과제- 실습 후 과정 및 결과물 제출
- DB설계
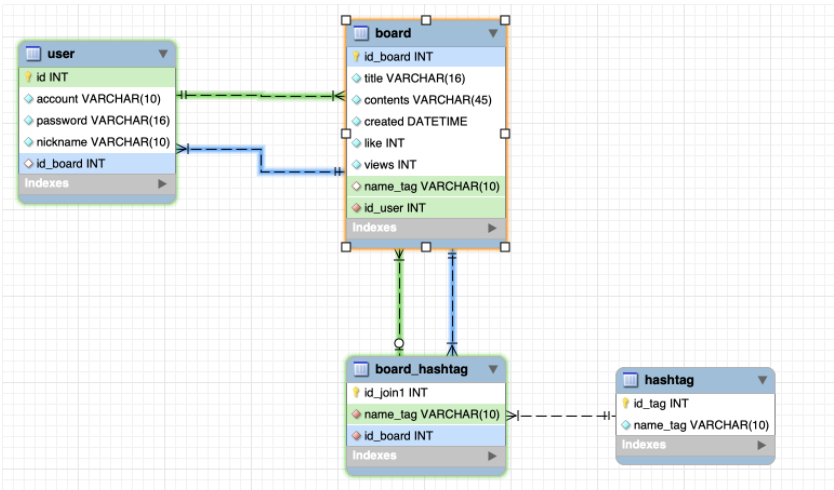
- 커뮤니티를 만든다고 가정했을 때, 필요한 테이블과 각각 관계 생성 (아래 테이블은 필수)
- 해시태그 테이블에는 해시태그의 정보만 담겨있다.
- 하나의 게시글은 여러개의 해시태그를 포함할 수 있다.
user(유저)board(게시글)hashtag(해시태그)
- MySQL 조사
MySQL에서의 CRUDFK 쓰는 이유, 반드시 써야 하는가?WHERE, IN 차이점여러가지 JoinTRUNCATE
- intelliJ 설치
1주차
과제- 실습 후 과정 및 결과물 제출
- DB설계
- 커뮤니티를 만든다고 가정했을 때, 필요한 테이블과 각각 관계 생성 (아래 테이블은 필수)
- 해시태그 테이블에는 해시태그의 정보만 담겨있다.
- 하나의 게시글은 여러개의 해시태그를 포함할 수 있다.
user(유저)board(게시글)hashtag(해시태그)
- MySQL 조사
MySQL에서의 CRUDFK 쓰는 이유, 반드시 써야 하는가?WHERE, IN 차이점여러가지 JoinTRUNCATE
- intelliJ 설치
커뮤니티 DB 만들기
-
database 생성
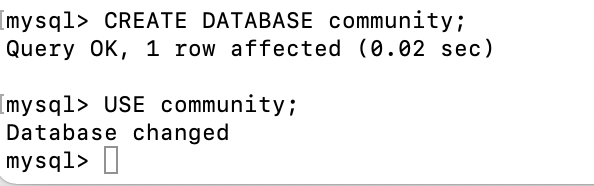
-
테이블 설계하기 - workbench 사용
user 테이블
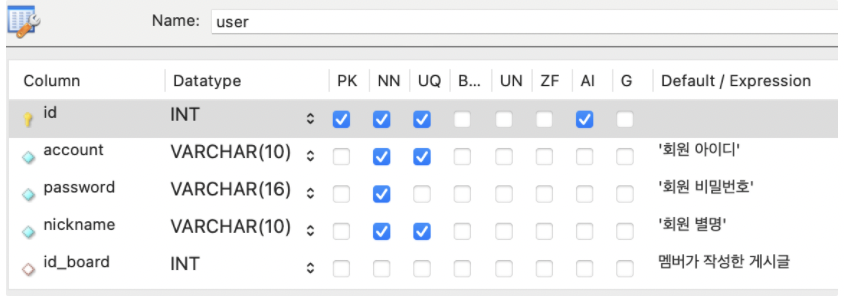
AI : auto increase
VARCHAR() 괄호 안의 숫자는 mySQL에서 문자 수를 의미하는 것이었다.
board 의 id_board를 기본키로 하는 외래키를 user 테이블에 넣었다.
