1. MySQL 엔진 아키텍처
(1) 전체 구조
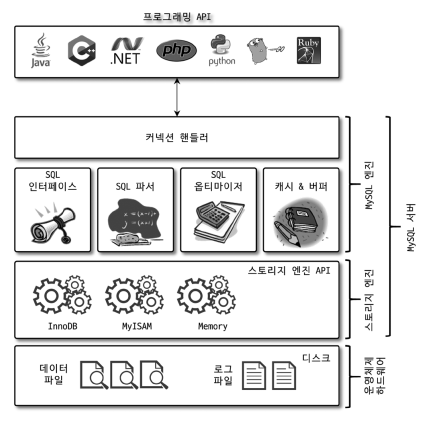
MySQL 서버는 크게 MySQL 엔진과 스토리지 엔진으로 구분할 수 있다.
<1> MySQL 엔진
DBMS의 두뇌에 해당하는 처리를 수행한다.
클라이언트로부터의 접속 및 쿼리 요청을 처리하는 커넥션 핸들러와 SQL 파서 및 전처리기, 쿼리의 최적화된 실행을 위한 옵티마이저가 중심을 이룬다.
<2> 스토리지 엔진
실제 데이터를 디스크 스토리지에 저장하거나 읽어오는 부분을 전담한다.
MySQL 서버에서 MySQL 엔진은 하나지만 스토리지 엔진은 여러 개를 동시에 사용할 수 있다. (테이블이 사용할 스토리지 엔진을 지정할 수도 있다.)
<3> 핸들러 API
MySQL 엔진에서 스토리지 엔진에 요청을 할 때, 이 요청을 핸들러 요청이라 한다. 그리고 이때 사용되는 API가 바로 핸들러API이다.
(2) MySQL 스레딩 구조
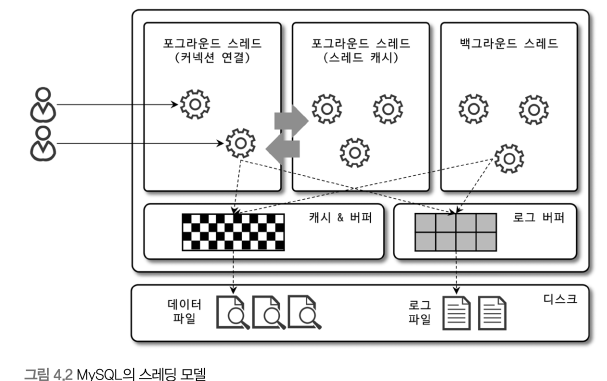
MySQL 서버는 프로세스 기반이 아니라 스레드 기반으로 작동한다. 이때 스레드는 포그라운드 스레드와 백그라운드 스레드로 구분할 수 있다.
<1> 포그라운드 스레드(클라이언트 스레드)
이는 최소한 MySQL 서버에 접속한 클라이언트의 수만큼 존재한다.
주로 각 클라이언트 사용자가 요청하는 쿼리 문장을 처리한다.
클라이언트 사용자가 작업을 마치고 커넥션을 종료하면, 해당 커넥션을 담당하던 스레드는 다시 스레드 캐시로 되돌아간다. 이때 이미 스레드 캐시에 일정 개수 이상의 대기 중인 스레드가 있다면 스레드 캐시에 넣지 않고! 스레드를 종료시켜 일정 개수의 스레드만 스레드 캐시에 존재하게 한다.
포그라운드 스레드는 데이터를 MySQL의 데이터 버퍼나 캐시로부터 가져오며, 버퍼나 캐시에 없는 경우에는 직접 디스크의 데이터나 인덱스 파일로부터 데이터를 읽어와서 작업을 처리한다.
MySQL에서 "사용자 스레드"와 "포그라운드 스레드"는 똑같은 의미로 사용된다.
<2> 백그라운드 스레드
InnoDB에서 백그라운드 스레드가 하는 일 중 가장 중요한 것이 바로 로그 스레드와 버퍼의 데이터를 디스크로 내려쓰는 작업을 처리하는 쓰기 스레드이다.
