Error Analysis
실제 모델의 dev set에 대한 error를 진행했을때, 각 error reason 마다 비율을 수치로 환산하여 무엇을 진행해야할지 방향을 결정할 수 있는 지표다.
실제로 dataset이 mislabel되었다면, 만약 random error (의도적이 아닌 오류)가 아닌 systematic error (의도적 오류)인 경우, 이는 해결해야하는 문제다. DL은 random error에 대해서는 robust하지만(취약하지 않고 직관적이다), systematic error는 학습에 방해를 한다.
dev set에 대한 변화를 줬다면, test set에 대해서도 동일한 작업을 진행해야 한다.
그리고 모델의 알고리즘에서 틀린 데이터셋을 뽑아서 살펴본다(이 과정은 필수가 아니다.)
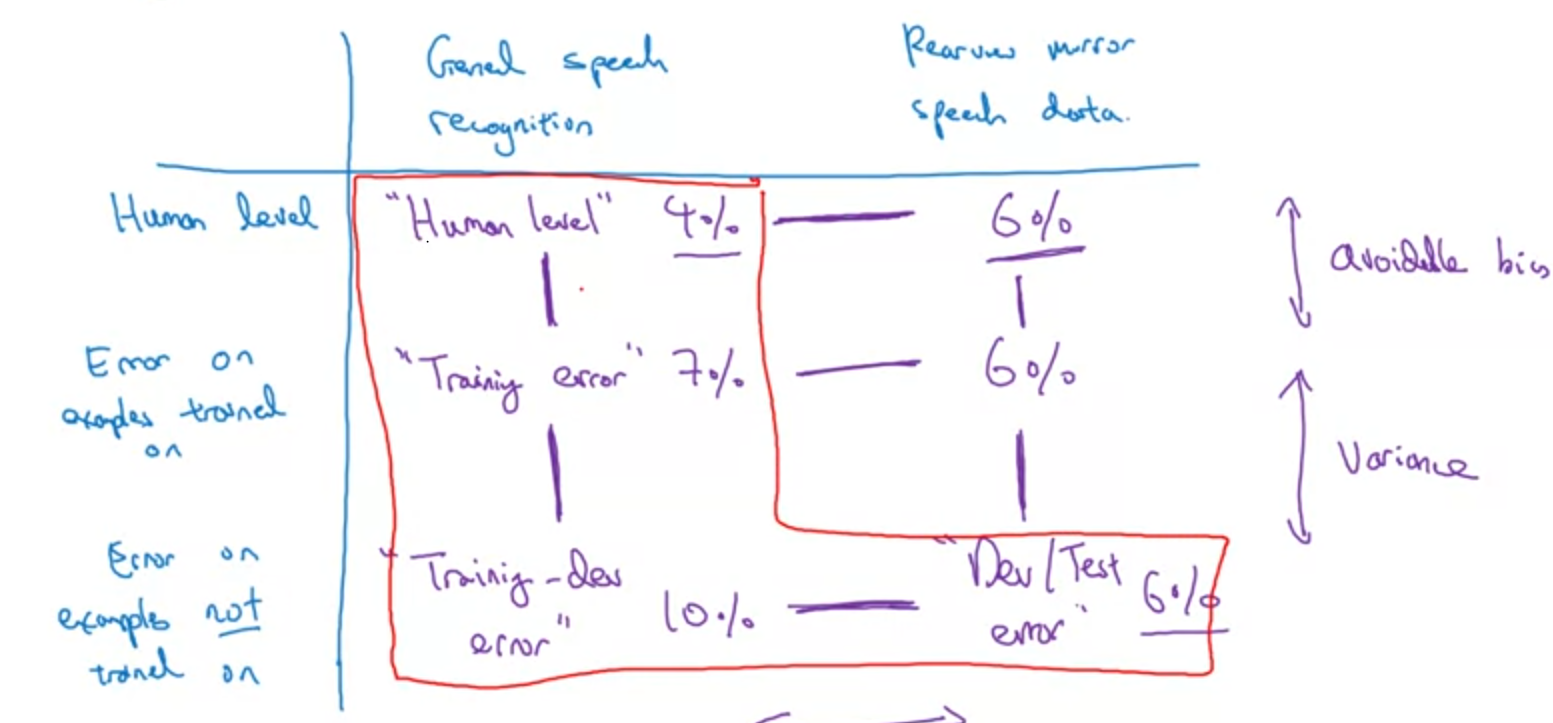
training set과 dev&test set
dev set와 test set는 모두 같은 distribution에서 뽑아야한다. 그런데 아예 다른 distribution이라면 이 3개의 dataset에 변화를 줘야한다.
1번 방법
training set에 dev와 test set의 일부를 넣고 기존 dev, test set에서 빼고 진행한다. 이 방법은 variance를 측정하는데 있어 데이터셋 분포가 낮다는 문제가 있다.
2번 방법
training set 중 일부를 떼서 training-dev set을 만들어서 이 training-dev set으로 variance를 측정하고, 기존 dev set은 dataset mismatch의 정도를 측정한다. test set은 dev set과의 overfitting을 측정하기 때문에 이전과 달라진 역할이 없다.
mismatch가 너무 크면 해결할 수 있는 과정
1. error analysis를 통해서 dev set과 training set의 차이를 본다.
2. training set에 dev set과 비슷한 데이터셋을 추가해준다. 이때, artificial data synthesis를 사용하여 추가할 수 있다.
Artificial data synthesis 는 합성하려는 2개 데이터의 분포에 따라 한 데이터에 대한 overfitting이 일어날 수 있다.
end-to-end learning
end-to-end learning이란 입력에서 출력까지 파이프라인 네트워크 없이 한 개의 dataflow로 학습하는 방식이다.
이때, data preprocess 과정을 만들어 과정에 input output을 여러번 만들어서 진행하는 것과 다른 방식이라고 볼 수 있다.
장점
1. 데이터를 라벨링할 필요가 없으니, 모델 하나로 학습할 수 있다.
2. 직접 파이프라인을 설계할 필요가 줄어든다. 하나의 dataflow만 있기 때문이다.
단점
1. 매우 큰 용량의 데이터셋이 필요하다(엄청 강조하셨다.)
2. 잠재적으로 좋은 효과를 만들어낼 수동적인 설계를 사용할 수 없다.
tmi
지난번 인턴때 만든 ai 서비스의 학습 데이터셋이 test & dev set과 training set의 괴리가 크다는 것을 인지해, training set의 데이터를 preprocess를 진행하고 end-to-end가 가능한지 생각해본 적이 있었다.
확실히 그렇게 큰 데이터셋이 아니라고 판단되고 feature들을 다른 input으로 넣고 진행할 수 밖에 없다고 판단되어 2개의 dataflow로 나눠서 진행했었다. 이후에 더 큰 서비스나 다른 프로젝트를 할 때, 한 번 end-to-end를 다시 진행해보고 싶다
