0. Abstract
- Factorization Machine(FM)은 SVM과 Factorization Models의 장점을 합친 모델
- Factorization Model의 예시 : Matrix Factorization, Parallel factor analysis, specialized model (SVD++, PITF or FPMC)
- SVM과 같이 모든 실제 값의 특징 벡터로 작동하는 모델
- SVM과는 다르게 factorized parameters를 사용하여 변수 간의 상호작용 모델링 → sparsity 높은 모델의 상호작용도 추정 가능
- Real valued Feature Vector를 활용한 General Predictor
- Factorization Machine의 식은 linear time → 계산 복잡도가 linear complexity (factorization vector 등을 사용하여 complexity 줄임)
- 일반적인 추천 시스템은 special input data, optimization algorithm등이 필요 (정형화된 input)
- 반면, Factorization Machine은 쉽게 적용 가능
1. Introduction
- SVM
- 머신러닝, 데이터 마이닝에서 가장 널리 사용되는 예측 모델 중 하나
- collaborative filtering에서는 중요하게 역할 하지 못함
- 이러한 작업에서 매우 sparse data에서 complex kernel space에서 신뢰할 수 있는 파라미터를 학습할 수 없기 때문에 좋은 성능 못냄
- Cannot learn reliable parameters (hyperplanes) in complex (non-linear) kernel spaces
- tensor factorized model, specialized factorization models의 단점
- 표준 예측 데이터에 적용 불가
- 일반적으로 학습 알고리즘의 모델링 및 설계에 노력이 필요한 특정 작업에 대해 개별적으로 도출됨
- Factorization Machine은 general predictor이며, high sparsity에서도 reliable parameters를 예측할 수 있다.
- FM은 복잡한 interaction도 모델링하고, factorized parametrization를 사용
- Linear Complexity이며, linear number of parameters (성능 좋고 스피드 빠르다)
- 예측을 위한 파라미터를 저장할 필요없이 모델 파라미터를 직접 최적화, 저장 가능
1-1. Contributions
- Factorization Machine은 아래와 같은 장점이 있다.
- Sparse data (SVM은 실패)
- Linear Complexity
- 모든 실제 값의 특징 벡터에서 작동 가능한 General Predictor
2. Prediction Under Sparsity
-
대부분의 prediction task에서는 실수값을 가지는 feature vector x로부터 목표변수 T=R인 함수 y를 예측
-
데이터 셋 가 있다고 가정
-
이 논문에서는 x가 매우 sparse한 문제(vector x의 거의 모든 원소 가 0인 문제)를 다룸
-
큰 categorical variable 도메인을 다루기 때문에 huge sparsity가 생김
-
일반적으로 볼 수 있는 영화 평점 데이터의 예시

- Matrix Factorization은 user와 movie, 그리고 해당 rating만 사용
- Factorization Machine은 더 다양한 정보들을 사용 가능
-
transaction에서 생성된 특징 벡터 x 예제

-
FM은 SVM과 같은 general predictor이므로 모든 실제 값 특징 벡터에 적용 가능, 추천시스템에 국한되지 않음
3. Factorization Machines (FM)
3-1. Factorization Machine Model
3-1-1. Model Equation
- : global bias, : i번째 weight 모델링,
- : size k의 두 벡터 내적
- → 추정해야할 파라미터
- 2-way FM (degree=2) : 개별 변수 또는 변수 간 interaction 모두 모델링한다.
- 다항 회귀와 매우 흡사하지만, coefficient 대신 파라미터마다 embedding vector를 만들어서 내적

