Developing HFT System(2021) Review
Chapter3: Understanding the Trading Exchange Dynamics
Architecting a trading exchange for handling orders at a large scale
Components in Exchange
- Listing (상장)
- Matching Engine
- Post-trade
- 모든 주문이 올바르게 매칭되고 완료될 수 있도록 하는 작업
- trade capture, confirmation, matching, and reconciliation
- 백오피스 작업
- Market data
- Trade prices, trading volumes, firm announcements filing
- Market participants
- Regulation
Exchange architecture
Business requirements
- Front, middle and back office 모두 trading 가능하게 + algo trading 도 가능하게
- 개발 lifecycle 전반에 걸쳐서 backtesting, live execution 가능하게 해야함
- trading ui 지원 (hts mts 같은거)
- open api 로 trading 할 수 있는 TaaS(Trading as a Service) business model 도 지원 ex. FIX Protocol 같은거
- 다양한 상품 지원
- High Scalable 하게 만들어야함
Trading exchange architecture
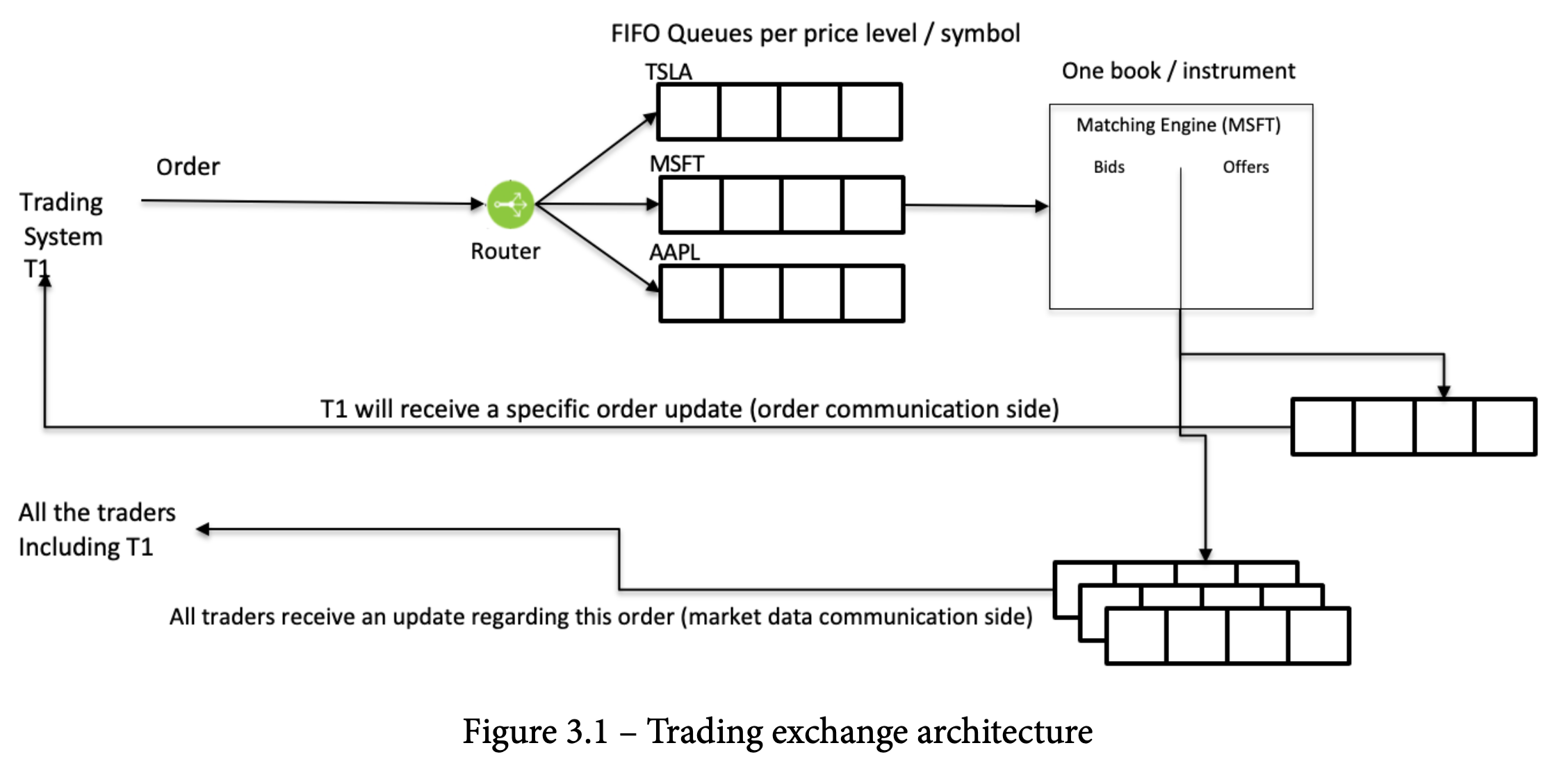
- 상품 종류(TSLA, MSFT)에 따라 주문은 큐에 라우팅 됨. 각 큐는 하나의 price와 symbol을 가짐
- 메칭엔진은 order을 순차적으로 한번에 하나씩 처리
- Orderbook에 변화가 있으면 모든 market participations에 제공됨
Communication Portocol
- String based인 FIX protocol은 충분히 빠르지 않음..
