Contribution
- contrastive-learning-based VAE를 사용
- Mamba와 MLP만을 이용한, Autoregressive Diffusion 방식으로 Text-to-HOI generation 구현
☺︎ 참고) 기존의 Work들에서도 Autoregressive motion generation 을 사용하지만,
대표적으로 T2M-GPT나 Motion-GPT와 같은 연구에서는 Discrete tokenization을 통해서 진행 함.
하지만 해당 연구에서는 Continuous한 token을 활용하여 generation을 하는 것이 특징.
Representation
HumanML3D에서 제시한 방식을 사용하지 않고, SMPL 파라미터를 학습데이터로 그대로 사용한다.
(HumanML3D 방식은 속도기반 표현이고, 프레임을 적분해서 위치를 얻게되는데 이 과정에서 drift가 발생한다고 함. 또한 특정 프레임 하나만 봤을때 전역 위치/방향을 정확히 알 수 없는 한계 -> 아마도 Local한 방식으로 풀어내서 그런 듯.)
Human motion
: root translation = 3, joint rotation = 22*3 으로 추정.
Object motion
: combination of object tranlations and object rotation axis angles in the world system.
HOI data representation
cVAE (contrastive-learning-based VAE)를 사용한 이유
먼저, naive VAE와 VQ-VAE 방식의 단점을 알아야 함.
VQ-VAE 단점:
- 적은 데이터를 학습시, 일반화에 실패하게 됨.
- 사람의 손과 물체간의 미세한 접촉, 움직임 등의 연속적인 표현이 불가능함.
- 보지 못한 접촉 형태같은 경우, 가까운 토큰으로 강제 매핑되어 부정확하거난 부자연스러운 HOI 생성.
navie VAE 단점:
- Small dataset에 대해 Overfitting되는 경향이 있음. (rigid한 motion pattern으로 인해 일반화가 어려워짐)
- Human-Object간의 물리적으로 비현실적인 장면 등을 고려하지 않음.
(가령, 거의 비슷하지만 하나는 물리적으로 plausible하고, 다른 하나는 물리적으로 implausible한 두 HOI sample이 있다면, 두 샘플이 비슷한 latent space로 매핑되는 경향이 있음.)
요약하자면, task 특성상 VQ-VAE는 맞지 않는다고 판단 + 물리적으로 그럴싸한 접촉(손-물체) 시나리오를 컨트롤하기 위해서 자신들만의 VAE 학습 방식을 사용함.
cVAE 학습 방법
먼저 임의의 HOI motion에서, object의 translation에 small offset을 더해준다.
그러면 기존 데이터에서 변형이 일어나게 될텐데, 여기서 특정 조건을 걸어서 positive / negative 케이스로 나눈다.
positive case:
minimum, second-minimum contact distances가 특정 threshold만큼 늘어났으면 positive.
의미상, 접촉이 유지됨과 동시에 penetration을 더 피하는 쪽으로 안정화가 된 샘플들.
negative case:
그 외의 경우들
Training Objectives
저자는, Latent space에서 자신만의 방식으로 Good case와 Bad case 공간을 분리하려고 의도한 것이다.
(사실 위의 케이스 나누는 방식이 잘 이해 및 납득이 가진 않는다.)
위의 positive, negative case들을 가지고, 아래와 같이 VAE training loss중 일부를 구성한다.
여기서 는 HOI sequence 를 통해 만든 개의 토큰중에 번째 토큰이다. (토큰 = latent vector)
은 각각 에 대한 positive, negative case이다.
(여기서 살짝 의문이 생겼던 것이, 하나의 에대해 만큼의 미세값을 object translation으로 더한다면 그 샘플은 반드시 positive 혹은 negative에 매핑이 되어야 하는것이 아닌가? 했는데, 아마도 최소 두개 이상의 값을 준비해두고 에 대해 positive case와 negative case가 모두 존재할 수 있도록 사전 준비를 다 해놓는 듯 하다.)
다시 위의 를 해석해보면, 결국 setting 자체가 Anchor( : GT) case와 Positive case를 최대한 가까운 latent space에 배치시키고, Anchor와 Negative case는 멀리 떨어지도록 유도하는 Loss 이다.