(3) 메모리 할당 및 사용 구조
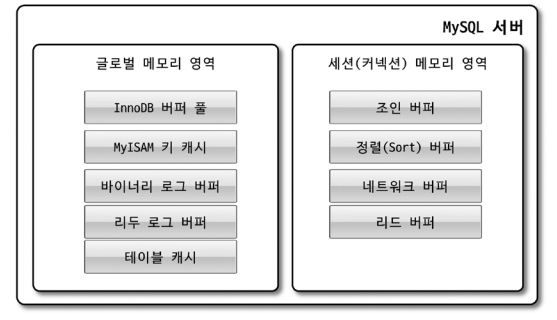
MySQL에서 사용되는 메모리 공간은 크게 글로벌 메모리 영역과 로컬 메모리 영역으로 구분할 수 있다.
글로벌 메모리 영역과 로컬 메모리 영역은 MySQL 서버 내에 존재하는 많은 스레드가 공유해서 사용하는 공간인지 여부에 따라 구분된다.
<1> 글로벌 메모리 영역
일반적으로 클라이언트 스레드 수와 무관하게 하나의 메모리 공간만 할당된다. (2개 이상도 할당은 가능) 글로벌 메모리 영역은 모든 스레드에 의해 공유된다.
<2> 로컬 메모리 영역
세션 메모리 영역이라고도 한다.
MySQL 서버상에 존재하는 클라이언트 스레드가 쿼리를 처리하는 데 사용하는 메모리 영역이다. 클라이언트가 MySQL 서버에 접속하면 MySQL 서버에서는 클라이언트 커넥션으로부터의 요청을 처리하기 위해 스레드를 하나씩 할당하게 되는데, 클라이언트 스레드가 사용하는 메모리 공간이라고 해서 클라이언트 메모리 영역이라고도 한다.
로컬 메모리는 각 클라이언트 스레드별로 독립적으로 할당되며 절대 공유되어 사용되지 않는다는 특징이 있다. 또한 각 쿼리의 용도별로 필요할 때만 공간이 할당되고 필요하지 않은 경우엔 MySQL이 메모리 공간을 할당조차도 하지 않을 수도 있다는 특징이 있다.
(4) 플러그인 스토리지 엔진 모델
MySQL의 독특한 구조 중 대표적인 것이 플러그인 모델이다.
스토리지 엔진, 검색어 파서.. 등이 플로그인으로 구현되어 제공된다.
실제로 수많은 사용자의 다양한 요건을 기초로 MySQL엔 다양한 스토리지 엔진이 존재한다.
(5) 컴포넌트
MySQL 8.0부터는 기존의 플러그인 아키텍처를 대체하기 위해서 컴포넌트 아키텍처가 지원된다.
왜냐하면 플러그인은 아래와 같은 단점이 존재하기 때문이다.
- 오직 MySQL 서버와 인터페이스할 수 있고, 플러그인끼리는 통신할 수 없다.
- 플러그인은 MySQL 서버의 변수나 함수를 직접 호출하기 때문에 안전하지 않다(캡슐화 되지 않는다)
- 플러그인은 상호 의존 관계를 설정할 수 없어서 초기화가 어렵다.
(6) 쿼리의 실행 구조
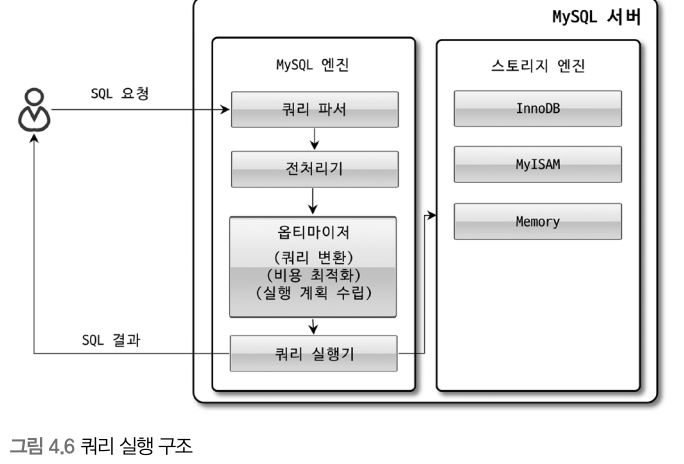
<1> 쿼리 파서
사용자 요청으로 들어온 쿼리 문장을 토큰으로 분리해 트리 형태의 구조로 만들어 내는 작업을 의미한다.