- 따라서 대부분 거래소들은 빠른(micro second 단위) Binary based protocol 을 선호함
General order book and matching engine
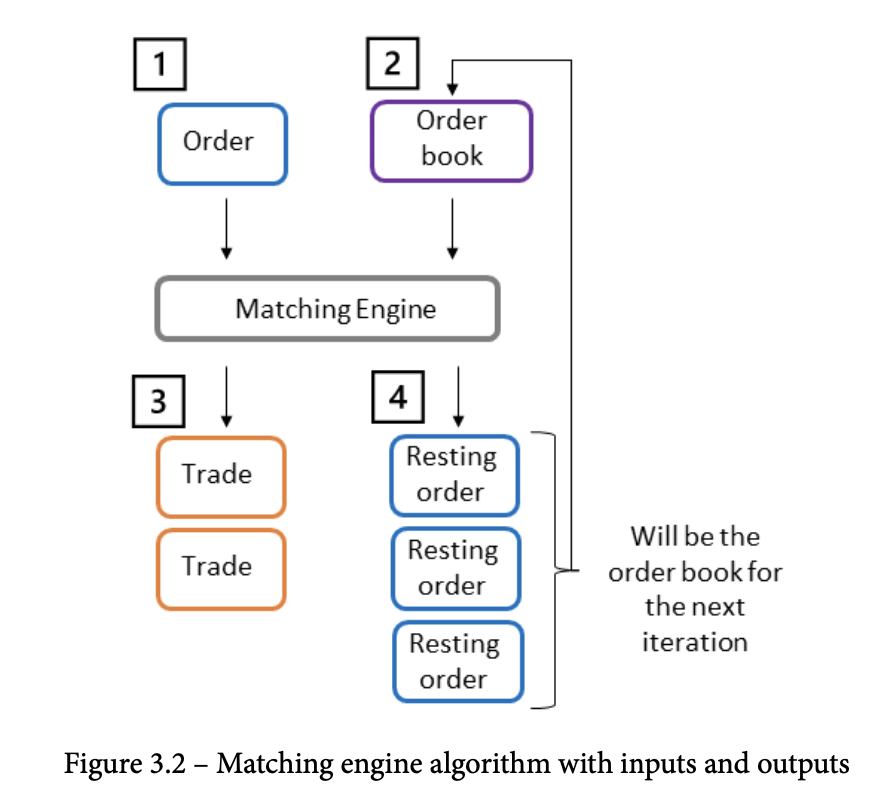
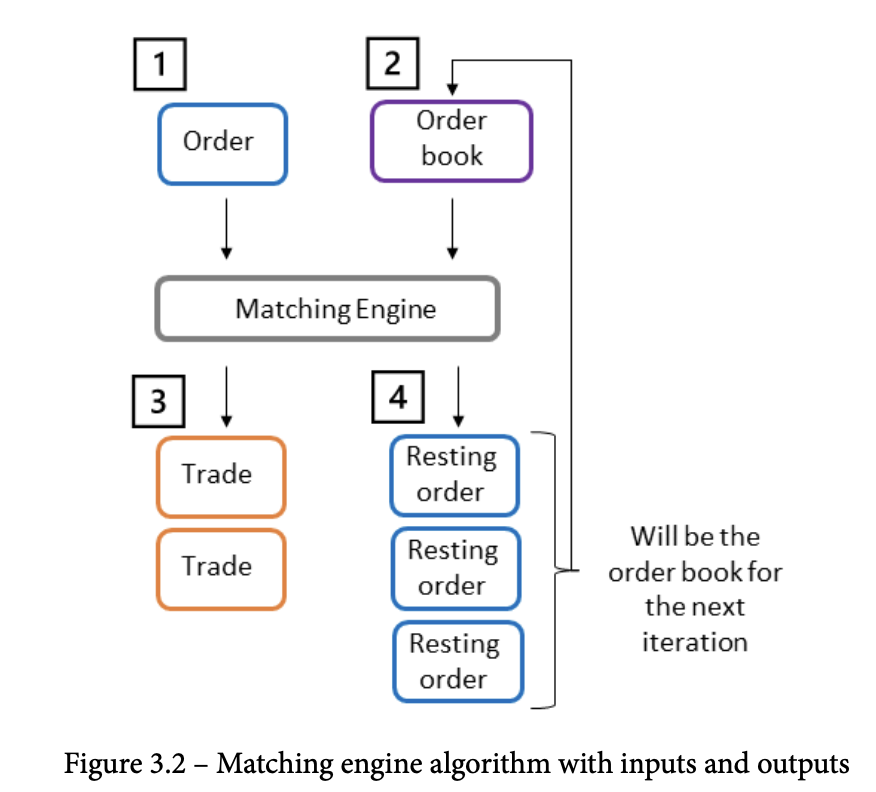
Matching Algorithm
- input : order, orderbook
- output : trades, resting orders
Best price scenario
가상의 orderbook
| Ask quantity | Ask(sell) price | Bid(buy) price | Bid quantity |
|---|---|---|---|
| 100 | $102.00 | ||
| 100 | $101.00 | ||
| $100.00 | 100 | ||
| $99.00 | 100 | ||
| - `$99.00 | 100주 | 매도 주문` |
- matching engine은 매도자에게 유리한 가격(best price)인 `$100.00`으로 매칭 시켜준다.$102.00 | 100주 | 매수 주문- matching engine은 매수자에게 유리한 가격(best price)인
$101.00으로 매칭 시켜준다.
- matching engine은 매수자에게 유리한 가격(best price)인
만약 두 quantitiy 가 다르다면?
Partial fill scenario
가상의 orderbook
| Ask quantity | Ask(sell) price | Bid(buy) price | Bid quantity |
|---|---|---|---|
| 100 | $102.00 | ||
| 100 | $101.00 | ||