(Loss는 클수록 안좋으므로 값이 커져야만이 Loss가 커지는데, 이 상황을 피하고자 하는 것이다.)
위의 Loss가 핵심 Loss이고, 그 외에도 유클리디안 거리로 reconstruction Loss , KL-divergence를 이용한 (용도: Latent token를 compact하게 구성), 를 통해 추가적인 규제들 (ex: Position error, velocity error, contact error) 을 구성하여 학습하였다.
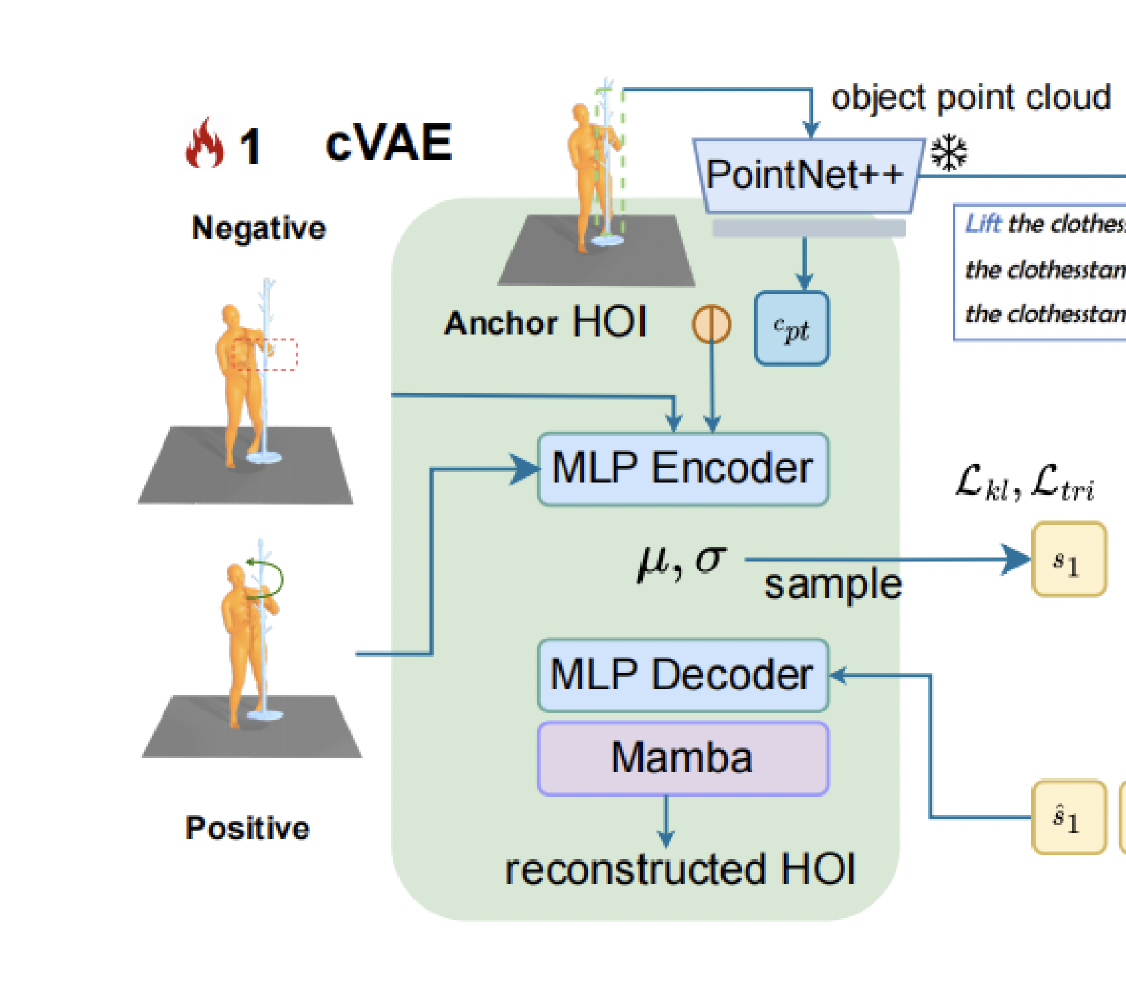
Object의 Point cloud를 PointNet에 넣어 얻은 값과, Anchor HOI 값을 MLP Encoder에 넣고,
이는 Gaussian latent space로 매핑이 된다. 그리고 인코딩된 토큰은 다시 MLP decoder로 들어간다.