3-1-2. Expressiveness
- 어떠한 양의 행렬 W에 대해 과 같은 행렬 V가 존재
- k가 충분히 클 때, FM은 모든 행렬 W를 표현 가능
- but sparse한 환경에서는 복잡한 interaction matrix W를 추정한 데이터가 충분하지 않기 때문에 일반적으로 작은 k를 선택해야함
- k 제한 → FM 표현력 ↑ → sparse할 때 interaction matrix 더 잘 일반화 가능
3-1-3. Parameter Estimation Under Sparsity
- sparse할 때는 변수간의 interaction을 추정하기 어려움
- Factorization machine은 상호작용 매개변수를 factorize하여 독립성을 깨뜨리기 때문에 이러한 환경에서도 상호작용 잘 추정 가능
- 하나의 interaction에 대한 데이터가 관련 interaction의 매개변수를 추정하는데도 도움을 줌
3-1-4. Computation

- Factorization of pairwise interaction
- model complexity : O(→O(kn)
- 2개 변수에 직접적으로 연관 있는 model parameter가 없다.
- Pairwise interaction식을 정리하면 다음과 같음
3-2. Factorization Machines as Predictors
- 다양한 예측 작업에 사용 가능
- 회귀(regression) : 를 ㅈpredictor로 직접 사용, 최적화 기준은 minimal least square error
- 이진 분류 (binary classification) : 의 부호 사용, hinge loss 또는 logit loss에 최적화
- 순위화(ranking) : x는 의 점수에 따라 정렬, 최적화는 pairwise classification loss가 있는 인스턴스 벡터 쌍에 대해 수행
3-3 Learning Factorization Machines
- 모델 파라미터는 SGD와 같은 경사하강법에 의해서 효과적인 학습 가능
- 모든 파라미터 업데이트는 sparse할 때 O(kn) or O(km(x))로 수행 가능
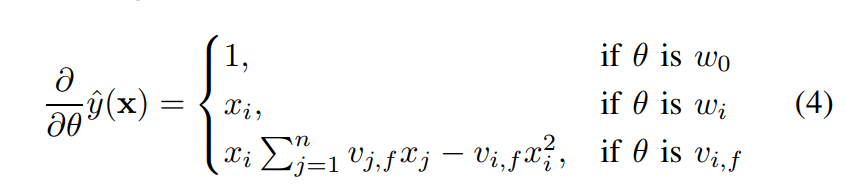
3-4. d-way Factorization Machine
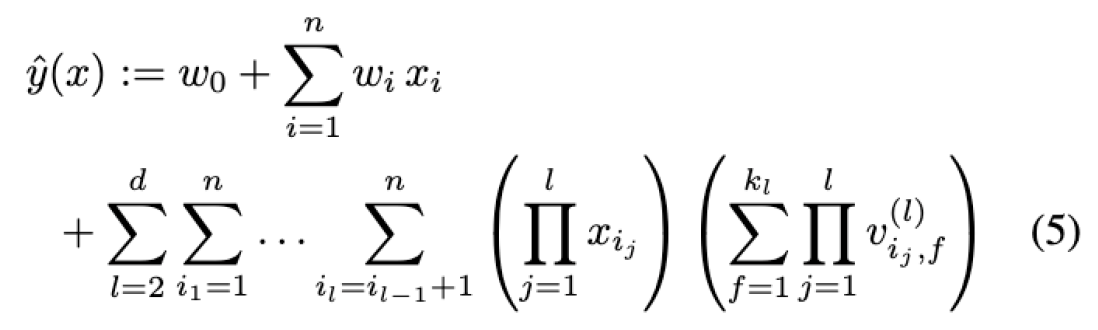
- 2-way FM을 d-way FM으로 일반화할 수 있다.
- 마찬가지로 computation cost는 linear