| $100.00 | 100 | ||
| $99.00 | 100 | ||
| - `$99.00 | 20주 | 매도 주문` |
- matching engine은 매도자에게 유리한 가격(best price)인 `$100.00`으로 매칭 시켜준다.
- 그러나 아직 `$100.00` 호가에는 100 - 20 = `80` 남아있음.$102.00 | 20주 | 매수 주문- matching engine은 매수자에게 유리한 가격(best price)인
$101.00으로 매칭 시켜준다. - 그러나 아직
$101.00호가에는 100 - 20 =80남아있음.
- matching engine은 매수자에게 유리한 가격(best price)인
앞선 두 예시는 유동성이 넘처나는(호가가 꽉 차있는) 시점에 가능한 시나리오. 그러나 유동성이 부족(호가가 비어있으면) 어떻게 될까?
No match scenario
가상의 orderbook
| Ask quantity | Ask(sell) price | Bid(buy) price | Bid quantity |
|---|---|---|---|
| 7 | $102.00 | ||
| 10 | $101.00 | ||
| $100.00 | 0 | ||
| $99.00 | 5 | ||
| - `$101.00 | 5주 | 매도 주문` |
- matching engine은 `best price` 를 찾지 못해서 `$101.00` 에 물량을 추가시킨다.
- 그래서 `$101.00` 호가에는 10 + 5 = `15` 가 남아있음.$100.00 | 20주 | 매수 주문- matching engine은
best price를 찾지 못해서$100.00에 물량을 추가시킨다. - 그래서
$100.00호가에는 0 + 20 =20가 남아있음.