MLP layer는 시간축에대한 구분이 없으므로 Mamba layer가 sequence dimension에 대한 처리를 해준다.
ARDM (Autoregressive Diffusion Model)
크게 두가지로 나뉘는데, 1) Context-Encoder, 2) MLP denoiser 가 있다.
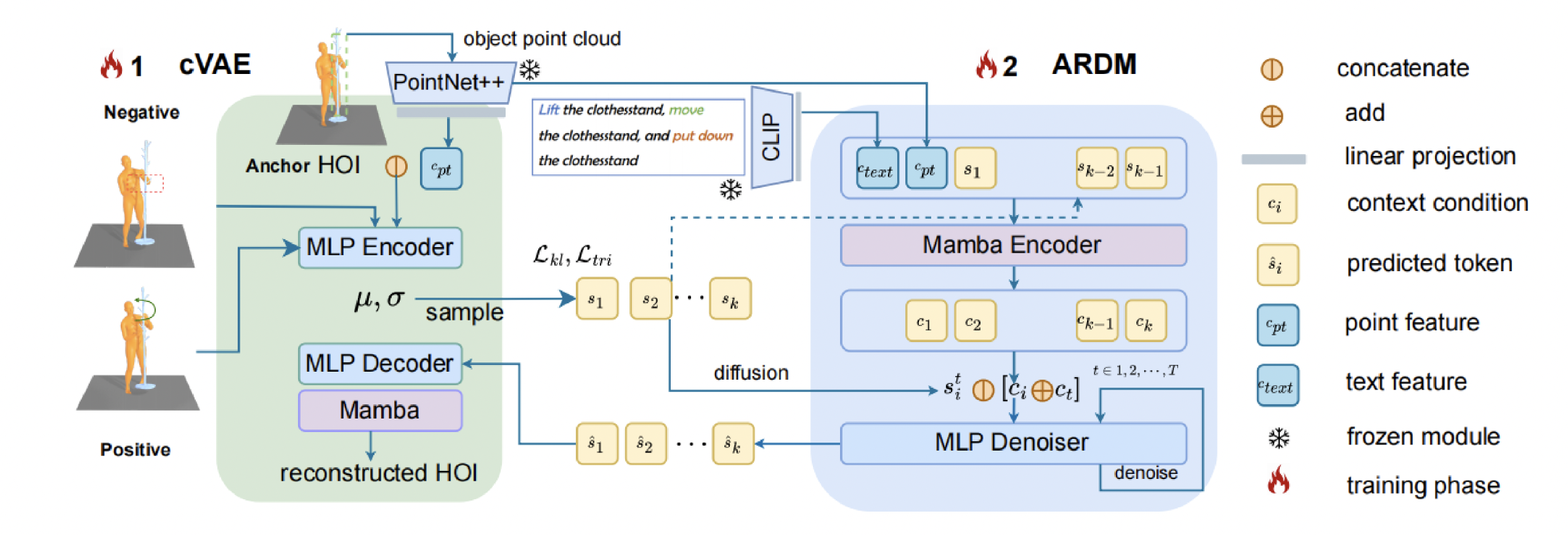
Context Encoder (Mamba Encoder)
Context Encoder의 역할은 context condition을 만들어내는 것이다.
그림을 보자.
Text는 CLIP을 통해 임베딩되고, Object point cloud도 PointNet으로 임베딩되어 각각 text feature, point feature가 된다. 그리고 cVAE에서 Latent vector token으로 존재하는 들이 함께 인코딩이 된다.
Next token을 예측하기 위해서 까지 인코더에서 입력으로 들어가고, Mamba Encoder는 를 내뱉는다.
그 후에, forward-process를 통해 noise가 가미된 와 context condition이 concat되어 MLP Denoiser로 들어간다. MLP Denoiser는 50step denoising과정을 거친뒤 denoised 된 token은 다시 cVAE의 MLP Decoder 로 전달 된다.
MLP Denoiser
구조는 아래와 같다.
