1주차 정리(1) Improving Deep Neural Networks: Hyperparameter Tuning, Regularization and optimization
ML_Basic
본 정리는 구글 부트캠프 specialization 2번째 1주차 1 번째 정리입니다.
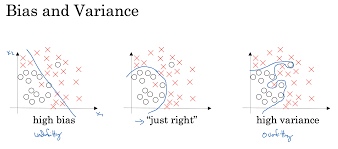
1. bias and variance
- high variance와 high bias가 나타나는 경우
High bias = 정확도가 떨어지기에 단조로운 형태의 경우 갖게 되는 특징
High variance = input에 대한 각각의 상황을 고려한 섬세한 형태의 경우 갖게 되는 특징
아래 자료를 통해서 variance와 bias는 error 수치를 바탕으로 추론할 수 있습니다.
Error4 같은 경우는 train set과 dev set 모두 error가 낮기에 low variance, low bias 상태입니다.
| Error1 | Error2 | Error3 | Error4 | |
|---|---|---|---|---|
| train set | 1% | 15% | 15% | 0.5% |
| test (Dev) set | 11% | 16% | 30% | 1% |
| high variance | Yes | No | Yes | No |
| high bias | No | Yes | Yes | No |
2. High variance, Low variance and regularization
- high variance와 high bias를 해결할 수 있는 방법
high bias 인 경우
- Generate bigger network
모델을 더 깊게 만들어준다면 기존 모델보다 더 많은 feature를 추출해서 오차를 줄여간다.
In modern deeplearning era, getting bigger network reduce bias(just bias and no touch of other things.)- Train for longer time
학습 시간을 늘린다면 오차를 더 줄여갈 수 있다 (local optima에 빠질 수 있다.)high variance 인 경우
- Collect more data
현실적인 한계가 분명한 방식이다. (expensive하고 additional action required)- Find more appropriate nn network
항상 잘 되는 방법은 아니라고 소개된다.- Regularization 🔥🔥🔥🔥
- L2 regularization
정규화 방식 중 neural network에 소개된 cost function에 regularization을 적용한 결과만 우선 정리하려고 한다. 이 정규화에서는 기존 cost function에 모델의 복잡도도 최소화하고자 추가했다. 아래 식은 (L2)frobenius norm이라고 불리는데 이와 관련된 증명은 추후 mml 공부 후에 포스팅할 예정이다. 간단하게 정리하자면 모델의 복잡도라고 생각할 수 있다.
Cost function 에 추가된 람다는 regularization hyparameter라고 한다.
이 람다는 weight decay의 속도를 조절하기 위한 용도다.
방금 언급한 cost function 은 back propagation을 하려고 하면 regularization 부분도 고려해서 진행해야 한다.
기존 back propagation 에서 forbenius norm을 편미분한 부분도 적용하는 차이점을 볼 수 있다.왜 Regularization은 high variance를 해결할 수 있는걸까?
람다 를 크게 잡으면 weight decay 과정에서 해당 layer의 의 값을 0으로 수렴하게 할 수 있다. 사실상 nn network가 간단해지면서 high bias를 불러일으킬 수 있다.
강의를 통해 알게 된 것은 값이 0이 되면서 노드와의 연결이 아예 끊기는 것은 아니지만, 아주 작은 영향을 끼치기에 overfitting을 해결할 수 있다는 것이었다.
2. Dropout regularization
: Eliminating some node with probability(randomly)
각 layer마다 특정 probability를 기준으로 무작위로 선점된 노드들을 제외한 나머지를 사용한다.#if current layer is k keep_prob = 0.7 # dropout의 비율로 0.3을 없앤다. dk = np.random.rand(ak.shape[0], ak.shape[1]) dk = (dk<keep_prob).astype(int) ak = np.multiply(ak, dk) # 사용하려는 노드를 선별 ak /= keepprob위 코드는 특정 layer에서 dropout을 진행할 때 노드를 선별할 때 사용하는 과정이다.
맨 아래 코드를 이해하기 어려웠는데, 가령 X 라는 변수를 원래 사용하려고 했고 실제로 X 라는 변수를 사용한다고 가정해보자. 그 중, keep_prob X만 선별하고 사용하려고 한다. 이때 scale 작업을 진행해줘야 실제로 test할때 문제가 발생하지 않는다. keep_probX 만큼 쓰려고 하는 과정에서 (keep_prob*X) / keep_prob를 거친다면 원래 쓰이는 크기만큼인 X가 학습에 사용되기에 다음 layer에서 이전 layer의 shape 문제도 안 발생하는 것이다.
3. Early stopping
: 만약 training 과정에서 overfitting을 방지하기 위해 사용된 방식이다. 하지만 early stopping 방식은 orthogonalization을 지키지 못하기에 사용하는 것을 자제해야한다.
+ orthgonalization
: cost function 를 최소화하는 과정과 overfitting 방지 과정은 서로 절차적으로 진행되어야 한다. (동시에 진행하면 최적의 해답을 찾지 못할 가능성이 크기 때문이다.) 보통 cost function을 최소화를 진행하고 이후에 overfitting 방지 과정을 수행한다고 이해했다.
4. Data Augmentation
: 기존에 가지고 있는 데이터를 활용하여 데이터의 규칙적인 변형을 통해 데이터셋의 크기를 늘리는 방식
+과제 중 헷갈렸던 내용np.random.randn(M) # M개를 mean = 0, var = 1 조건에서 추출 np.random.rand(M) # M개를 0~1 사이에서 추출
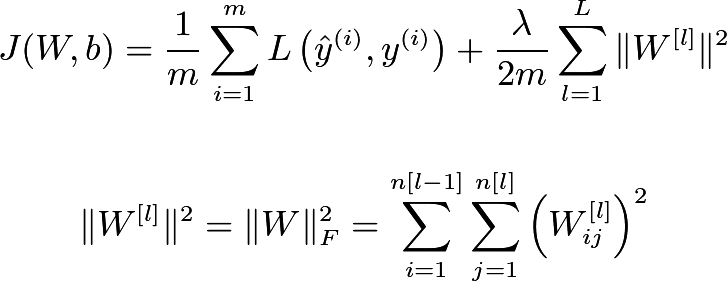
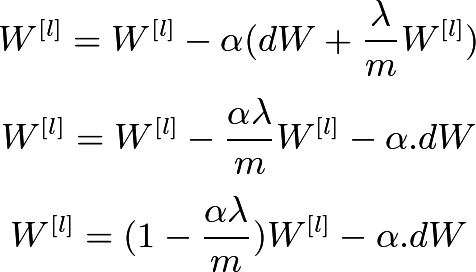

다음 포스팅은 빠르게 학습할 수 있는 방법과 gradient checking에 대해 정리할 예정입니다.
