[ Background ]
The current project aims to build a recommendation model for cosmetic products.
More specifically, the current proeject aims to:
- utilise the ingredient lists of various cosmetic products
- focus on the order of an ingredient in individual product
- find a pattern in the order of the ingreide
The reasons for choosing the said approach are as stated below:
- the data for the exact dosage(amount or %) of each ingredient used in a product is often not accessible or requires significant amount of resources to obtain;
- the ingredients are always listed in order of prominence under the legal regulation (for ingredients whose percentages are higher than 1%).
Since the input data exists in a form a list of ingredients, Tokenization Process is not required.
Therefore, the focus is on researching different methods to convert a text sequence to a vector (Vectorization).
[ Vectorization ]
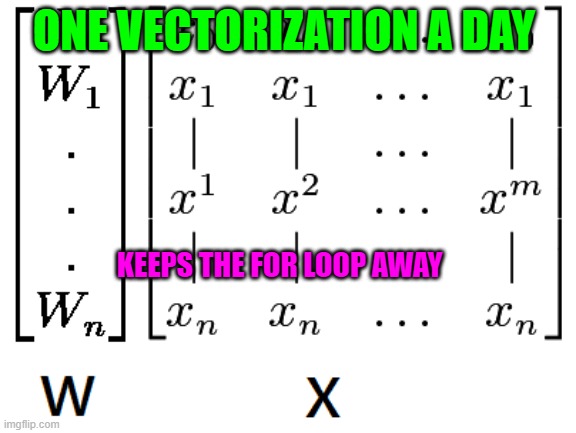
1. Word Vectors Aggregation
Word vectors aggregation is one of the popular and baseline approach if the vectors for the words are available or easily obtainable.
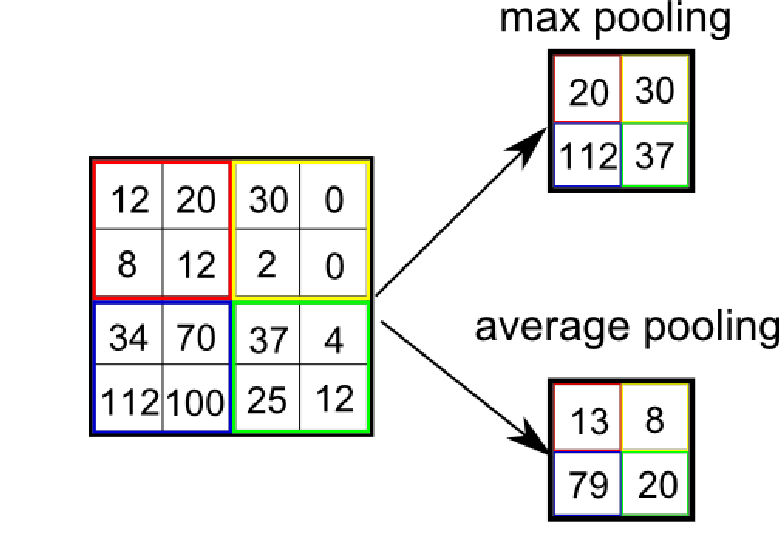
'Averaging' and 'Max-pooling' are two of the most frequent operations for aggreation.
- averaging
- max-pooling
2. Topic Modeling
Topic modeling obtains a hidden vector consists of dimensions that represent a topic.