- matching engine은
Multiple orders with the same price
같은 가격에 주문들이 들어오는 경우는 어떻게 할까? → exchange 의 matching algorithm 마다 방법이 다르다.
대표적인 2방법 이 있다.
FIFO
- timestamp 기준으로 match 시킨다
- order가 matching engine으로 들어온 timestamp 기준(각 다른 order가 같은 시점에 들어올 수 없음)을 가지고, 낮은 timestamp 부터 match 됨
modification(정정주문)을 하게되면 priority는 사라지게됨수량 정정은 exchange에 따라서 priority가 바뀔 수도 있고 아닐 수 도 있는데,가격 정정은 모든 exchange에서 무조건 priority를 잃게 됨 새로운 주문으로 인식해서- 가장 widely 하게 사용되는 알고리즘이다.
Pure pro-rata
- 비율대로 메칭시켜주는 알고리즘
- order quque
buy quantity buy price order num # sell quantity sell price order num # 20 $100 #1 40 $100 # 2 20 $100 # 3 20 $100 # 4 #2sell order는 전체 sell order의 50%(40/80)을 차지하니, buy order의 50%인 10주가 채결된다.#3sell order는 전체 sell order의 25%(20/80)을 차지하니, buy order의 25%인 5주가 채결된다.#4..
- timestamp 상관없이 진행됨
Other forms of pro-rata matching(Pro Rata with TOP)
- 앞선 pro-rata 알고리즘을 그대로 가지고있으면서,
- 추가적으로
counter order(best price에 matching이 될 수 있는 호가로의 주문)을 넣으면 이건 timestamp 가 낮을수록 (오래된 주문일 수 록) 먼저 matching이 되도록 해주는 알고리즘 - 나머지는 다 pro-rata로 한다.
CME 거래소의 matching algorithm
Supported Matching Algorithms - Electronic Platform Information Console - Confluence
Chapter4: HFT System Foundations – From Hardware to OS
Understanding HFT computers
- HFT server가 가져가야하는 기능들은?
- Receiving market data
- Executing algorithmic models
- Sending orders to an exchange
- low latency 를 달성하려면 고려해야할 사항
- 작성한 코드가 어떻게 cpu에서 실행되는지?
- trading system에서 사용되는 다양한 hardwares과의 dataflow가 어떤지?
CPUs, from multi-processor to multi-core
- 한 cpu가 handle 하는 work flow를 보면
- network interface에서 market data가 들어오면
- → parsing
- → 다양한 components에서 사용
- → strategy 에서 trigger된 order를 exchang에 보내는 작업
- 여기서 한 cpu 가 위 작업을 처리한다는 뜻은 → 한번에 한 packet만 작업 가능하다는 뜻 → packet이 쌓일 수 있음.
- 따라서 병렬 처리가 필요함 → multi-core cpu 를 통해 한다.
- 특히 최신 multi-core cpu 는 NUMA 를 통해 memory 또는 io 장비에 더 빠르게 접근 가능하도록 해줌.
A note about hyper-threading and simultaneous multithreading
- hyper-threading 이란
- 한 물리적 코어 내에서 상태 관리가 가능한 2개의 스레드를 즉 논리적 코어 2개를 만들 수 있는 기술
- 이렇게 하면 코어수가 2배가 되어서 이득처럼 보이지만,
- 하이퍼 스레딩에서는 실제 물리 코어가 1개니까 작업이 2개라도 각각 동시에 실행이 되는게 아니라 각 작업이 context switching이 일어나면서 진행이됨.
- 따라서 결국 더 노이득
- 그리고 가장 큰 문제는 이 하이퍼 스레딩의 task switching 을 software-level에서 조작 할 수 없다는점.
