다.
이렇게 자바는 컴파일과 인터프리터 두 가지 방식을 병행해서 사용한다. 하지만 매번 컴파일을 통해 바이트 코드로 변환한 후 다시 인터프리터를 통해 한 줄 한 줄 기계어로 변환하는 작업은 속도면에서 매우 비효율적이다. 이를 해결하기 위해 JIT 컴파일러가 등장한 것이다. JIT 컴파일러를 사용하면, JIT 컴파일러가 먼저 소스 코드 전체를 확인한 후 중복된 부분을 미리 기계어로 번역시켜서 캐싱해놓는다. 이후 인터프리터 방식으로 번역하다가 중복된 부분을 만나게 되면 이미 변환된 기계어 코드를 재사용한다. 따라서 시간 속도 면에서 개선된 모습을 보여주게 되는 것이다. 이 과정 수행을 위해선 초반에 메모리를 잡아두거나 하는 것과 같은 선행 작업들이 요구되어 초기 실행 속도는 다소 느릴 수도 있다. 하지만 그 이후로는 바이트코드를 사용할 때마다 기계어로 변환하는 작업이 덜 들어서 실행 속도가 많이 향상된다.
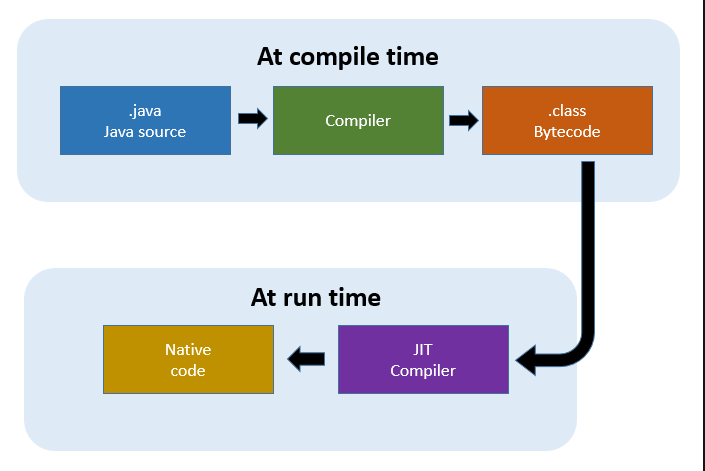
오라클 Hotspot VM은 Hotspot compiler라고 불리는 JIT 컴파일러를 사용한다. 핫스팟이라 불리는 이유는 내부적으로 프로파일링을 통해 가장 컴파일이 필요한 부분, 즉 핫스팟을 찾아낸 다음 이 핫스팟을 네이티브 코드로 컴파일하기 때문이다.
JVM의 구성요소
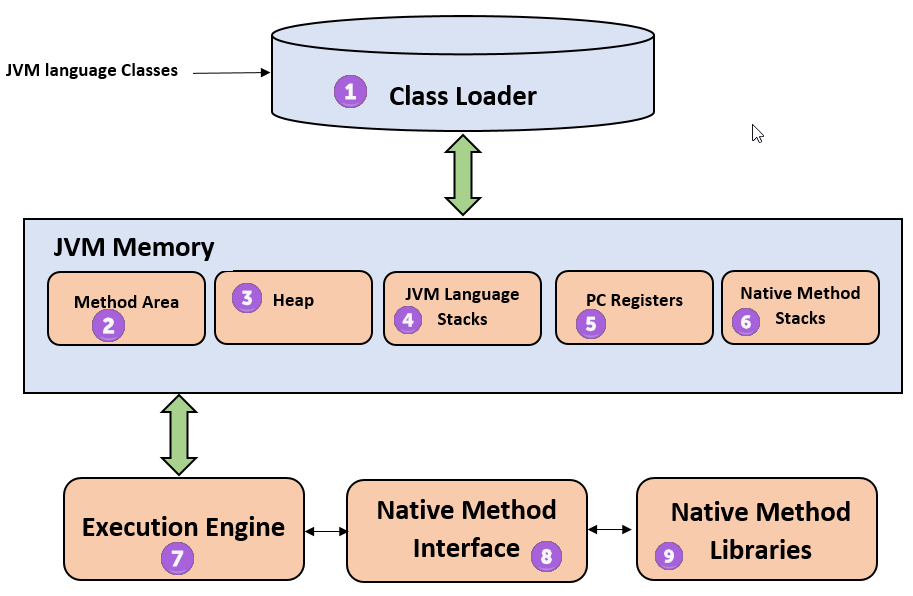
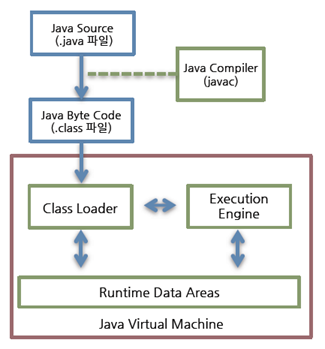
자바로 작성한 코드는 위와 같은 과정을 통해 수행된다. Class Loader가 컴파일 된 자바 바이트 코드를 Runtime Data Area에 로드하고, Execution Engine이 자바 바이트코드를 실행한다.