Example of Topic Modeling
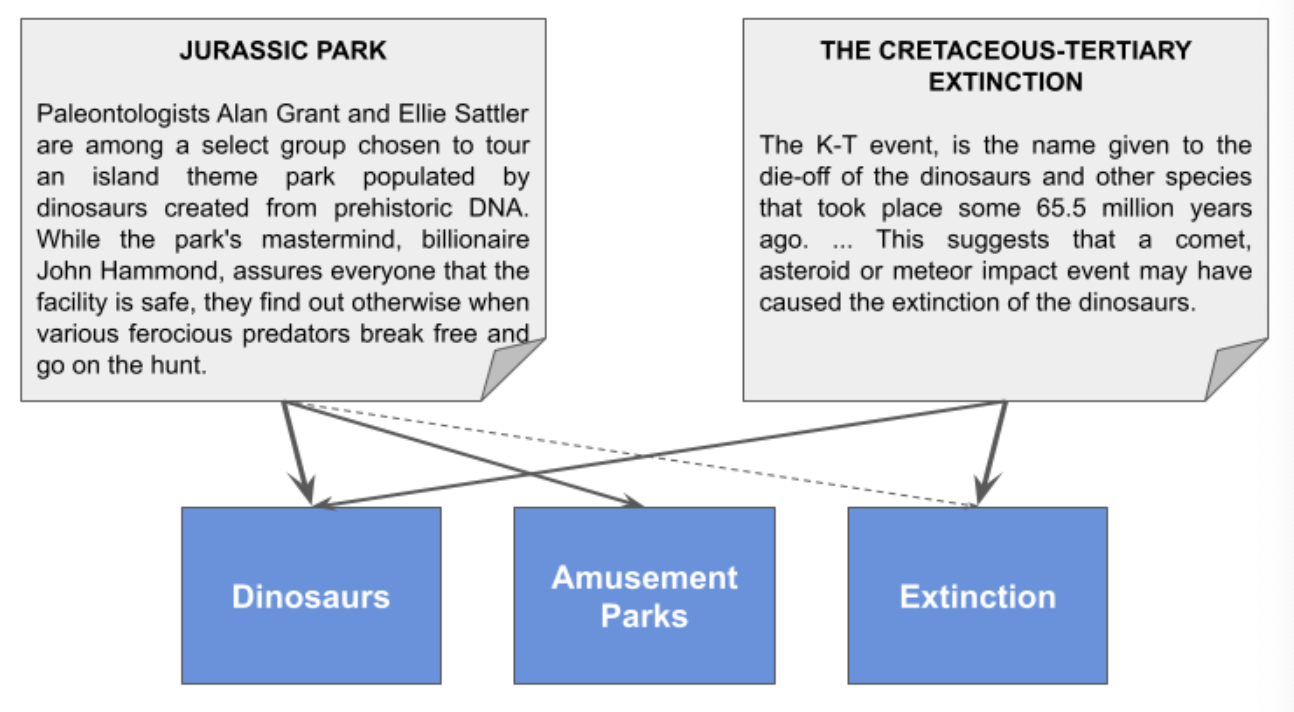
A vector: ["dinosaurs","amusement parks","extinctino"]
- "Jurassic Park" storyline : [1.0,0.6,0.05]
- "Cretaceous-Tertiary extinction" : [0.8,0.0,1.0]
3. Recurrent Models
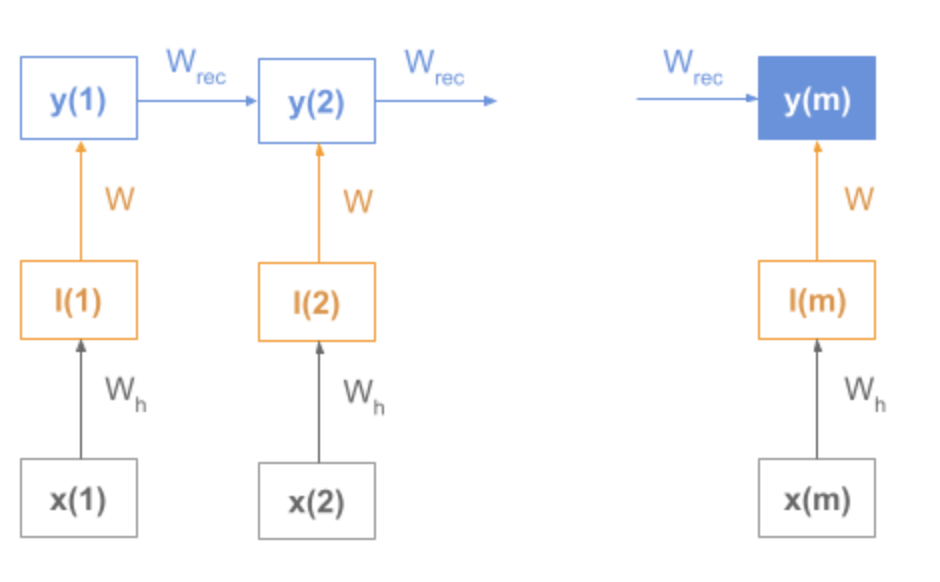
Recurrent models, utilise the innate ability of recurrent neural networks.
Recurrent models are composed of an encoder and decoder, where the encoder accumulates the sequence meaning and its internal final state is used as embeddings.