이 과정에서 쿼리 문장의 기본 문법 오류가 발견된다.
<2> 전처리기
파서 과정에서 만들어진 파서 트리를 기반으로 쿼리 문장에 구조적인 문제점이 있는지 확인한다. 실제 존재하지 않거나 권한상 사용할 수 없는 개체의 토큰은 이 단계에서 걸러진다.
<3> 옵티마이저
사용자의 요청으로 들어온 쿼리 문장을 저렴한 비용으로 가장 빠르게 처리할지를 결정하는 역할을 담당한다. (중요하고 영향 범위도 무지 넓다.)
<4> 실행 엔진
옵티마이저가 두뇌라면, 실행 엔진과 핸들러는 손과 발에 비유할 수 있다.
옵티마이저가 GROUP BY를 처리하기 위해 임시 테이블을 사용하기로 결정했다고 해보자.
- 실행 엔진이 핸들러에게 임시 테이블 만들라고 요청함
- 다시 실행 엔진은
WHERE절에 일치하는 레코드를 읽어오라고 핸들러에게 요청함. - 읽어온 레코드들을 1번에서 준비한 임시 테이블로 저장하라고 다시 핸들러에게 요청.
- 데이터가 준비된 임시 테이블에서 필요한 방식으로 데이터를 읽어 오라고 핸들러에게 다시 요청
- 최종적으로 실행 엔진은 결과를 사용자나 다른 모듈로 넘김
즉, 실행 엔진은 만들어진 계획대로 각 핸들러에게 요청해서 받은 결과를 또 다른 핸들러 요청의 입력으로 연결하는 역할을 수행한다.
<5> 핸들러(스토리지 엔진)
핸들러는 MySQL 서버의 가장 밑단에서 MySQL 실행 엔진의 요청에 따라 데이터를 디스크로 저장하고 디스크로부터 읽어 오는 역할을 담당한다. 핸들러는 결국 스토리지 엔진을 의미하는 것
(7) 복제
다른 장에서 설명 예정 ~..
(8) 쿼리 캐시
빠른 응답을 필요로하는 웹 기반의 응용 프로그램에서 매우 중요한 역할을 담당했다.
SQL의 실행 결과를 메모리에 캐시하고, 동일 SQL 쿼리가 실행되면 반환하면 되기 때문에 매우 빠른 성능을 보였다.
하지만, 쿼리 캐시는 테이블의 데이터가 변경되면 캐시에 저장된 결과 중에서 변경된 테이블과 관련된 것들은 모두 삭제해야 했다. 이는 심각한 동시 처리 성능 저하를 유발한다. 또한 MySQL 서버가 발전하면서 성능이 개선되는 과정에서 쿼리 캐시는 계속된 동시 처리 성능 저하와 많은 버그의 원인이 되기도 했다.
결국 MySQL 8.0에서 쿼리 캐시는 완전히 제거됐다.
(9) 스레드 풀
스레드 풀은 내부적으로 사용자의 요청을 처리하는 스레드 개수를 줄여서 동시 처리되는 요청이 많다 하더라도 MySQL 서버의 CPU가 제한된 개수의 스레드 처리에만 집중할 수 있게 해서 서버의 자원 소모를 줄이는 것이 목적이다.
근데 실제 서비스에서 스레드 풀이 눈에 띄는 성능 향상을 보여준 경우는 드물었다. 또한 스레드 풀은 동시에 실행 중인 스레드들을 CPU가 최대한 잘 처리해낼 수 있는 수준으로 줄여서 빨리 처리하게 하는 기능이기 때문에 스케줄링 과정에서 CPU 시간을 제대로 확보하지 못하는 경우엔 쿼리 처리가 더 느려지는 사례도 발생할 수 있다는 점에 주의하자.