클래스 로더
자바는 compile time이 아니라 run time에 클래스를 처음으로 참조할 때 해당 클래스를 load하고 link하는 특징이 있다. 이러한 동적 로드를 담당하는 부분이 바로 JVM의 클래스 로더이다. 자바 클래스 로더는 다음과 같은 특징을 갖는다.
- 계층 구조 = class loader끼리 부모-자식 관계를 이루어 계층 구조로 생성된다. (최상위 클래스로더가 Bootstrap class Loader)
- 위임 모델 = 계층 구조를 바탕으로 클래스 로더끼리 로드를 위임하는 구조로 동작. 클래스를 로드할 때 먼저 상위 클래스 로더를 확인하여 상위 클래스 로더에 있다면 해당 클래스를 사용하고, 없다면 로드를 요청 받은 클래스 로더가 클래스를 로드한다.
- 가시성 제한 = 하위 클래스로더는 상위 클래스로더의 클래스를 찾을 수 있지만, 상위 클래스로더는 하위 클래스로더의 클래스를 찾을 수 없다.
- 언로드 불가 = 클래스 로더는 클래스를 로드할 수는 있지만 언로드할 수는 없다. 대신 현재 클래스 로더를 삭제하고 아예 새로운 클래스 로더를 생성하는 방법을 사용할 수 있다.
각 클래스 로더는 로드된 클래스들을 보관하는 name space를 갖는다. 클래스를 로드할 때 이미 로드 된 클래스인지 확인하기 위해서 name space에 보관 된 FQCN(Fully Qualified Class Name)을 기준으로 클래스를 찾는다. 비록 FQCN이 갖더라도 name space가 다르면, 즉 다른 클래스 로더가 로드한 클래스이면 다른 클래스로 간주한다.
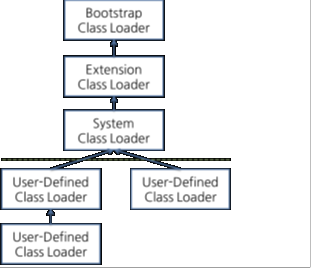
위는 클래스로더 위임 모델을 표현한 것이다.
클래스로더가 클래스 로드를 요청 받으면 '클래스 로더 캐시' => '상위 클래스 로더' => '자기자신'의 순서대로 해당 클래스가 있는지 확인한다. 부트스트랩 클래스 로더에서도 없으면 요청 받은 클래스 로더가 파일시스템에서 해당 클래스를 찾는다.
- Bootstrap Class Loader = JVM을 기동할 때 생성되며 Object 클래스들을 비롯하여 자바 API 들을 로드한다. 다른 클래스 로더와 달리 자바가 아니라 네이티브 코드로 구현되어 있다.
- Extension Class Loader = 기본 자바 API를 제외한 확장 클래스들을 로드한다. 다양한 보안 확장 기능 등을 여기에서 로드하게 된다.
- System Class Loader = Bootstrap과 Extension이 JVM 자체의 구성 요소들을 로드하는 것이라면 System Class Loader는 애플리케이션의 클래스들을 로드한다고 할 수 있다.
- User-Defined Class Loader = 애플리케이션 사용자가 직접 코드 상에서 생성해서 사용하는 클래스 로더이다.