4. Bag of Words (BOW)
BOW technique vectorizes a text by using one dimension per word where the value represents the weight of the word in the text. It disregards the order and the syntax of a text.
Example of BOW
(1) John likes to watch movies. Mary likes movies too.
(2) Mary also likes to watch football games.
The vocab for the above sentences would be as below with the deletion of the stopwords(eg. "to").
V ={John, likes, watch, movies, Mary, too, also, football, games}
(1) [1,2,1,2,1,1,0,0,0]
(2) [0,1,1,0,1,0,1,1,1]
4.1 Existence of Words Strategy
(1) [1,1,1,1,1,1,0,0,0]
(2) [0,1,1,0,1,0,1,1,1]
-Indicates the presence of the word in the vector with 1,0
-All words are equally relevant
4.2 Words Count Strategy
(1) [1,2,1,2,1,1,0,0,0]
(2) [0,1,1,0,1,0,1,1,1]
- Count the occurrences of each word
- Higher values == higher relevance
4.3 Term Frequency (TF) Strategy
(1) [1/8, 2/8, 1/8, 2/8, 1/8, 1/8, 0/8, 0/8, 0/8]
→ [0.12, 0.25, 0.12, 0.25, 0.12, 0.12, 0.00, 0.00, 0.00]
(2) [0/6, 1/6, 1/6, 0/6, 1/6, 0/6, 1/6, 1/6, 1/6]
→ [0.00, 0.16, 0.16, 0.00, 0.16, 0.00, 0.16, 0.16, 0.16]
- Retains the relative frequency of words
4.4 Term Frequency-Inverse Document Frequency (TF-IDF) Strategy
Example of IDF values
[ln(2/1), ln(2/2), ln(2/2), ln(2/1), ln(2/2), ln(2/1), ln(2/1), ln(2/1), ln(2/1)]
→ [0.69, 0.0, 0.0, 0.69, 0.0, 0.69, 0.69, 0.69, 0.69]
TF-IDF:
(1) [0.12*0.69, 0.25*0.00, 0.12*0.00, 0.25*0.69, 0.12*0.00, 0.12*0.69, 0.00*0.69, 0.00*0.69, 0.00*0.69]
→[0.08, 0.00, 0.00, 0.17, 0.00, 0.08, 0.00, 0.00, 0.00]
(2) [0.00*0.69, 0.16*0.00, 0.16*0.00, 0.00*0.69, 0.16*0.00, 0.00*0.69, 0.16*0.69, 0.16*0.69, 0.16*0.69]
→[0.00, 0.00, 0.00, 0.00, 0.00, 0.00, 0.11, 0.11, 0.11]
- dinimishes the weight of words with high occurrence rate
5. Bag of N-Grams
Bag of n-grams is an augmented model that generates a vector from a text as combinations of words appear in a specific order.
→ the use of larger n-gram results in extesively lengthened vectors
6. Doc2Vec
Doc3Vec uses a special token D at the beginning of the text which represents the whole sequence, in accordance with the distributional hypothesis:
"words that occur in the same contexts tend to have similar meanings".