- 이 기능을 비활성화를 추천
Main memory of RAM
- hft에서 RAM은 좀 느림
- NUMA 아키텍쳐가 각 cpu에 램이 있는 형태인데 이것도 트레이딩 펌에서는 별로임 (remote NUMA node에 접근할때 레이턴시가 걸리기 때문) -> 따라서 Cache라는게 나옴
Caches
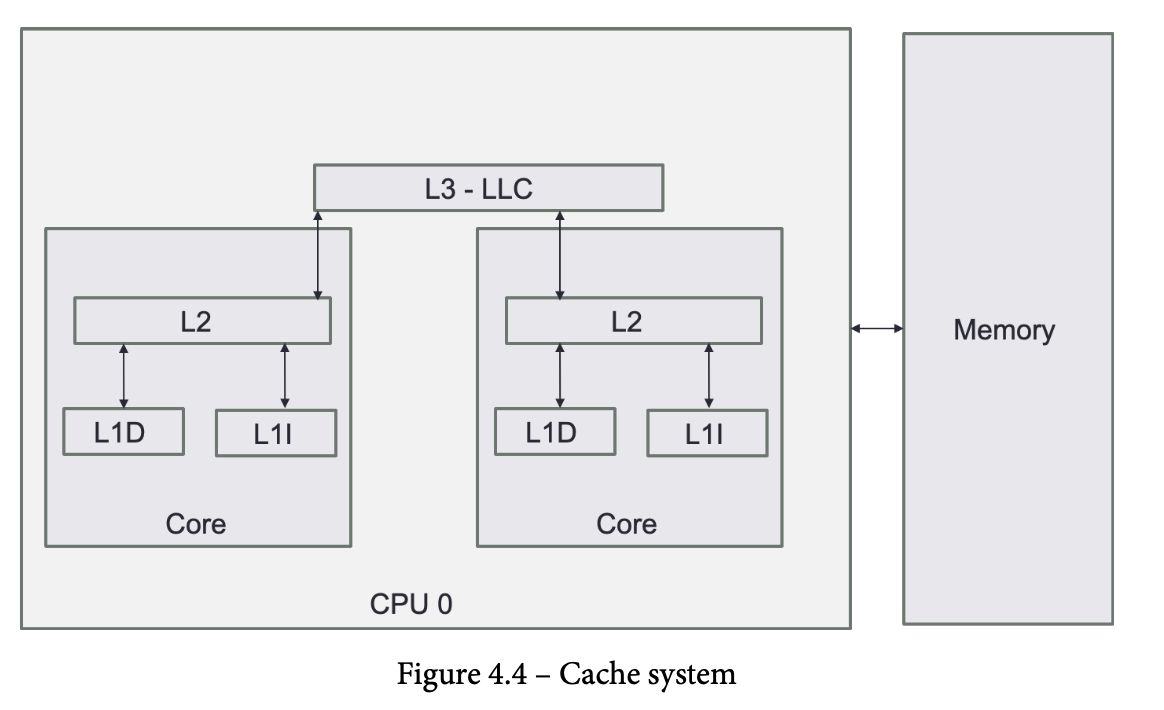
Cache structure
- cache 는 memory와는 다르게 byte로 읽는게 아니라
cache line으로 읽는다. - 만약 새로운 cache line을 읽으려면 원래 cache line을 퇴출 시켜야하는데
least-recently-used(LRU)라는 방법을 자주 사용함(다른 방식도있음) - 다양한 레벨의 cache가 존재하는데 각각 다 cache size가 다름
- data structure 를 cache line size에 맞추는것 중요
L1 cache
- 컴퓨터에서 가장 빠른 기억장치(cpu와 가깝게 위치함) (KB 크기)
- CPU 가 레지스터에 가장 최근에 접근하거나 로드한 데이터들을 가지고 있음
- CPU vendor에 따라서 size가 다름
- 2가지로 나뉨
- L1D: 데이터 저장공간
- L1I : cpu가 연산해야하는, 명령어들 정보 저장.
L2 cache
- L2는 L1보다 느리지만 더 크다 (대체로 256KB 에서 8MB 정도 크기)
- L2는 L1보다 성능면에서 뒤쳐진다. 그래도 램보다 빠름
- 일반적으로 L1이 RAM보다 100배 빠르고, L2는 25배정도 빠름)
L3 cache
- 가장 크기는 큰데 속도는 가장느림
- L3는 cpu core 모두에서 접근가능한 global 한 성향있다.