일반적으로는 CPU 코어의 개수와 스레드 풀 사이즈를 맞추는 것이 CPU 프로세서 친화도를 높이는데 좋다.
(10) 트랜잭션 지원 메타데이터
MySQL 서버는 5.7 버전까지 테이블의 구조를 FRM 파일에 저장하고, 일부 스토어드 프로그램 또한 파일 기반으로 관리했다. 그러니까 테이블의 생성 또는 변경 도중 서버가 비정상적으로 종료되면 일관되지 않는 상태로 남는 문제가 발생했다.
MySQL8.0부턴 이를 해결하기 위해 테이블 구조 정보나 스토어드 프로그램의 코드 관련 정보들을 모두 InnoDB의 테이블에 저장하도록 했다. MySQL 서버가 동작하는데 기본적으로 필요한 테이블을 묶어서 시스템 테이블이라고 하는데, 이런 애들이 mysql DB에 저장하고 있다. mysql DB는 통째로 mysql.ibd라는 이름의 테이블스페이스에 저장된다(얘는 다른 .ibd 파일과 함께 특별히 주의해야 한다.)
MySQL 8.0 버전부터 데이터 딕셔너리와 시스템 테이블이 모두 트랜잭션 기반의 InnoDB 스토리지 엔진에 저장되도록 개선되면서 이제 스키마 변경 작업 중간에 MySQL 서버가 비정상적으로 종료된다고 하더라도 스키마 변경이 완전한 성공 또는 완전한 실패로 정리된다.
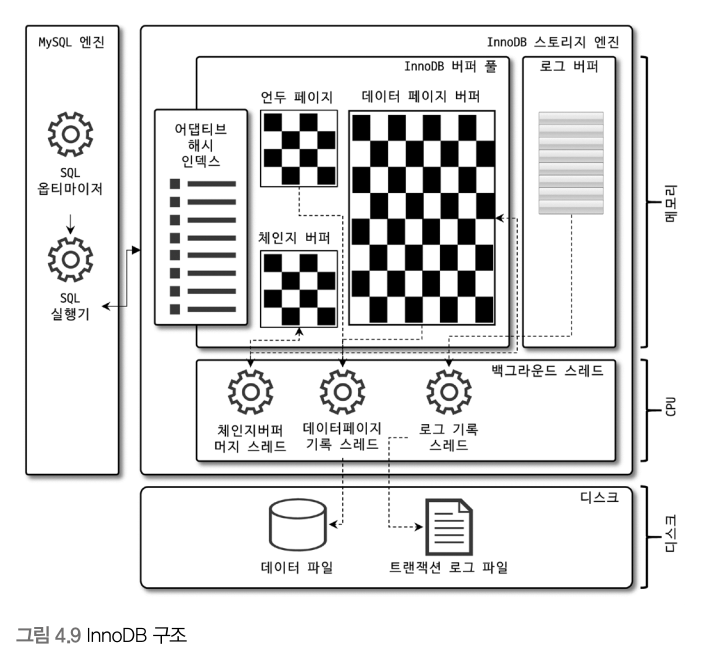
InnoDB 스토리지 엔진 아키텍처
위에서는 MySQL 엔진의 전체적인 구조를 살펴봤다면, 이번 절에서는 MySQL의 스토리지 엔진 가운데 가장 많이 사용되는 InnoDB 스토리지 엔진을 간단히 살펴보자.
InnoDB는 MySQL에서 사용할 수 있는 스토리지 엔진 중 거의 유일하게 레코드 기반의 잠금을 제공한다. 그리고 그 때문에 높은 동시성 처리가 가능하고 안정적이며 성능이 뛰어나다.