작성자가 어떤 게시물들을 작성했는지 알 수 있다. 1:N 관계.
board 테이블
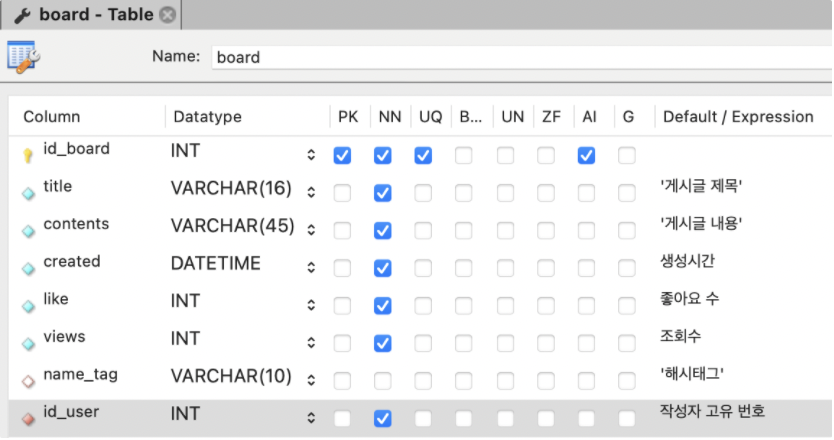
제목, 내용, 조회수와 좋아요 수를 표현할 수 있게끔 컬럼을 넣었다.
NN: not null
NN을 을 하면 저장공간이 절약된다고하여 되도록 대부분의 컬럼에 적용했다.
name_tag : 해시태그 이름을 참조하는 외래키 N:M의 관계
id_user : 작성자를 표시하기 위해 user테이블의 id를 참조하는 외래키. 1:N 의 관계.
hashtag 테이블
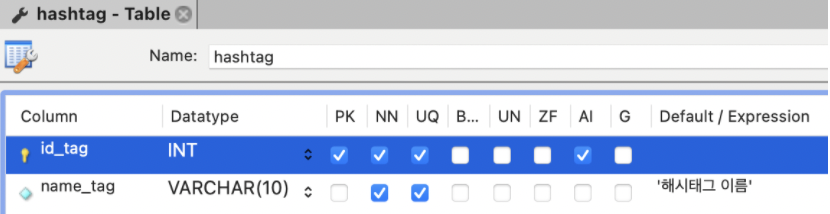
한개의 게시물에는 여러개의 해시태그가 포함 될 수 있고, 해시태그도 여러개의 게시물을 포함할 수 있어야 한다.
해시태그와 게시물 간의 관계는 N:M 이므로, 검색해본 결과 JOIN 테이블을 만들기로 하였다.참고자료 : https://hanamon.kr/관계형-데이터베이스-설계-관계-종류/
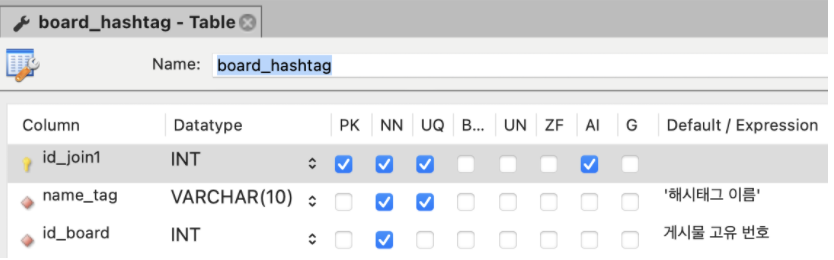
board_hashtag 테이블은 tag의 name과 board의 id를 참조하기 위해 만든 조인 테이블이다.
- 결과물
MySQL에서의 CRUD
C는 Create, R은 Read, U는 Update, D는 Delete의 약자이며, 네 가지 기능은 DB의 본질이다.
CREATE
CREATE DATABASE database_name;
USE database_name; # 데이터베이스 사용
CREATE TABLE table_name(
필드명 타입
필드명 타입
PRIMARY KEY(필드명)
); # 데이터 컬럼의 이름과 자료형을 입력하여 테이블을 생성INSERT INTO
# 생성한 데이터베이스에 레코드를 추가할 때 사용할 수 있음.
INSERT INTO table_name(field1, field2, field3)
VALUES(data1, data2, data3);
SELECT * FROM topic; # topic 테이블의 모든것(*)을 출력해줌SELECT
SELECT 속성1, 속성2, 속성3 FROM topic;
# topic 테이블에서 속성 1-3 만 선택해서 출력해줌
[WHERE | GROUP BY | ORDER BY]
SELECT field1,field2,field3 FROM topic WHERE field1='something';
#field1이 'something'인 레코드값들을 찾아서 field1-3 출력해줌
SELECT field1 FROM topic WHERE field1='something' ORDER BY DESC LIMIT 2;
#ORDER BY DESC, ASC로 내림차순, 오름차순 정렬가능
#LIMIT n 을 사용해서 검색되는 데이터가 너무 많을 때 제한을 걸 수 있다UPDATE
UPDATE 테이블 SET assignment_list # 혹은 속성1= 바꿀값 과 같이
[WHERE where_condition] # 어디에 수정을 할 것인지
value:
{expr | DEFAULT}
assignment:
col_name = value
assignment_list:
assignment [, assignment] ...DELETE
DELETE FROM 테이블이름
WHERE 조건
#레코드 한 줄 전체 말고, 속성1에 해당하는 값1개만 삭제할 수는 없을까?