- L1, 2는 각 core에 종속적임
- L3 는 victim cache라고 불리기도 하는데, L1, 2 에서 퇴출된 cache line이 RAM으로 가기전에 L3로 가기 때문
Shared memory
UMA (uniform memory access)
- Single memory controller가 있고 모든 core는 이 single memory controller 와 소통함
- Single memory controller는 모든 CPU 와 바로 연결되어있는 또 다른 장치이다.
NUMA (non-uniform memory access)
- Memory controller들이 있고 cpu socket에 물리적으로 연결되어있음
- UMA < NUMA
- NUMA가 cpu 확장 빠르게 가능
- 이 확장은 동적으로 프로세스를 더 가져와서 사용하는게 아니라
- 시스템에 cpu를 추가로 설치하는 scale up 의 의미임
- 이유는 interconnecting NUMA node가 덜 복잡함
- 여러 cpu를 한 memory controller에 연결하는 것 과 같은 UMA보다 병목현상 줄여줄 수 있다
- 따라서 UMA 는 scale up 하기 힘들다.
- NUMA가 cpu 확장 빠르게 가능
- 요새 대부분 multiple socket server에서는 NUMA 아키텍쳐를사용한다.
- 각 cpu soket은 물리적인 memory pool이 연결되어있다.
- 근데 특정상황에서 한 cpu가 다른 cpu의 메모리 풀에 있는 오래된 버젼의 데이터를 캐시할 수 있다.
- → 따라서 데이터의 일관성을 위해 cache coherency protocol을 사용함 (cache의 상태관리를 해준다고 생각하면 될듯)
- 근데 이상적으로 latency나 throughput 이 중요한 hft에서는 많이 쓰면 안되고 rarely 사용되어야한다.
HFT에서는?
- 이러한 SMP(UMA) or NUMA가 사용되니까
- 이런 shared memory 관련된걸 할때는 → 컴포넌트끼리 message 통신을 위한 data structure 구조와 시스템 구조를
잘디자인 하는게 요구됨.
- 이런 shared memory 관련된걸 할때는 → 컴포넌트끼리 message 통신을 위한 data structure 구조와 시스템 구조를
I/O devices
- HFT에서 제일 중요한 io device는 network card이다.
- 대부분 io device는 PCIe를 통해 cpu와 연결됨 → 앞서말했듯이 NUMA infra에 직접적으로 연관되게됨
- Trading system을 만들때, 어떤 cpu에 market data gateway를 연결할지 고민해봐야하는거다.
- 최소한의 latency를 갖도록 가깝게 유지해야함
Using the OS for HFT systems
- HFT는 결국 os에서 실행되는데,
- os는 어떻게 프로그램이 실행될지, 메모리 관리, 디바이스 접근 등 이런 내용들이 매우 추상화되어있다.
- 그래서 latency를 줄일려면 이 추상화를 뚫고 적절하게 hardware와 소통해야함
- OS 의 features
- Hardware 리소스에 대한 추상화된 접근
- 프로세스 스케줄링
- 메모리 관리
- 데이터 저장과 접근
- 다른 컴퓨터와 커뮤니케이션
- interruption 관리
- HFT에서는 앞선 os기능들 중에 프로세스 스케줄링이 메인 크리티컬 기능이다.
User space and kernel space
- Low latency trading에서 가장 힘든거는 hardware와 trading system간의 추상화를 최소한으로 하는거.
- data converting 최소화
- context switching 최소화
- hardware state 변경 최소화
Process scheduling and CPU resource management
- 앞서서 얘기했던것과 같이 trading system은 multi-core로 작업을 한다.
- 두가지 approach 가 있다.
- Preemptive multitasking
- Linux 그리고 대부분 OS는 Preemptive approach 를 사용
- timeslice해서 core가 독점 못하도록함
- Cooperative multitasking
- Realtime OS에서 사용되는 approach → 스케줄러나 다른 task 에 의해서 low-latency sensitive code를 중단받기 싫어서
- linux에서 cooperative multitasking이 가능한 폼이 있다.
- 특정 그룹을 real-time scheduling rule 적용하게 할 수 도 있음
- → 그러나 잘 써야함
- → 우선순위가 잘못되거나 deadlock이 걸릴수도있음
- Chapter 6에서 hft를 위한 os optimize에서 더 설명할거다.