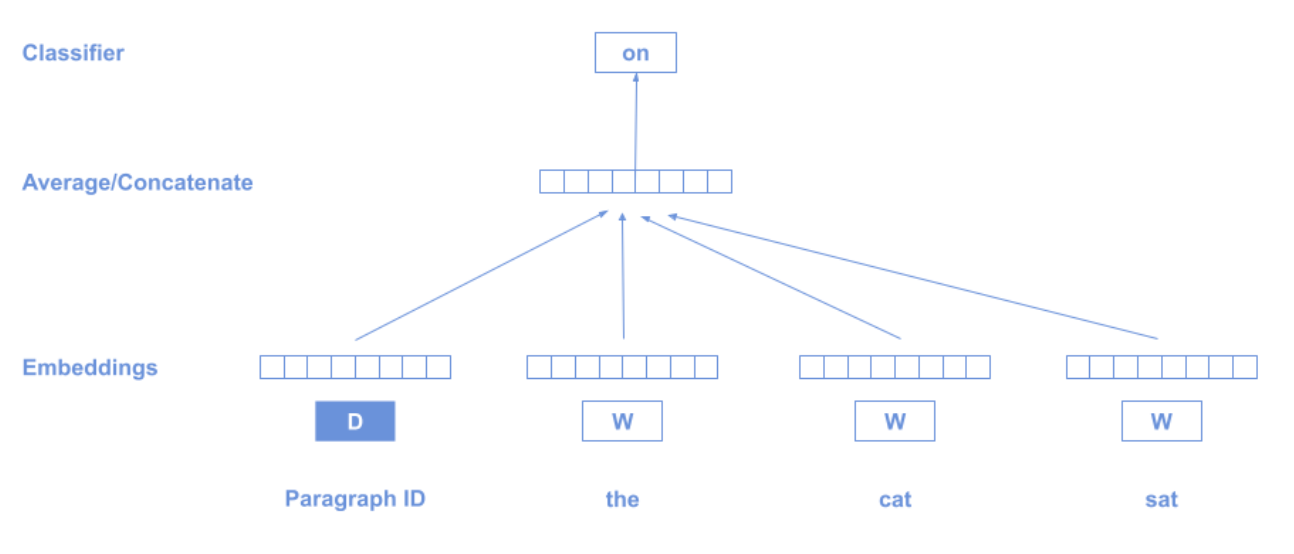
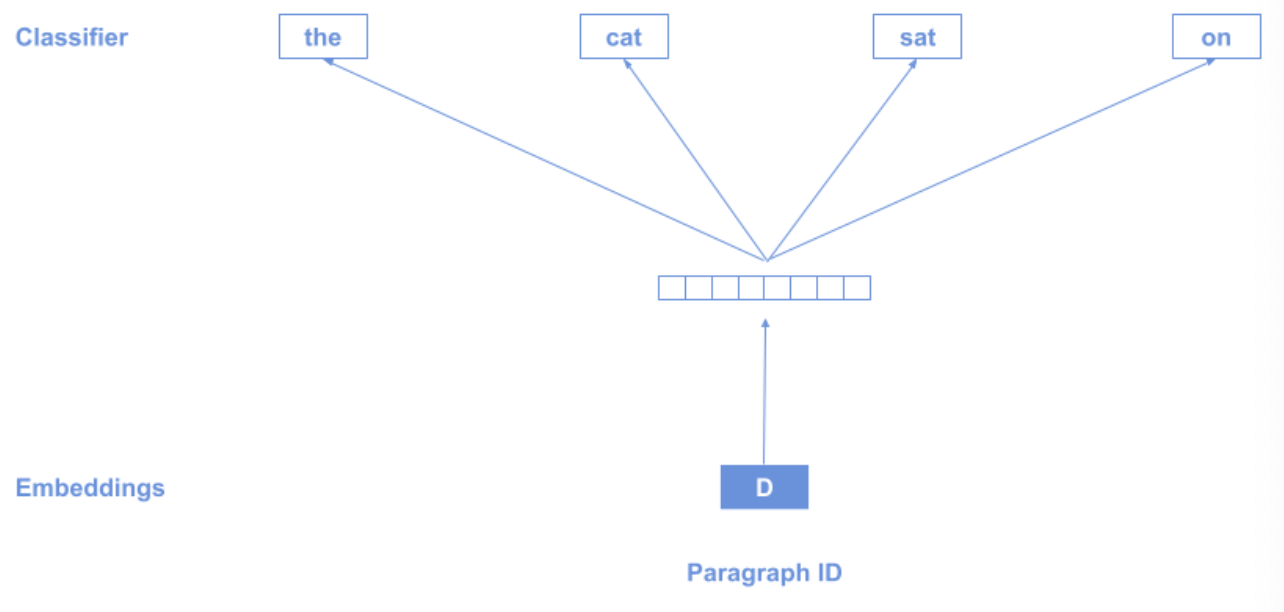
7. Biodirectional Encoder Representations from Transformer (BERT)
BERT produces a vector which represents the whole sequence via token[CLS], and for every token in the sequence.
