Project_FIFA(feat. Pandas, MySQL)
데이터 전처리
데이터 전처리는 1차, 2차로 나눠서 진행했습니다.
1차는 데이터 수집 직후에 오타나 잘못 크롤링된 부분을 보다 직관적이게 확인 할 수 있도록 수정하였고, 2차는 db schema를 정의하고 각 TABLE 마다 수집된 데이터가 알맞게 적재 될 수 있도록 전처리 했습니다.
1차 전처리는 비교적 쉽고 간단하게 진행했지만, 2차 전처리부터 고뇌에 빠졌습니다.
우선 스키마 부터 정의해야 했기에 여러 회의끝에 아래와 같이 정의했고,
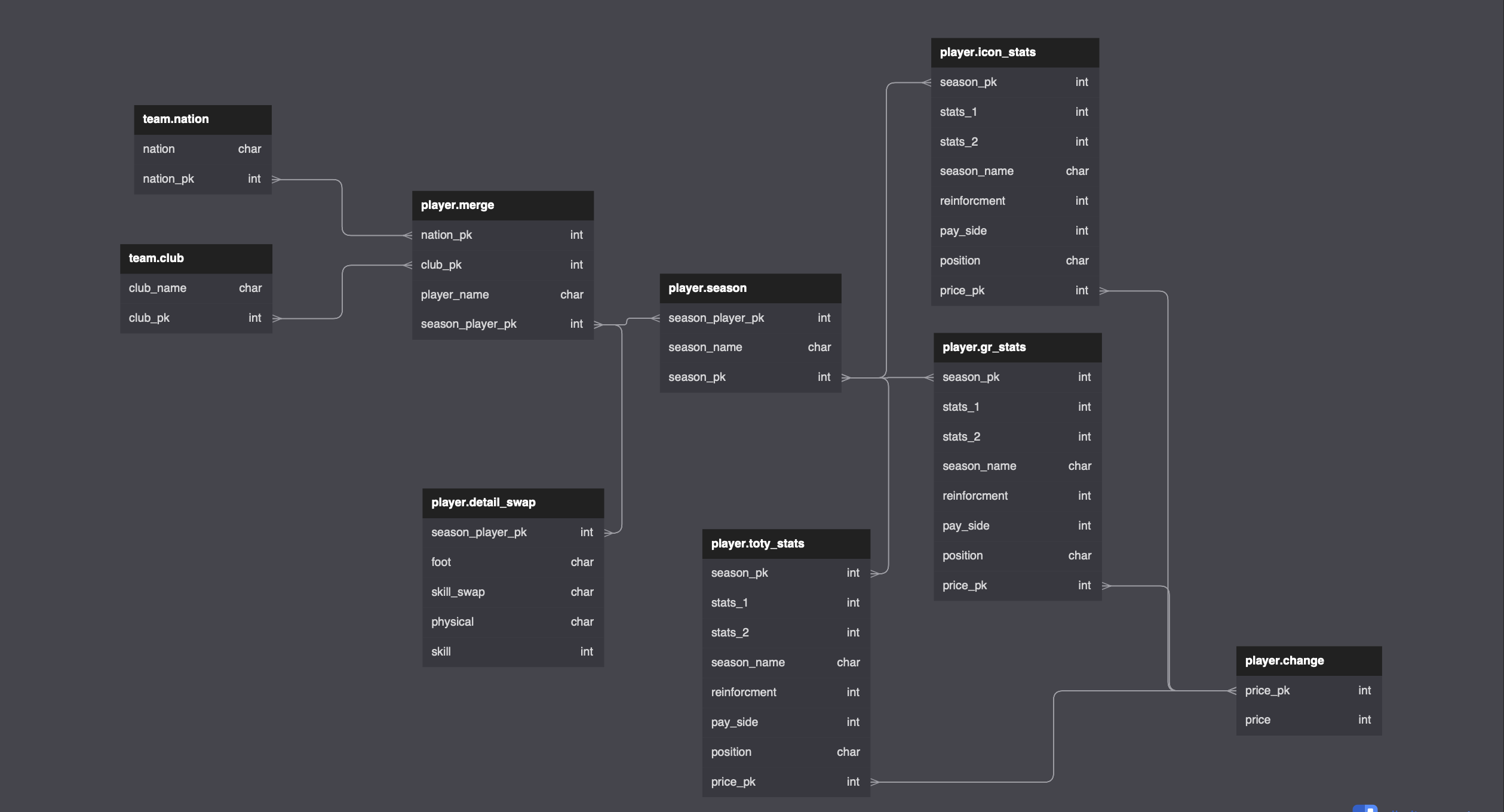
- db schema 할 수 있는 홈페이지를 팀원이 찾아서 좀 더 수월하게 작업했습니다.
[출처 : https://dbdiagram.io/d/6394229cbae3ed7c4545f0e0]
"생각했던 output값이 나오기 위해서 어떠한 input값을 넣어야 되는지", "input값을 기준으로 어떻게 Query를 짜야 output이 잘 나올까" 생각하며 만들었습니다.
위 스키마를 간단하게 설명드리면, 국가별 테이블/ 팀 테이블/ 추가 옵션 테이블/ 시즌별 스탯 테이블/ 가격 테이블 정도가 될 것 같습니다.