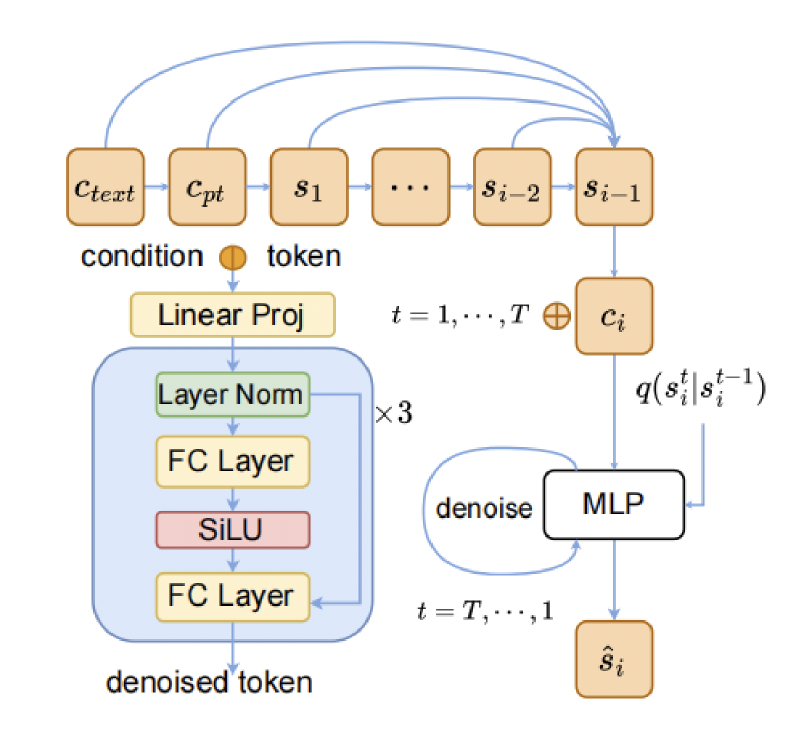
Training objective function for ARDM
=
위 식으로 봤을때, 오로지 와 만으로 를 구하게 되고, 그것을 실제 Forward process를 통해 식으로 구한 와 비교하여 Loss를 재는 것 같다.
cVAE와 ARDM의 시너지
기본적으로 Auto-Regressive model의 큰 문제가 에러의 누적이다.
연속적으로 다음 토큰을 예측하는 형태이기 때문에 초기 혹은 진행 도중의 시퀀스가 무너져버리면 점차 에러가 누적되는 형태인 것이다. 보통 이런 현상을 막기 위해서 masking, auxiliary discriminator 등의 추가 모듈을 사용하는데, 이것들이 계산비용 증가와 학습 복잡도 증가의 원인이 된다. (Inference도 느려짐)
그러나 해당 논문의 주장으로는, cVAE가 이미 plausible HOI token과 implausible HOI token을 잘 분리시켜 놨으니, Auto-Regressive inference 중에 이전 토큰이 조금 흔들리더라도, negative한 영역으로 쉽게 넘어가지 않는다는 점이다.