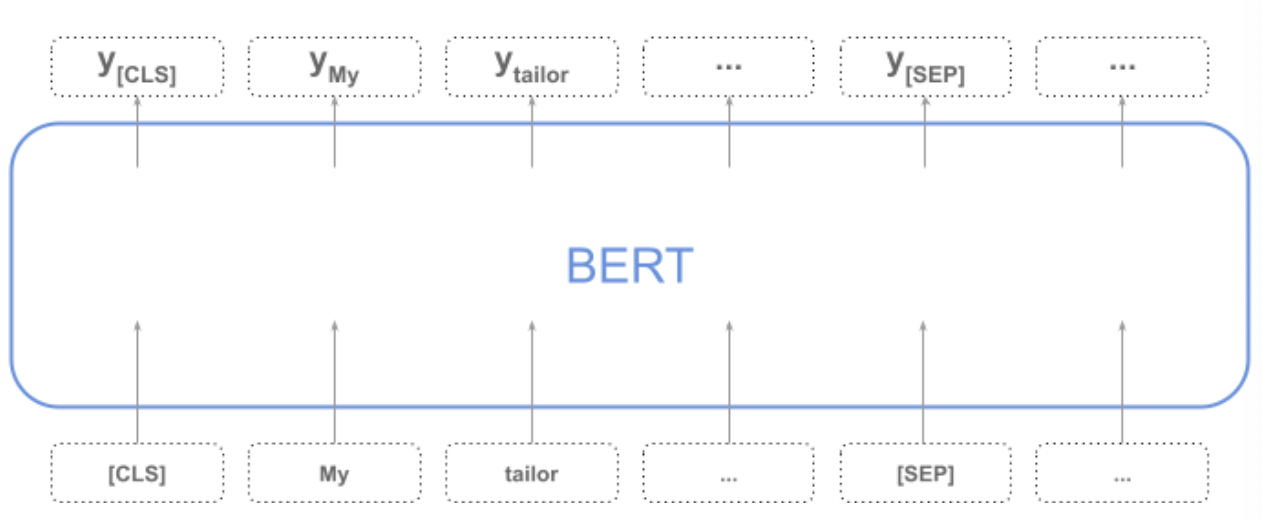
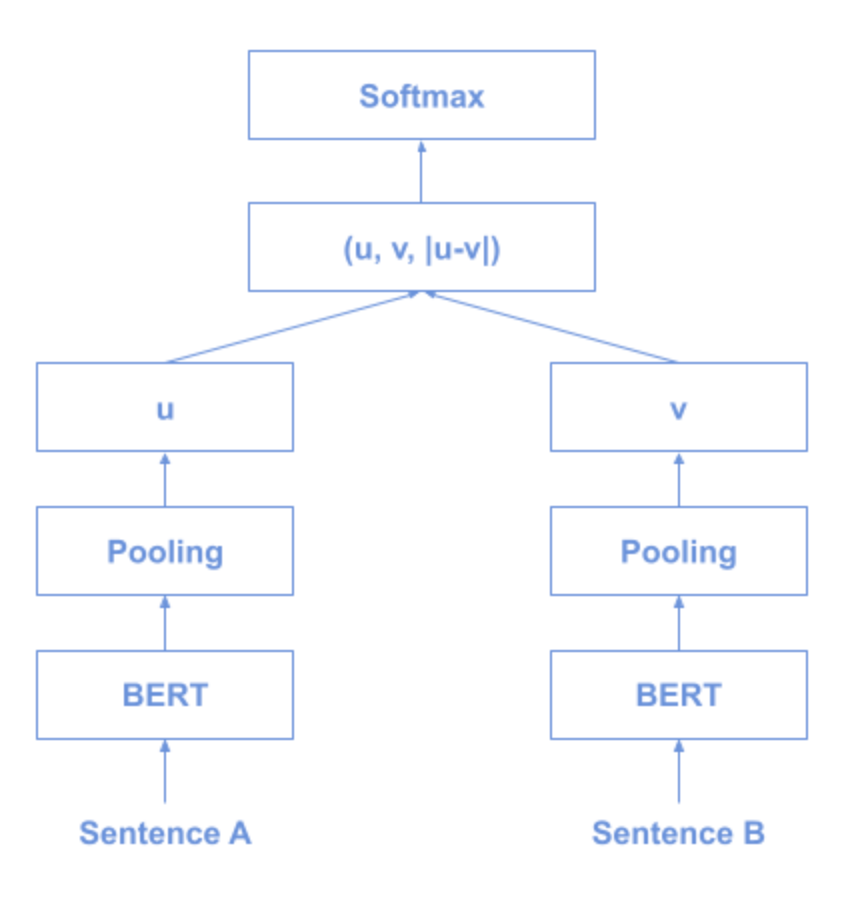
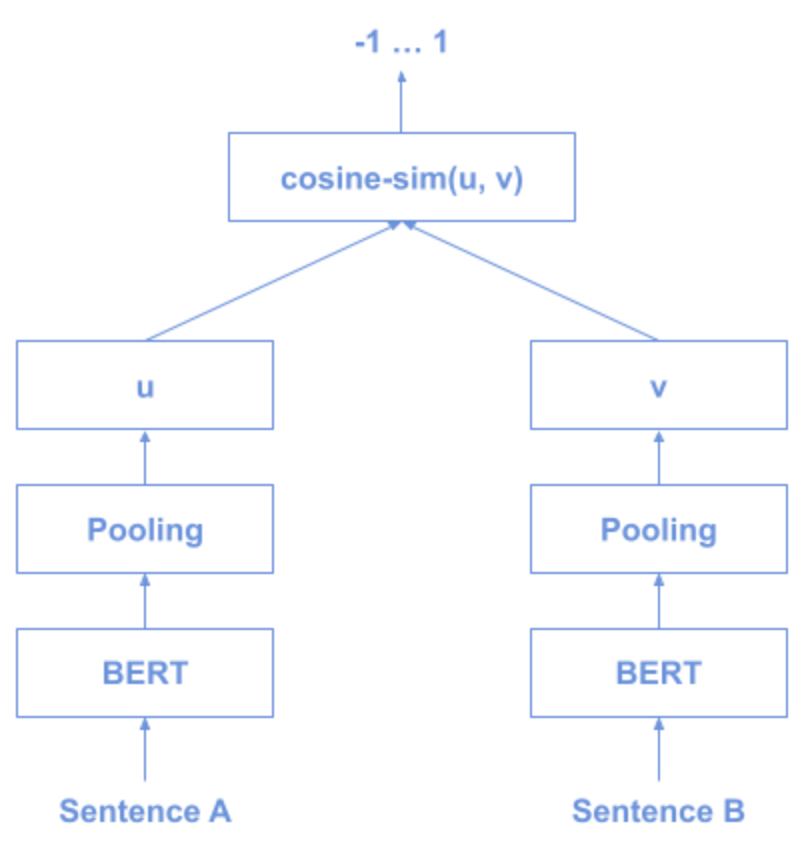
8. Sentence BERT (SBERT)
SBERT is a variant of BERT which specialises in the efficient comparison of sentences with following technique:
- use the siamese and triplet network structure
