Transformer sinusoidal positional encoding
을 가장 잘 설명하는 블로그.
https://atonlee.tistory.com/56
RoPE와의 비교
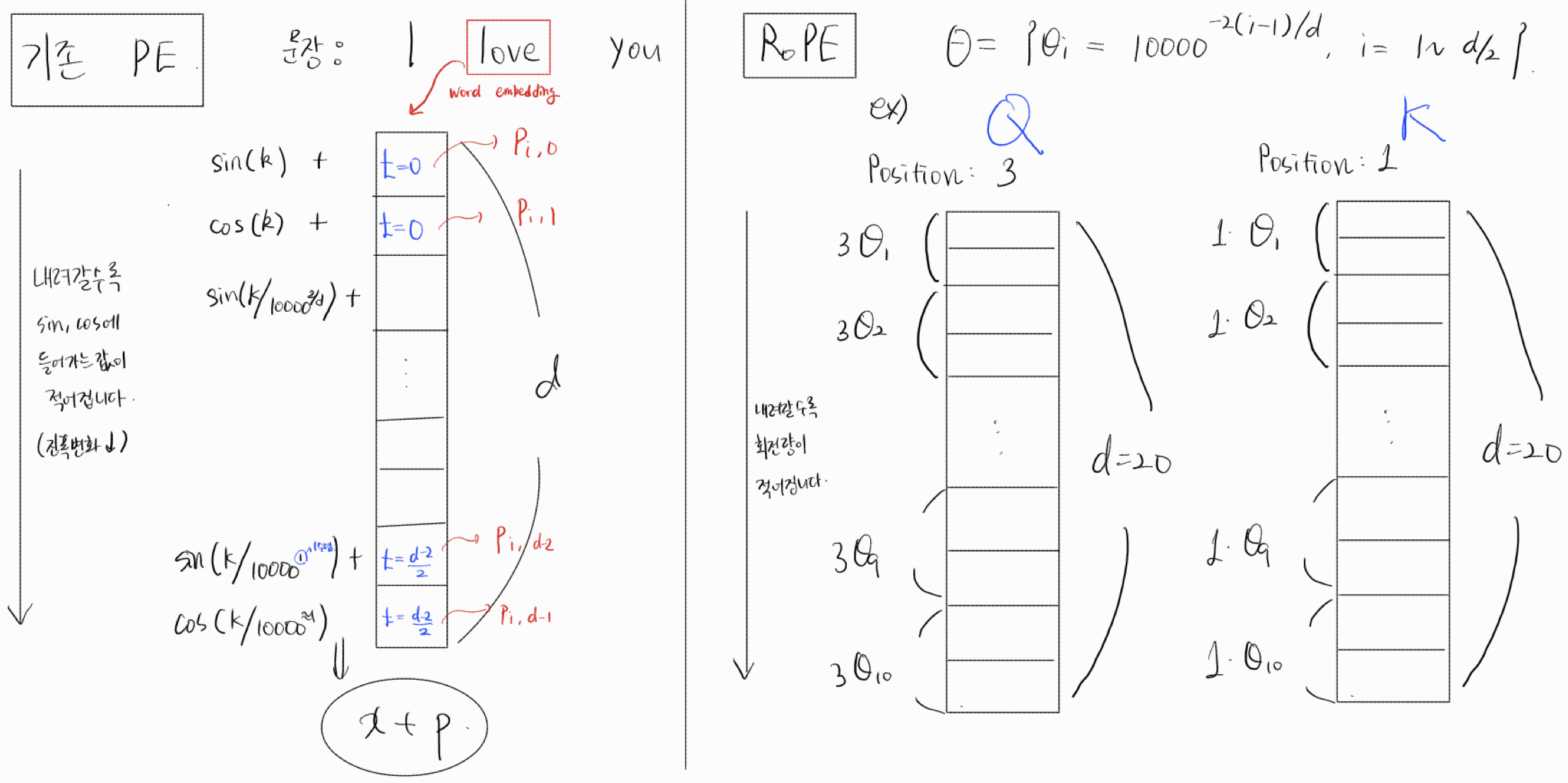
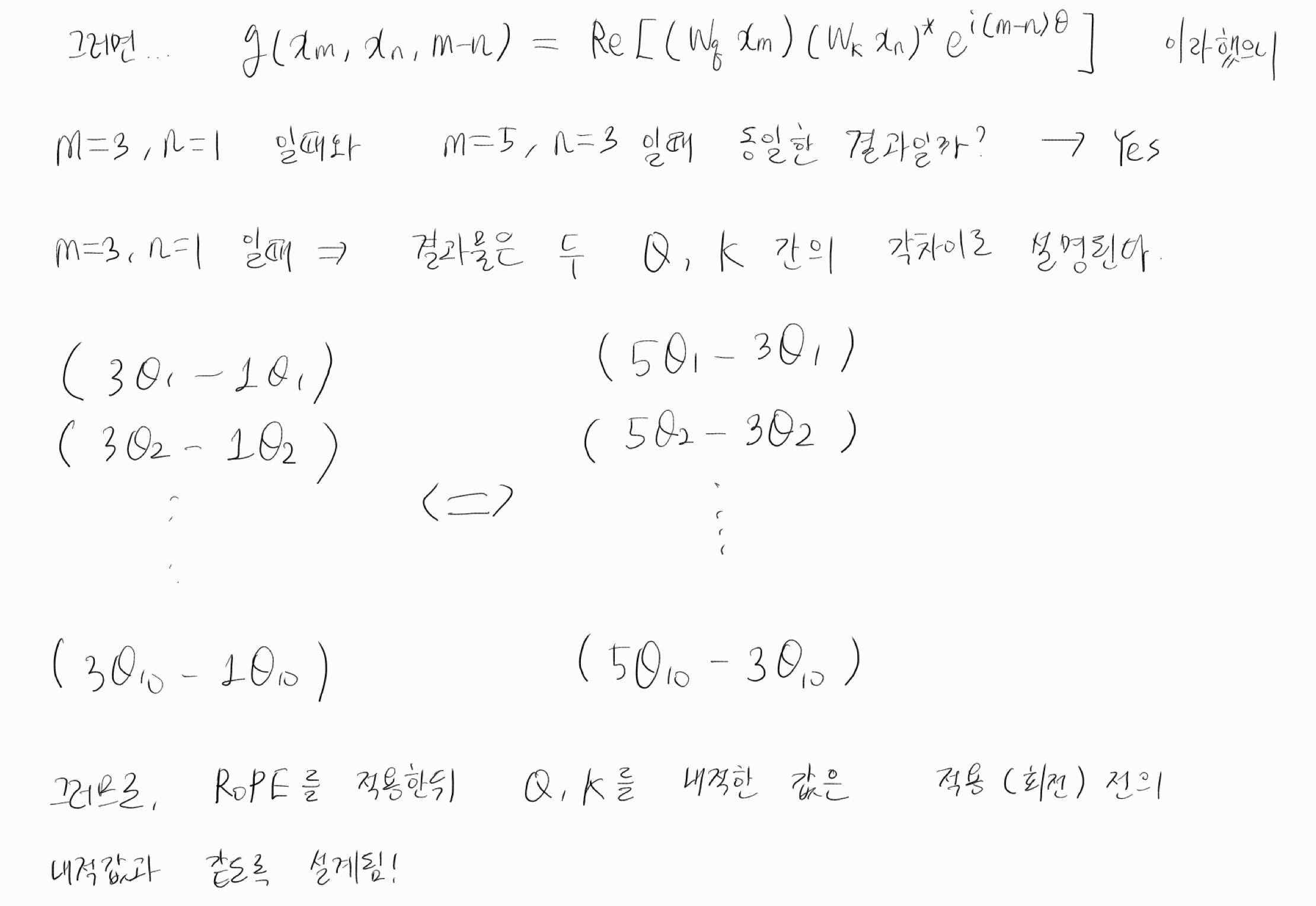
특징
기존 PE(sinusoidal) 방식과, RoPE가 비슷한 점은,
Positional encoding 적용시 더해지거나 회전되는 변화 값이, word embedding의 인덱스가 증가할수록 적어진다는 것.
sin(pos) -> ... -> sin(pos/10000) 으로 변화하며
RoPE에서 쓰이는 의 경우에도,
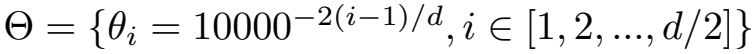
위와같이 i가 커질수록 가 작아짐을 확인 할 수 있다.
차별점
기존 트랜스포머에서 사용되는 PE(sinusoidal)의 경우, word embedding에 직접 더해지면서,
결국 퉁 쳐지게 된다. 32.12라는 벡터값이 있다면 여기서 0.12만큼만 PE인지, 0.02만큼만 PE인지 알 수 없다. 따라서, 기존 PE방식은 잘 되기는 하지만, 뭔가 더 좋은 방식이 필요함!
그래서 RoPE 방식은, 벡터에 회전을 주어, 어느 부분이 PE인지를 확실히 분리할 수 있다.
심지어 회전을 주기 전과 후의 QK 내적값은 동일하기 때문에 (사잇각의 차이가 보존되기 때문) 상당히 좋은 방법이라고 생각된다.

So far so good?