SVM은 입력 데이터 Feature scaling이 매우 중요합니다. 그 이유에 무엇인지 서술하고, 이에 더해 SVM 커널 함수가 어떤 역할을 하는지 적어주세요.
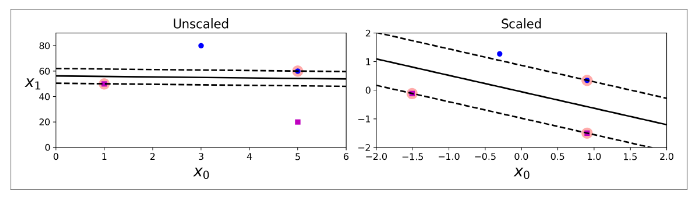
feature scaling을 하는 이유는 예를 들어 각 feature값이 사람의 나이와 연봉, 2개만 있다고 가정할 경우 나이는 보통 1~100 사이의 값을 형성하고 연봉은 2,000~20,000의 값을 형성한다고 할 때, 단위 scale의 차이로 높은 값을 가지고 있는 연봉 feature에 weight값을 높이는, 즉 편향된 잘못된 학습이 될 수 있기 때문입니다.
SVM으로 학습하고자 하는 data set의 feature값이 위와 동일하게 2개인 경우로 예를 들어 feature space가 x, y값으로 이뤄진 2차원일 때 scaling이 되지 않을 경우 각 value값들의 범위가 달라 large margin classification을 하기 어려워 지기 때문이기도 합니다.
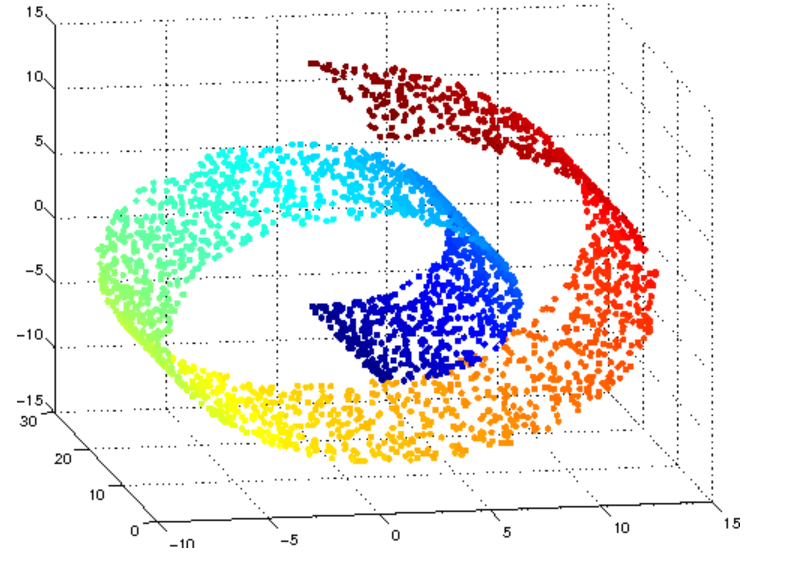
추가적으로 위와 동일한 data set으로 가정하여, 2차원 feature space가 non-linear 한 값 들일 경우 이를 classification 하기 위해서는 Polynomial(다항식)을 활용하여 2차원 상태에서 1차원을 높여 3차원으로 변형한 뒤 분류할 수 있도록 해주는 hyper parameter인 ploy를 활용해야 합니다.
이 외에도 방사 기저 함수 (RBF: Radial Bias Function) or gaussian kernel이 있으며 이는 poly처럼 1차원을 높인다는 개념보다는 2차원의 점을 무한한 차원의 점으로 변환합니다.