(1) 프라이머리 키에 의한 클러스터링
InnoDB의 모든 테이블은 프라이머리 키를 기준으로 클러스터링되어 저장된다. 즉, 프라이머리 키 값의 순서대로 디스크에 저장된다는 뜻이다. 모든 세컨더리 인덱스는 레코드의 주소 대신 프라이머리의 키 값을 논리적인 주소로 사용한다.
프라이머리 키가 클러스터링 인덱스이기 땜누에 프라이머리 키를 이요한 "레인지 스캔"은 상당히 빨리 처리될 수 있다.
InnoDB 스토리지 엔진과는 달리 MyISAM 스토리지 엔진에서는 클러스터링 키를 지원하지 않는다. 그래서 MyISAM 테이블에서는 프라이머리 키와 세컨더리 인덱스는 구조적으로 아무런 차이가 없다.(걍 프라이머리 키는 unique 제약을 가진 세컨더리 인덱스일 뿐) 또한 MyISAM 테이블의 프라이머리 키를 포함한 모든 인덱스는 물리적인 레코드의 주소값(ROWID)을 가진다.
(2) 외래 키 지원
InnoDB 스토리지 엔진 레벨에서 지원하는 기능이다.
InnoDB에서 외래 키는 부모 테이블과 자식 테이블 모두 해당 컬럼에 인덱스 생성이 필요하고, 변경 시에는 반드시 부모 테이블이나 자식 테이블에 데이터가 있는지 체크하는 작업이 필요하므로 잠금이 여러 테이블로 전파되고, 그로 인해 데드락이 발생할 때가 많으므로 개발할 때도 외래 키의 존재에 주의하는 것이 좋다.
(3) MVCC(Multi Version Concurrency Control)
레코드 레베르이 트랜잭션을 지원하는 DBMS가 제공하는 기능.
잠금을 사용하지 않는 일관된 읽기 제공에 목적이 있다.
InnoDB는 Undo log를 이용해 이 기능을 구현한다.
여기서 multi version은 하나의 레코드에 대해 여러 개의 버전이 동시에 관리된다는 의미이다.
(4) 잠금 없는 일관된 읽기(Non-Locking Consistent Read)
InnoDB 스토리지 엔진은 MVCC 기술을 이용해 잠금을 걸지 않고 읽기 작업을 수행한다. 잠금을 걸지 않기 때문에 읽기 작언은 다른 트랜잭션이 가지고 있는 잠금을 기다리지 않고 읽기 작업이 가능하다.
(5) 자동 데드락 감지
InnoDB 스토리지 엔진은 내부적으로 잠금이 교착 상태에 빠지지 않았는지 체크하기 위해 잠금 대기 목록을 그래프(Wait-for List) 형태로 관리한다.
InnoDB 스토리지 엔진은 데드락 감지 스레드를 가지고 있어서 데드락 감지 스레드가 주기적으로 잠금 대기 그래프를 검사해 교착 상태에 빠진 트랜잭션 들을 찾아서 그 중 하나를 강제 종료한다. 이때 어느 트랜잭션을 먼저 강제 종료할 것인지를 판단하는 기준은 트랜잭션의 언두 로그 양이며, 언두 로그 레코드를 더 적게 가진 트랜잭션이 일반적으로 롤백의 대상이 된다. (서버의 부하가 덜할 것이기 때문에)
일반적인 작업에서는 데드락 감지 스레드가 트랜잭션의 잠금 목록을 검사해서 데드락을 찾아내는 작업은 크게 부담되지 않는데, 동시 처리 스레드가 매우 많아지거나 각 트랜잭션이 가진 잠금의 개수가 많아지면 데드락 감지 스레드가 느려진다.
이러한 문제를 해결하기 위해 시스템 변수를 활용하여 제어할 수 있다. innodb_deadlock_detect를 OFF로 설정하면 데드락 감지 스레드는 작동하지 않게 된다. 이게 작동하지 않으면 InnoDB 스토리지 엔진 내부에서 두 개 이상의 트랜잭션이 상대방이 가진 잠금을 요구하는 상황이 발생해도 누가 중재를 하지 않기 때문에 무한 대기 현상이 발생할 것이다.