팀(국가)컬러 기준으로 특정 조건에 만족하는 시즌(선수)을 출력 해준다고 가정하였습니다.
여기서 가격 테이블을 따로 정의한 이유는 아무래도 본 게임에서는 가격이 일정 시간별로 업데이트(최신화)가 되기 때문에, 추후에 1일, 1업데이트 혹은 시간별로 업데이트를 할 예정으로 따로 테이블 화 하였습니다.
스키마를 마무리 짓고, 테이블에 맞춰서 데이터 프레임을 만들었으며, 생각나는 전처리는 예로 들어, 한 선수의 팀 커리어 개수가 5개라면, 팀 커리어 개수만큼 unique화 시켜 추후 테이블에서 pk값으로 사용할 수 있도록 전처리 해주었습니다.
데이터 적제
데이터를 전처리 해준 뒤 Cloud SQL(MySQL)에 터미널을 통해서 접속해준 뒤 DataBase와 Table을 생성하여 적제를 하는 와중 여러 난관에 부딪치게 되었습니다.
또한 pk값의 경우 int값에서 bigint로 변경하고, unsigned(양의 정수)까지 해주었습니다.
- INT형은 4바이트(32비트)의 정수이고, BIGINT형은 8바이트(64비트)의 정수이다. unsigned속성을 적용했을 때, INT형은 0부터 4,294,967,295(약 43억)까지, BIGINT형은 0부터 2의 64승-1(약 1844경)까지의 숫자를 저장할 수 있다.
id값이 음수일 경우는 없을 것이므로 unsigned속성을 적용한 예를 든 것인데, 음수가 필요한 다른 컬럼에 적용할 경우에는 쿼리문에 unsigned속성을 적지 않으면 된다. 이 경우에는 INT형은 -2,147,483,648(약 -21억)부터 +2,147,483,647(약 21억)까지, BIGINT형은 -2의 63승(약 -922경)부터 + 2의 63승-1(약 922경)까지 숫자를 저장할 수 있게 된다.
[출처: https://dogleg.co.kr/?p=163]
- 따옴표 터미널과 로컬 차이?
데이터를 적재하는 코드를 일일이 치기보다 간단하게 복붙하려고 했으나, 어느때는 잘 되었지만 어느때는 에러가 발생되었습니다. 이유는 따옴표(')가 터미널, mysql에서는 로컬 pc 따옴표와 생김새?가 달라 발생하는 이슈였습니다.
- 프라이머리 중복값 이슈
Primary key는 당연히 unique값이어야 합니다..
잘 알고 있으면서도 전처리에서 정의한 값을 기준으로 테이블을 생성하고 데이터를 적재할때면 실수가 가끔씩 나왔습니다.
이유는 개인이 아닌 팀으로 진행하다 보니 정의했던 것도 수정을 하며 변화되는 과정이 있어기 때문입니다.
수정된 스키마(schema)

- 페이저(pager)?
페이저는 위에 따옴표 이슈에서 발생되어 혼란(페이저 이슈로 착각했으나, 알고보니 따옴표 이슈)을 가져왔지만, 이내 확인해본 결과 출력 결과물이 많을경우, 어느정도 생략된 뒤에 결과물을 보여주지만 페이지 모드로 지정 설정(pager more -d) 할 경우, 전체 결과물을 확인 할 수 있다.
디폴트는 nopager로 가능하다.
느낀점
우선 데이터를 수집한 뒤에 pandas DataFrame으로 작업할 수 있었지만, 굳이 Cloud SQL(MySQL) 까지 써가며 프로젝트를 진행 한 이유는 꼭 한번 DataBase에 적재 및 저장, 추출 쿼리를 해보고 싶었기 때문입니다.
따라서 데이터 수집하는 시간동안 틈틈이 공부를 하면서 프로젝트까지 적용했습니다.
또한 프로젝트 회의를 통해 팀원과 여러 방법중 ElasticSearch가 나왔지만, 기존에 진행하기로 했던 MySQL(RDBMS)에 적재를 우선으로 진행해본 뒤, 비교를 해보고 후에 변경을 염두해 두기로 했습니다.
기존 mysql에서 ElasticSearch를 염두한 이유는 아무래도 RDBM특성상 적제된 데이터의 수정이 적어야 되지만, 피파온라인의 선수 가격은 일정 시간동안 수시로 변경되고, 일정 주기로 신규 시즌카드가 업데이트 되는 이유와 RDB 쿼리 보다는 검색엔진이 좀더 맞지 않을까 하는 생각이었기 때문입니다.
그리고 데이터 베이스를 정의하고 만드는게 말처럼 쉽지 않고 정말... 어려운 것이라고 느꼈습니다.
이유는 혹여라도 pk, fk 를 잘 못 정의할 경우 되돌릴 수 없는 참사가 벌어질 수도 있기 때문입니다..
현재 스키마를 수없이 수정하고 테이블을 지웠다 다시 만들기를 반복, 데이터를 적재하는 작업에서 새해가 밝아오며 Cloud SQL server가 닫히고, 앞으로 있을 La piscine으로 아쉽지만 중단하기로 했습니다..ㅜ
