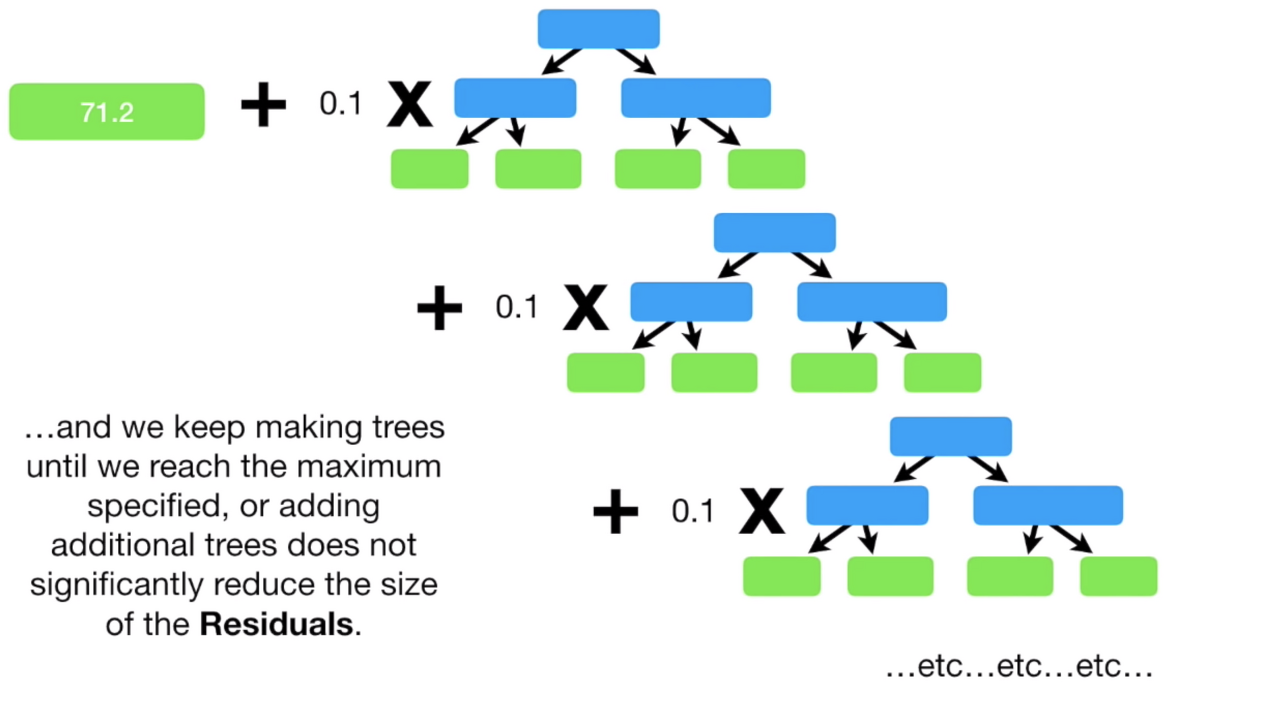
그라디언트 부스팅은 앙상블에 이전까지의 오차를 보정하도록 예측기를 순차적으로 추가합니다. 그리고 이전 예측기가 만든 residual error에 새로운 예측기를 학습시킵니다.
Gradient Boost 모델이 학습하는 원리를 파악한 뒤 정리해 보세요. 또한 여기서 말하는 residual error가 무엇인지 찾아보고, 서술하시길 바랍니다.
Gradient Boost는 학습하기 위해 stump나 tree가 아닌 하나의 single leaf부터 시작하며, 예측하는 target 추정 값은 모든 target 값의 평균으로 만들어 줍니다
- stump
-1. Adaboost모델이 학습할때 사용되며, tree와는 다르게 연속되는게 아닌 각 1개의 feature로 분류를 하며, 그렇기 때문에 weak learner(약한 학습)이라 합니다.
-2. 다만, tree처럼 feature간 동일한 가중치를 주지 않고 특정 stump에 가중치를 주며 학습합니다. 이를 Amount of Say가 높다고 표현합니다.
-3. 각 stump의 error(오차)는 다음 stump에 영향이 갑니다.
실제 target값과 평균값의 오차(error)를 residual(잔여)라고 하며, 학습을 위한 1번째 residual를 구해줍니다.
이후 학습하려는 data set의 columns인 feature값으로 tree형식을 만들어 줍니다.
이때 동일한 feature에 해당하는 value값(leaf node)은 평균으로 만들어 줍니다.
이후 해당하는 1번째 residual값(leaf node)에 learning rate 값을 곱해준 뒤 평균값을 더해준 것을 target값과의 오차를 구하면 이는 2번째 residual이 됩니다.
이를 반복하여 residual 0이 되도록, 즉 더 이상의 오차값이 나오지 않을 때까지 반복 학습합니다.
residual error
-1. error(오차)는 모집단에서 얻은 예측값과 실제값의 차이 이며, resudual(잔차)는 표본집단에서의 예측값과 실제값의 차이 입니다.
-2. 관찰된 값 그룹과 산술 평균 간의 차이를 말합니다.

ENTJ-A