- Preemptive multitasking
Memory management
- OS는 메모리 할당된 위치, 프로세스와의 mapping, 할당된 메모리용량 등등을 track 해야함
- Memory management unit(MMU)란?
- 실시간으로 physical 에서 virtual 로 매핑하여 cpu가 virtual address를 빠르게 알아내는것
- 실제로 memory management unit이 접근하는 공간은 physical address space이고 그 공간의 일부분을 cpu가 따로 할당해주는데 그게 virtual address space이다.
Paged memory and page tables
- 요새 OS는 어떤 프로세스가 어떤 데이터나 객체에 접근하거나 저장되었는지 모른다.
- → 대신에 os는 메모리의 system level의 기본 단위인
page에 촛점을 둔다. - → 페이지가 작은 경우 register에 저장되는데, 페이지가 큰경우 TLB 또는 memory에 저장
- → 대신에 os는 메모리의 system level의 기본 단위인
- virtual address 를 physical address로 바꾸는 과정을 빠르게 하기 위해 사용되는 캐시가 있는게 이게
TLB이다. - paging은 큰 퍼포먼스 저하를 일으킬 수 있다.
- → TLB에서 cache miss가 발생하면
- → os 는 memory에서 데이터를 로드 해야함
- hft에서는 특히 TLB cache miss를 줄여야하는데
- → 그 방법으로는 page 크기를 늘리는거다
- → Huge page라고 부르기도함
- → memory speed가 증가
- 그러나 huge page도 cost가 존재함
- → huge page를 추적하는 TLB가 커버하는 mapping이 줄어드니
- → 더 자주 메모리에 방문해야할수있음
System calls
- User space 와 kernel space와 통신하는 방법
- 대부분 os는 병목을 막기위해 커널 스레드를 여러개 두어서 각 system call 을 같은시간에 처리하도록 하고있음
- HFT에도 이러한 thread와 같은걸 쓰는 동시성 실행을 사용함
Threading
- 한 core안에 있는 thread들은 메모리 공간을 공유하기 때문에 접근할때 훨씬 빠르다.
- 그리고 thread 끼리의 context switching 시간도 process들 끼리 보다 짧다.
- process 끼리 통신할때 좀 더 많은 cost 가 든다.
- 6장에서 자세히 설명 예정이라고 되어있다.
Interruption management
- context switching을 만들어낼 수 있는 Interruption 수를 제한 하는게 중요함
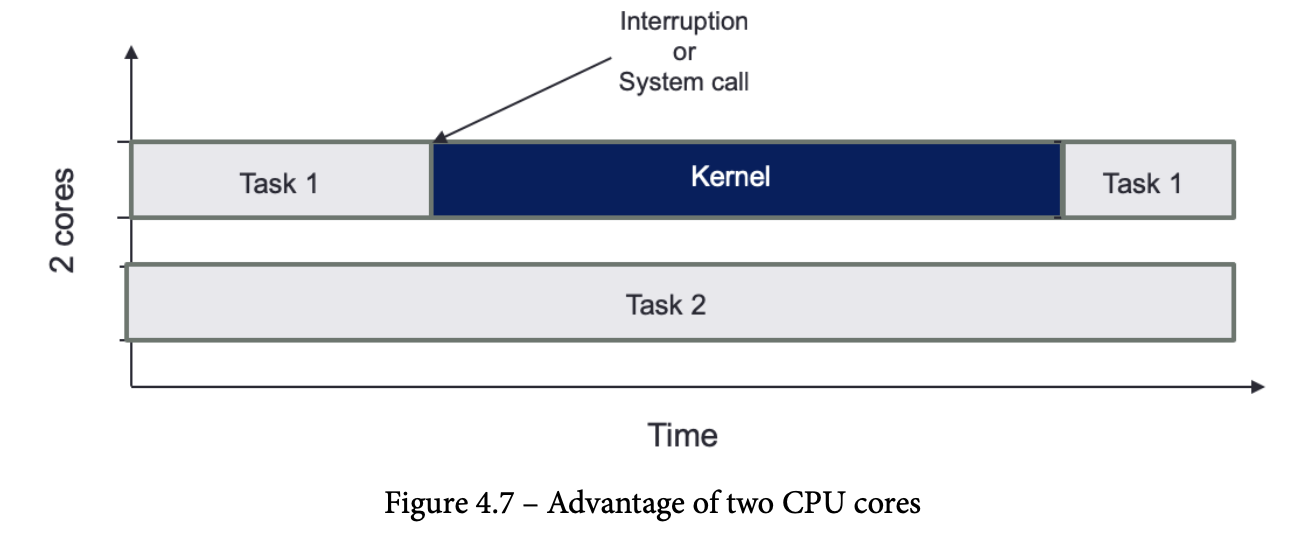
- pinning task to a given core 에 대한 그림
- 이 방법또한 6장에서 자세히 설명 예정이라 되어있다.