하지만 innodb_lock_wait_timeout 시스템 변수를 활성화하면 이러한 데드락 상황에서 일정 시간이 지나면 자동으로 요청이 실패하고 에러 메세지를 반환하게 된다.
(6) 자동화된 장애 복구
InnoDB에는 손실이나 장애로부터 데이터를 보호하기 위한 여러 가지 메커니즘이 탑재되어 있다. 이를 활용해서 MySQL 서버가 시작될 때 완료되지 못한 트랜잭션이나 디스크에 일부만 기록된 데이터 페이지 등에 대한 일련의 복구 작업이 자동으로 진행된다.
InnoDB 데이터 파일은 기본적으로 MySQL 서버가 시작될 때 항상 자동 복구를 수행한다. 이 단계에서 자동으로 복구될 수 없는 손상이 있다면 MySQL 서버는 종료돼 버린다. (innodb_force_recovery 시스템 변수로 설정 가능)
MySQL 서버가 기동되고 InnoDB 테이블이 인식된다면 mysqldump 를 이용해 데이터를 가능한만큼 백업하고 그 데이터로 MySQL 서버의 DB와 테이블을 다시 생성하는 것이 좋다.
(7) InnoDB 버퍼 풀
스토리지 엔진에서 가장 핵심적인 부분. 디스크의 데이터 파일이나 인덱스 정보를 메모리에 캐시해 두는 공간. 버퍼 풀이 변경된 데이터를 모아서 처리하면 랜덤한 디스크 작업의 횟수를 줄일 수 있다.
<1> 버퍼 풀의 크기 설정
OS와 각 클라이언트 스레드가 사용할 메모리를 충분히 고려해서 설정해야 한다.
가능하면 InnoDB 버퍼 풀의 크기를 적절히 작은 값으로 설정해서 조금씩 상황을 봐 가면서 증가시키는 방법이 최적이다.
버퍼 풀의 크기 변경은 크리티컬한 변경이므로 가능하면 MySQL 서버가 한가한 시점을 골라서 진행하는 것이 좋다.
버퍼 풀을 여러 개로 분리해서 관리할 수 있다. 이때 각 버퍼 풀을 버퍼 풀 인스턴스라고 표현한다.
<2> 버퍼 풀의 구조
InnoDB 스토리지 엔진은 버퍼 풀이라는 거대한 메모리 공간을 페이지 크기의 조각으로 쪼개어 InnoDB 스토리지 엔진이 데이터를 필요로 할 때 해당 데이터 페이지를 읽어서 각 조각에 저장한다.
버퍼 풀의 페이지 크기 조각을 관리하기 위해 InnoDB 스토리지 엔진은 크기 LRU 리스트와 플러시 리스트, 그리고 프리 리스트라는 세 개의 자료 구조를 관리한다.
프리 리스트는 InnoDB 버퍼 풀에서 실제 사용자 데이터로 채워지지 않은 비어 있는 페이지들의 목록.

LRU 리스트는 엄밀하게 보면 LRU와 MRU 리스트가 결합된 형태이다. Old 서브 리스트 영역은 LRU에 해당하고 New 서브리스트 영역은 MRU 정도로 이해하면 된다. LRU 리스트를 관리하는 목적은 디스크로부터 한 번 읽어온 페이지를 최대한 오랫동안 InnoDB 버퍼 풀의 메모리에 유지해서 디스크 읽기를 최소화 하는 것이다.
플러시 리스트는 디스크로 동기화되지 않은 데이터를 가진 데이터 페이지의 변경 시점 기준의 ㅔ이지 목록을 관리한다. 데이터가 변경되면 InnoDB는 변경 내용을 "리두 로그"에 기록하고 버퍼 풀의 데이터 페이지에도 변경 내용을 반영한다. 그래서 리두 로그의 각 엔트리는특정 데이터 페이지와 연결된다. 하지만 리두 로그가 디스크로 기록됐다고 해서 데이터 페이지가 디스크로 기록됐다는 것을 항상 보장하지는 않는다. 때로는 그 반대의 경우도 발생할 수 있는데, InnoDB 스토리지 엔진은 체크포인트를 발생시켜 디스크의 리두 로그와 데이터 페이지의 상태를 동기화 하게 된다.