- http://www.libfm.org 다양하게 활용할 수 있는 module 공개
3-5. Summary
- FM은 전체 parameter화된 상호작용 대신 factorized된 interaction을 사용하여 feature vector x 값 간 가능한 모든 interaction 모델링
- 이렇게 할 때 의 2가지 이점
- 높은 sparsity에서도 값 간의 interaction 추정 가능. 일반적으로 관찰되지 않는 interaction으로 전환
- parameter의 수와 시간은 선형적 → SGD 사용하여 직접 최적화 가능, 다양한 손실함수 사용 가능
4. FMs vs SVMs
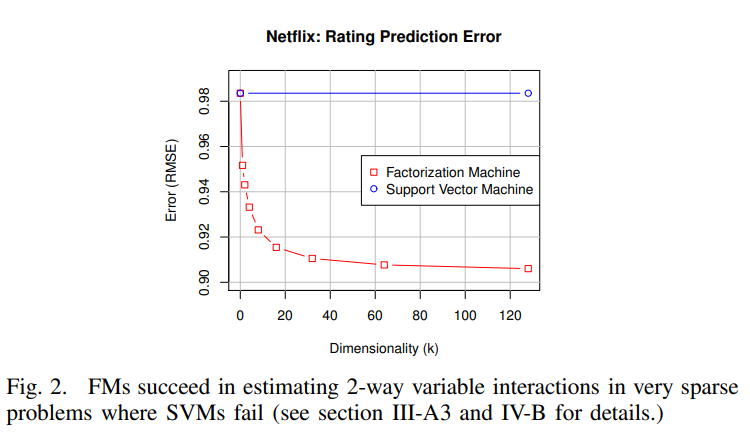
- SVM의 dense parameter화를 위해 직접적인 interaction에 대한 관찰은 종종 관찰되지 않음
- FM은 primal에서 직접 학습 가능. 비선형 SVM은 일반적으로 dual에서 학습함
- FM의 모델 방정식은 학습 데이터와 무관. SVM은 학습 데이터의 일부에 따라 달라짐
5. FMs vs other Factorization Models
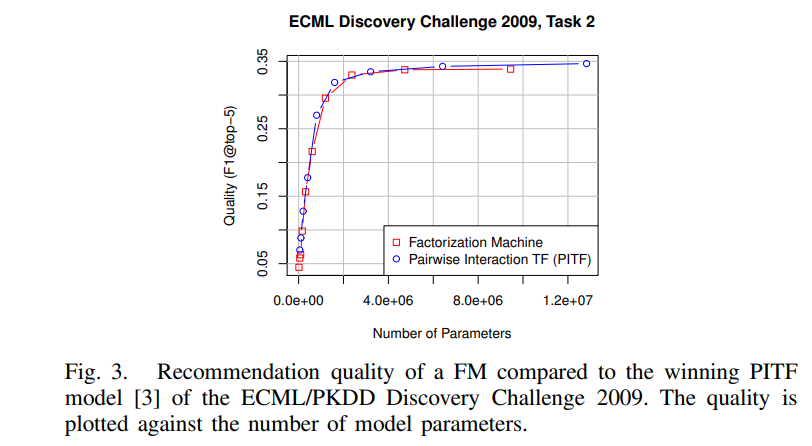
- PARAFAC 또는 MF와 같은 표준 factorization model은 FM과 같은 일반적인 예측 모델 x, 특징 벡터를 m개의 부분으로 분할하고 각 부분에서 정확히 하나의 요소는 1이고 나머지는 0이어야함
- factorization model이 특징 추출만으로 가장 성공적인 인수분해 모델(MF, PARAFAC, SVD++, PITF, FPMC 등)을 모방할 수 있다는 것을 보여줌
6. Conclusions and Future work
- Factorized Interaction을 사용하여 feature vector x의 모든 가능한 interaction을 모델링
- FM은 SVM의 generality와 factorization models의 장점을 결합한 것
- (High) sparse한 상황에서 interaction을 추정할 수 있다. Unobserved Interaction에 대해서도 일반화할 수 있다.
- 파라미터 수, 학습과 예측 시간 모두 linear (Linear Complexity)
- 이는 SGD를 활용한 최적화를 진행할 수 있고 다양한 Loss Function을 사용할 수 있다.
- SVM, matrix, tensor and specialized factorization model 보다 더 나은 성능을 증명

we_need_to_talk_about_ds