The role of compilers
- code → machine language 로 바꾸는 작업
- Space-time tradeoff
- memory or cache 사용 증가 → 실행시간 줄임
- Space-time tradeoff 페러다임에 기반한 최적화 방법들
- Loop unrolling
-
루프를 안쓰고 직접 hard coding 하는것
// before optimization for (int i = 0; i < 4; i++) { if (i == 2){ array[i] == -1; } array[i] = i * 2; } // after optimization array[0] = 0 * 2; array[1] = 1 * 2; array[2] = -1; array[3] = 3 * 2; -
종료 조건 x, 배열 offset이 상수, 중간에 조건도 없음
-
- Function Inlining
-
함수 호출을 해당 함수 어셈블리 코드 자체로 대체 하는것
// before optimization int add(int x, int y) { return x + y; } int main() { int result = add(1, 2); printf("%d", result); return 0; } // after optimization inline int add(int x, int y) { return x + y; } int main() { int result = add(1, 2); printf("%d", result); return 0; }
-
- Table and calculation
-
또 다시 계산하는걸 피하기 위해 계산값 저장
// before optimization int fibonacci(int n) { if (n <= 1) return n; return fibonacci(n-1) + fibonacci(n-2); } int main() { printf("%d", fibonacci(10)); // 이 함수는 많은 중복 계산을 수행합니다. return 0; } // after optimization int fib[11]; // 10 이하의 수에 대한 피보나치 수를 저장할 배열 int fibonacci(int n) { if (n <= 1) return n; if (fib[n] != 0) return fib[n]; // 이미 계산된 값이면 재사용 fib[n] = fibonacci(n-1) + fibonacci(n-2); return fib[n]; } int main() { memset(fib, 0, sizeof(fib)); // 배열 초기화 printf("%d", fibonacci(10)); return 0; }
-
- Loop unrolling
Executable file formats
- Windows
- Portable executable (PE)
- Linux
- executable and linkable format (ELF)
Static versus dynamic linking
Static linking
- Pros
- 실행파일이 외부 라이브러리와 의존하지 않는다 → 배포가 쉽다.
- 컴파일러와 링커가 전체 애플리케이션과 외부라이브러리에 대해 최적화를 할 수 있다.
- 라이브러리의 버젼 호환성 문제를 없에준다.
- 실행시간에 외부라이브러리를 찾거나 로드하는등 오버헤드를 줄여줄 수 있다.
- Cons
- 같은 라이브러리를 사용하는 여러 프로그램이 있을 경우, 각각의 실행파일에 라이브러리가 중복 로드되어 메모리 사용량 증가
- 프로그램 업데이트시 라이브러리 업데이트를 포함해서 전체 어플리케이션을 다시 컴파일하고 배포해야함
Dynamic linking
- Pros
- 여러 프로그램이 같은 라이브러리를 공유할 수 있어 메모리 사용량 줄일 수 있음
- 라이브러리 업데이트가 되면, 자동으로 업데이트된 라이브러리를 그대로 사용 가능.
- 실행파일 크기가 작아져서 배포에 효율적
- Cons
- 실행 시간에 필요한 라이브러리를 찾고 로드하는 추가 오버헤드가 발생
- 외부 라이브러리가 없거나 호환되지 않는 버젼이 있으면 실행에 실패할 수 도 있음
- 라이브러리 함수 호출시 PLT 간접참조로 인해 성능 저하가 발생할 수 있다.
HFT 에서는 그럼 뭘쓰나?
- 대부분 static linking 사용