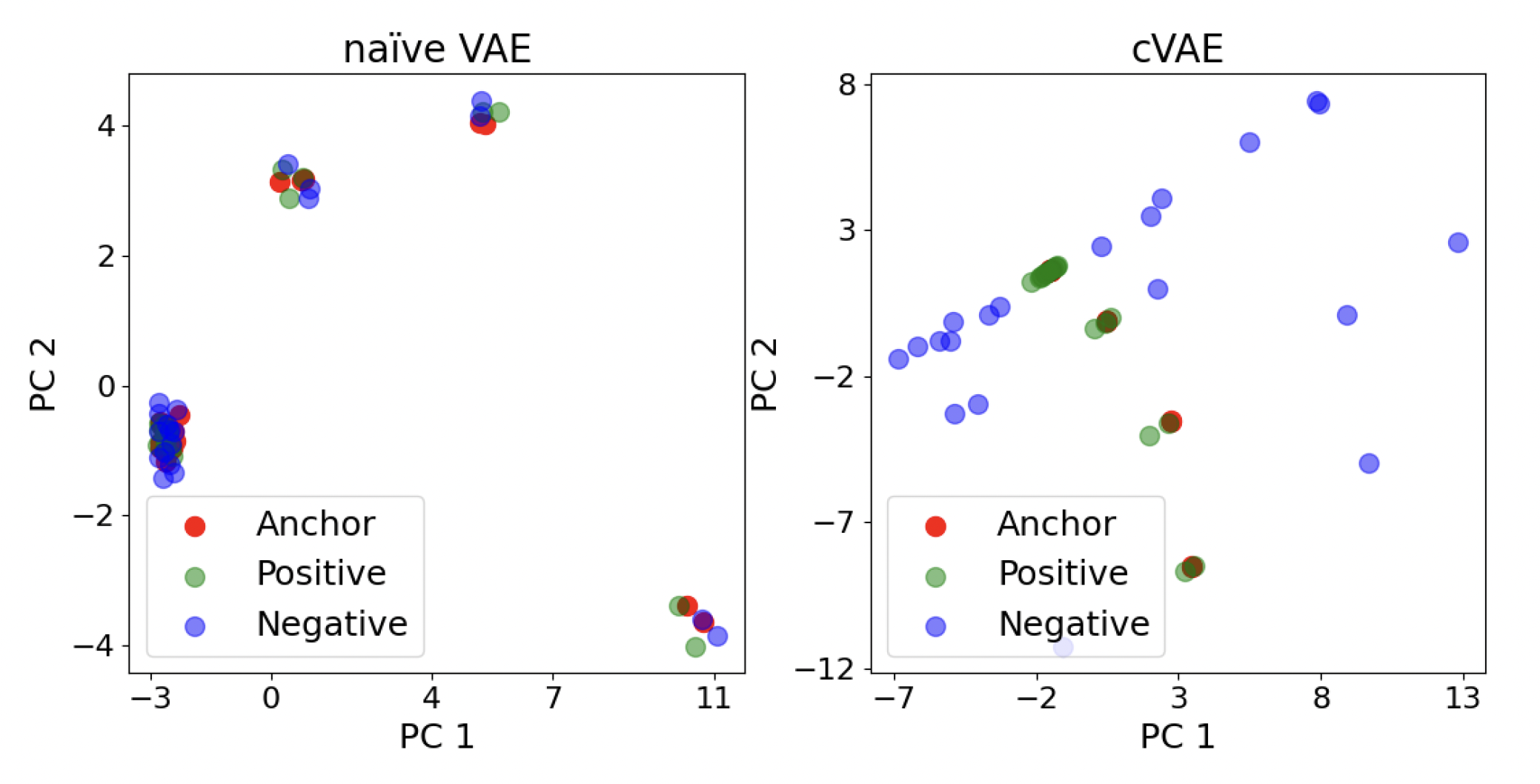
Positive한 Latent를 잘 구성해 놓았으니, 그것들로 조합한 결과물들은 좋을 것이라는 핵심 관점인 것 같다. 위의 분석 결과처럼, cVAE는 Anchor과 Positive case가 거의 붙어있고 Negative와는 멀리 떨어져있는 것을 볼 수 있다.
(그런데 plot의 눈금이 다르다. 주의)
아무튼 Text-to-HOI 분야에서 Sota를 찍었다고 주장하니, 나름의 효과가 있어 보인다.
결론 및 느낀점
- cVAE라는 방식이 원래부터 아예 없던 방식은 아니지만, HOI task에 필요한 방식으로 Latent space를 구분지어 구성한 것이 참신했다. 이 논문의 주인공은 cVAE가 아닐까 싶다.
- cVAE를 잘 구성했으니, Auto-Regressive Diffusion을 통해서 좋은 결과물을 뽑아 낼 수 있었던 것.
- 굉장히 단순한 MLP를 가지고 cVAE의 Encoder와 Decoder를 구성하였고, Diffusion process에서 Denoiser도 MLP로 구성하였다. 간단한 구조로도 좋은 결과물을 낼 수 있다는 점이 놀라웠고, 각 Layer간의 역할분배를 굉장히 잘 한 것 같다.
요약
This work demonstrates that, with a carefully designed contact-aware latent space, simple MLP-based VAEs and diffusion denoisers are sufficient for stable HOI generation, shifting complexity from network architecture to representation learning.