<3> 버퍼 풀과 리두 로그
둘은 매우 밀접한 관계를 맺고 있다.
InnoDB의 버퍼 풀은 디스크에서 읽은 상태로 전혀 변경되지 않은 클린 페이지와 변경된 데이터를 가진 더티 페이지를 가지고 있다.
InnoDB 스토리지 엔진에서 리두 로그는 한 개 이상의 고정 크기 파일을 연결해서 순환 고리처럼 사용한다. 즉, 데이터 변경이 계속 발생하면 리두 로그 파일에 기록됐던 "로그 엔트리"는 어느 순간 새로운 로그 엔트리로 덮어 쓰인다. 그래서 InnoDB 스토리지 엔진은 "전체 리두 로그 파일"에서 "재사용 가능한 공간"과 "당장 재사용 불가능한 공간"을 구분해서 관리해야한다. 이때 재사용 불가능한 공간을 활성 리두 로그라고 한다.
리두 로그 파일의 공간은 계속 순환되어 재사용되지만 기록될때마다 로그 포지션은 증가한 값을 갖게 되는데 이를 LSN이라 한다. InnoDB 스토리지 엔진은 주기적으로 "체크포인트 이벤트"를 발생시켜 리두 로그와 버퍼 풀의 더티 페이지를 디스크로 동기화하는데, 이렇게 발생한 체크포인트 중 가장 최근 체크포인트 지점의 LSN이 활성 리두 로그 공간의 시작점이 된다. 하지만 활성 리두 공간의 마지막은 계속해서 증가하기 때문에 체크ㅗ인트와 무관하다. 그리고 가장 최근 체크포인트의 LSN와 마지막 리두 로그 엔트리의 LSN 차이를 체크 포인트 에이지(=활성 리두 로그 공간의 크기(라고 한다.
InnoDB 버퍼 풀의 더티 페이지는 특정 리두 로그 엔트리와 관계를 가지고, 체크포인트가 발생하면 체크포인트 LSN보다 작은 리두 로그 엔트리와 관련된 더티 페이지는 모두 디스크로 동기화 되어야 한다.
<4> 버퍼 풀 플러시
InnoDB 스토리지 엔진은 버퍼 풀에서 아직 디스크로 기록되지 않은 더티 페이지들을 성능상의 악영향 없이 디스크에 동기화 하기 위해 두 가지의 플래시 기능을 백그라운드로 실행한다.
플러시 리스트 플러시
InnoDB 스토리지 엔진은 주기적으로 오래된 리두 로그 엔트리가 사용하는 공간을 비워야한다. 그런데 이게 지워지려면 InnoDB 버퍼 풀의 더티 페이지가 먼저 디스크로 동기화되어야 한다. 이를 위해 InnoDB 스토리지 엔진은 주기적으로 플러시 리스트 플러시 함수를 호출해서 플러시 리스트에서 오래전에 변경된 데이터 페이지 순서대로 디스크에 동기화하는 작업을 수행한다.
LRU 리스트 플러시
InnoDB 스토리지 엔진은 LRU 리스트에서 사용 빈도가 낮은 데이터 페이지들을 제거해서 새로운 페이지들을 읽어올 공간을 만들어야 하는데, 이를 위해 LRU 리스트 플러시 함수가 사용된다.
<5> 버퍼 풀 상태 백업 및 복구
InnoDB 스토리지 엔진은 MySQL 서버가 셧다운 되기 직전에 버퍼 풀의 백업을 실행하고, MySQL 서버가 시작되면 자동으로 백업된 버퍼 풀의 상태를 복구하 ㄹ수 있는 기능을 제공한다.
<6> 버퍼 풀의 적재 내용 확인
innodb_cached_indexes 테이블을 활용하면 테이블의 인덱스별로 데이터 페이지가 얼마나 InnoDB 버퍼 풀에 적재되어 있는지 확인할 수 있다.