런타임 데이터 영역
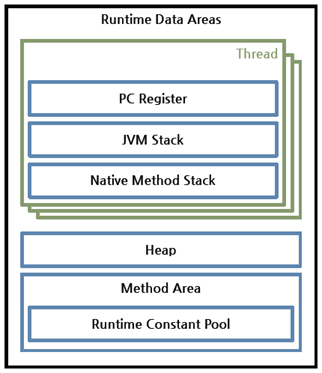
JVM이라는 프로그램이 OS 위에서 실행되면서 할당 받는 메모리 영역이다.
이는 6개의 영역으로 나눌 수 있는데,
PC Register, JVM Stack Native Method Stack은 스레드마다 하나씩 생성되며
Heap, Method Area, Runtime Constant Pool은 모든 스레드가 공유해서 사용한다.
- PC 레지스터 : Program Counter 레지스터는 각 스레드마다 하나씩 존재하며 스레드가 시작될 때 생성된다. PC 레지스터는 현재 수행중인 JVM 명령의 주소를 갖는다.
- JVM 스택 : 각 스레드마다 하나씩 존재하며 스레드가 시작될 때 생성된다. stack Frame이라는 구조체를 저장하는 스택으로 JVM은 오직 JVM Stack에 '스택 프레임'을 추가하고 제거하는 동작만 수행한다.
스택 프레임 : JVM 내에서 메서드가 수행될 때마다 하나의 스택 프레임이 생성되어 해당 스레드의 JVM stack에 추가되고, 메서드가 종료되면 스택 프레임이 제거된다. 각 스택 프레임은 Local Variable Array, Operand Stack, 현재 실행 중인 메서드가 속한 클래스의 runtime constant pool에 대한 레퍼런스를 갖는다.
- Native method 스택 : 자바 외의 언어로 작성된 네이티브 코드를 위한 스택이다. 즉, JNI(Java Native Interface)를 통해 호출하는 C/C++ 등의 코드를 수행하기 위한 스택으로, 언어에 맞게 C스택이나 C++스택이 생성된다.
- Method 영역 : 모든 스레드가 공유하는 영역으로 JVM이 시작될 때마다 생성된다. JVM이 읽어들인 각각의 클래스와 인터페이스에 대한 'runtime constant pool','field와 method 정보', 'static 변수', 'method의 바이트코드' 등을 보관한다.
- 런타임 상수 풀 : 각 클래스와 인터페이스의 상수 뿐만 아니라 메서드와 필드에 대한 모든 레퍼런스까지 담고 있는 테이블이다. 즉, 어떤 메서드나 필드를 참조할 때 JVM은 런타임 상수 풀을 통해 해당 메서드나 필드의 실제 메모리상 주소를 찾아서 참조한다.
- 힙 : 인스턴스 또는 객체를 저장하는 공간으로서 가비지 컬렉션 대상이다.
실행엔진
클래스 로더를 통해 JVM내의 runtime data area에 배치된 바이트 코드는, 실행엔진에 의해 실행된다. 실행 엔진은 바이트 코드를 명령어 단위로 읽어서 실행한다. CPU가 기계 명령어를 하나씩 실행하는 것과 비슷하다. 바이트코드의 각 명령어는 1바이트짜리 OpCode와 추가 피연산자로 이루어져있으며 실행 엔진은 하나의 OpCode를 가져와서 피연산자와 함께 작업을 수행한 다음, 그 다음의 OpCode를 수행하는 식으로 동작한다.
참조
https://doozi0316.tistory.com/entry/1%EC%A3%BC%EC%B0%A8-JVM%EC%9D%80-%EB%AC%B4%EC%97%87%EC%9D%B4%EB%A9%B0-%EC%9E%90%EB%B0%94-%EC%BD%94%EB%93%9C%EB%8A%94-%EC%96%B4%EB%96%BB%EA%B2%8C-%EC%8B%A4%ED%96%89%ED%95%98%EB%8A%94-%EA%B2%83%EC%9D%B8%EA%B0%80
https://velog.io/@shelly/JAVA-JDK%EB%9E%80
https://www.itworld.co.kr/news/110768
https://heewon26.tistory.com/207
https://dkswnkk.tistory.com/416
https://d2.naver.com/helloworld/1230