#- NULL 값으로 만드는 것은 가능할 것 같다.FK 를 쓰는 이유. 반드시 써야하는가?
Foreign 키를 쓰면 다른 테이블의 기본키를 참조하기 때문에
다음과 같은 무결성 제약조건에 합적하기 때문에 정합성을 강제하고 싶을 때 사용한다고 한다.

하지만 쓰지 않아도 되다는 의견은 이렇다.
만약 데이터베이스가 너무 커서 용량정리의 목적으로 기본키가 포함된 A의 레코드를 지운다고 했을 때, 사라진 레코드를 참조하는 외래키는 존재할 수 없을 것이다. 그러나 외래키가 포함된 레코드가 없어지면 안될 경우가 존재하기 때문에 그냥 그때그때 관리를 한다는 것이다.
WHERE, IN
WHERE 은 SELECT 문에서 조건에 해당하는 값을 찾아내기 위해서 사용한다.
SELECT * FROM 테이블명
WHERE 컬럼명 IN (값1, 값2, 값3);
# IN은 WHERE절 내에서 여러개 특정값에 해당하는 레코드들을 선택한다.
# OR 연산자로 값을 하나 하나 연결해서 표현할 수도 있지만 길어진다.
# 다른 조건 연산자로 AND, OR, BETWEEN A AND B, IS NULL/NOT NULL, LIKE (%,_)
TRUNCATE
- TRUNCATE 명령어는 TABLE이나 CLUSTER에서 모든 행을 삭제하는 빠르고 효율적인 방법. 용량이 줄어들고 인덱스 등도 모두 제거한다. 저장공간을 반납한다.
- 삭제와 관련된 명령어로 DROP과 DELETE 가 있다.
- DELETE 명령어는 데이터는 지워지지만 테이블 용량은 줄어 들지 않고, 원하는 데이터만 지울 수 있다. 롤백 가능
- DROP은 아예 테이블 구조를 제거한다는 점에서 다르다.
DML, DDL , DCL
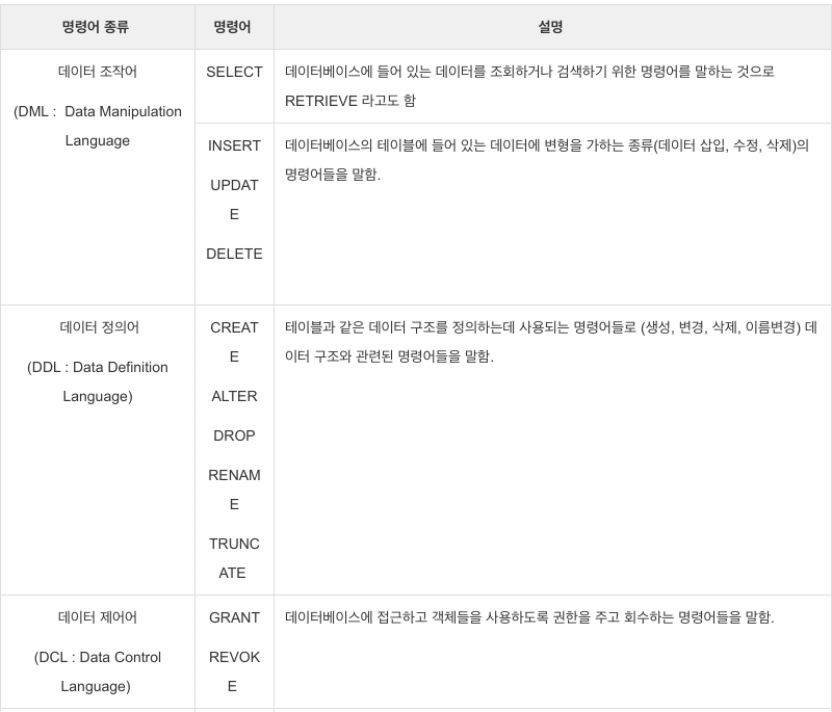
https://brownbears.tistory.com/180
TCL은 데이터베이스를 서버에 올리고 관리하는 과정에서 트랜잭선 별로 제어하는 명령어를 말한다고 한다.
COMMIT, ROLLBACK 등이 있다.