→derive semantically meaningful sentence embedding - use the cosine similarity to compare the sentences
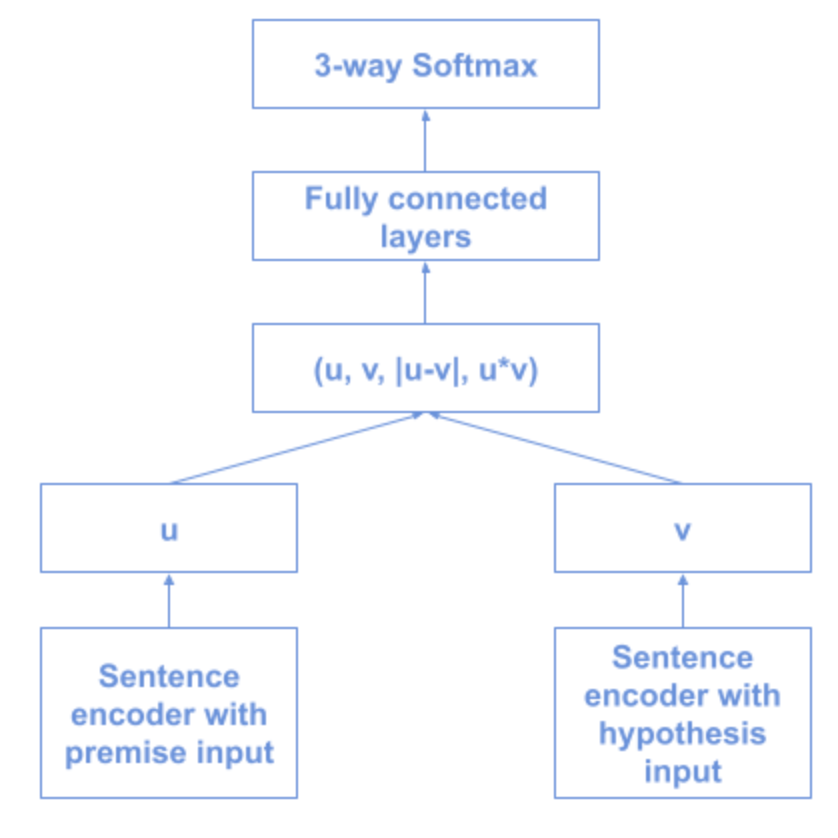
Training Architecture of SBERT
Inference Process With SBERT
9. InferSent (by Facebook)
InferSent is a sentence embedding method that provides semantic sentence representations.
