
일전에 CompletableFuture와 Spring @Async 어노테이션 활용해서 비동기 메서드 로직을 구현했다.
그때 @Async 같은 경우는 멀티 스레드풀을 직접 형성해서 구현했고 CompletableFuture는 별도의 스레드 풀에서 구현됐다. 해당 부분은 ForkJoinPool 스레드풀에서 직접 구현을 하는데 이는 자바에서 직접 제공해주는 프레임워크이다.
CompletableFuture는 내부적으로 ForkJoinPool을 사용하여 비동기 작업의 완료 여부를 추적하고 작업 간의 의존성을 관리했다.
이에 대해 알아보자.
Fork Join Pool 프레임워크
CPU의 속도는 발전에 발전을 거듭해 더 이상 기술적 성장보다 다른 부분에 대한 변화를 통해 성장을 고려해야 되는 시점에 왔다. 그래서 이제 개발자들은 코어의 개수를 늘리는 방식으로 CPU 리소스를 향상시키도록 한다.
쉽지 않은 멀티스레드 프로그래밍을 구현하도록 Fork & Join 프레임워크가 jdk1.7부터 추가돼 하나의 작업을 작은 단위로 나눠 구현하도록 도와준다.
이는 Java Concurrency 툴이고, 동일한 작업을 여러 Sub Task로 분리(Fork)해 각각 처리하고, 이를 최종적으로 합쳐서(Join) 결과를 만들어내는 방식이다.
ForkJoinPool 클래스는 ExecutorService를 구현하고, 작업 스레드 풀 관리, 분할, 종합하는 기능을 한다. ForkJoinTask 클래스는 ForkJoinPool에서 실행되는 작업을 나타내는 추상 클래스이다.
이 개념을 사용하려면 RecursiveAction (반환값 없는 작업) 과 RecursiveTask (반환값 있는 작업) 두 클래스 중 하나를 상속받아야 한다.
둘 모두 ForkJoinPool을 상속했기 때문에 compute() 라는 추상 메서드를 갖고 있고, 이를 사용하고자 한다면 상속받아 구현하면 된다.
public abstract class RecursiveAction extends ForkJoinTask<Void> {
protected abstract void compute();
}
public abstract class RecursiveTask<V> extends ForkJoinTask<V> {
protected abstract V compute();
}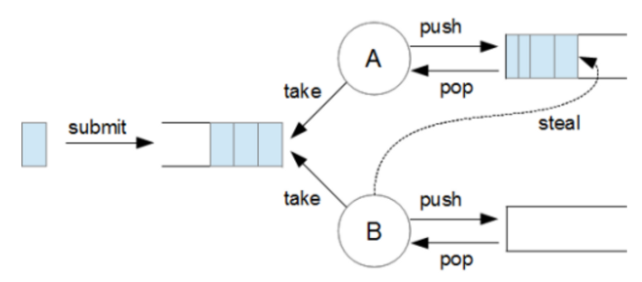
즉, 작업을 받으면 compute 메서드를 호출해 작업의 범위를 나눈다. 그래서 한 쪽에는 fork 메서드로 작업 큐에 넣는 작업이 진행되고 다른 한 쪽에선 compute 메서드가 다시 호출돼 작업의 범위를 나눈다. 나중에 결과가 나오면 join 메서드로 작업을 정리해 결과를 리턴한다.
이때 놀고 있는 큐는 다른 자식 스레드에서 일을 뺏어가(work stealing) 자신의 큐(inbound queue)에서 직접 처리한다... 이 과정은 스레드풀에 의해 모두 자동적으로 이뤄진다. 한 스레드에 작업이 몰리지 않도록 구현된 것.
이때 fork 메서드는 비동기, join은 동기 메서드이다.
하지만 멀티스레딩이 꼭 더 빠른 속도를 제공하는가? 그건 아니다. for문이 더 빠를 수도 있다.
그렇다면 언제 사용하면 좋을까?
Fork Join Pool는 기본적으로 받은 작업을 나누고, 일하며 노는 스레드에게 분배해주고, 다시 결과를 합치는데 드는 리소스가 만만치 않다. 그렇기 때문에 단순 for문이 빛을 발하는 경우가 생긴다.
ForkJoinPool의 최대 장점은 노는 스레드가 다른 부하 걸린 스레드의 일을 파악해서 직접 일을 가져간다는 점이다.
작업당 처리 속도가 크게 차이나는 작업이 있다면, 스레드 마다 작업을 분배해 줄 수 있는 대규모 작업 때 ForkJoinPool 기반을 사용해 작업을 분할하고 병렬적으로 실행시키면 좋겠다.
또한 재귀적인 작업 처리에서도 효율적으로 일처리가 가능하다.
🧷 참고 교재
[도우출판]Java의 정석 3rd Edition, - 남궁성