It consists of training NN encoders of different architectures such as GRUs,LSTMs, and BiLSTMs on the Standford Natural Language Inference task.
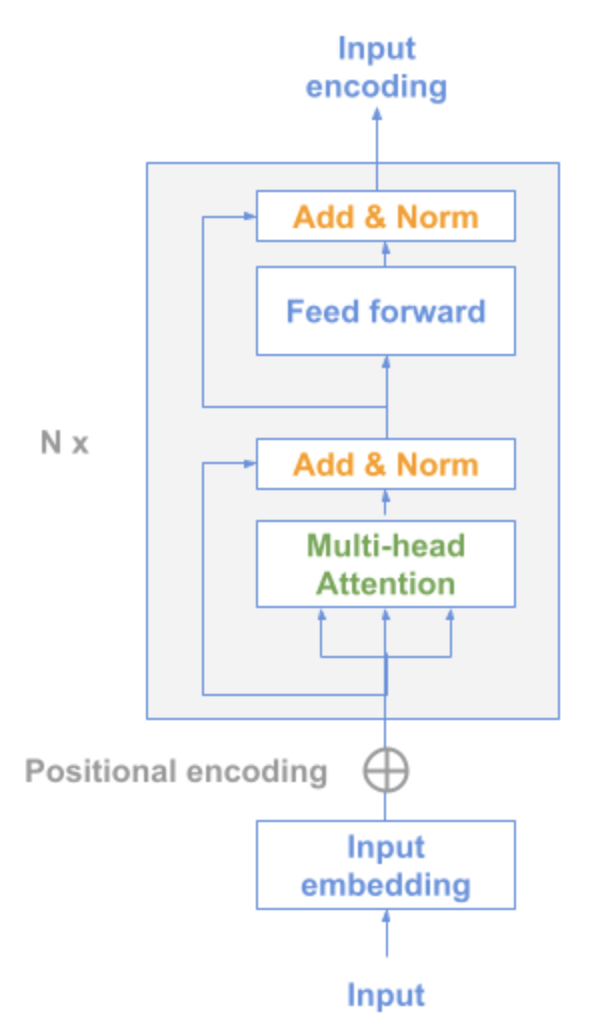
10. Universal Sentence Encoder (by Google)
Universal Sentence Encoder includes below two possible models with multi-task learning ability for sentence representation learning:
- Transformer model encoder
- Deep Averaging Network(DAN)
Transformer model encoder
DAN
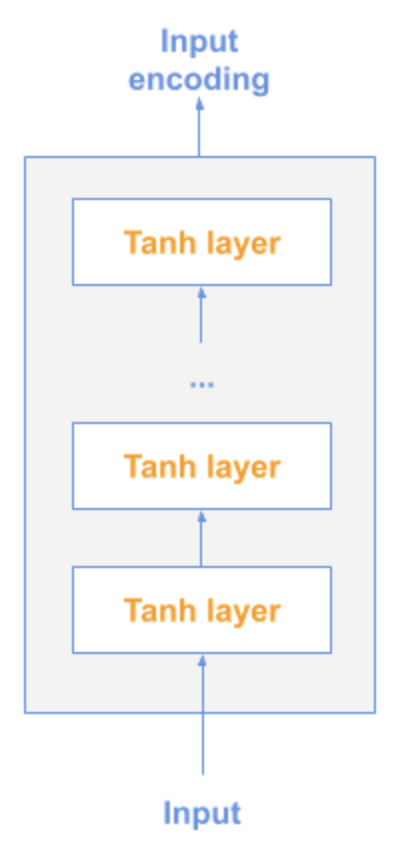
→ 1. average the input embeddings for words & the bi-grams
→ 2. Pass through a feedforward NN
