Self-Supervised Contrastive Pre-Training for Time Series via Time-Frequency Consistency 요약
2023 논문 세미나
Abstract
시계열에 대한 pre-training은 타겟 도메인과의 미스매치 문제점이 있다. 이는 일시적인 다이나믹스, 빠르게 변화하는 트랜드, 짧은 사이클 등의 문제로 나쁜 다운스트림 퍼포먼스를 보인다. 도메인 적용이 이러한 움직임을 경감하지만, 대부분의 케이스에서 타겟 도메인의 예시를 가져와야 한다는 점에서 pre-training 에서의 비효율을 야기한다. 따라서, 타겟 도메인을 적용할 때 일시적인 다이나믹스를 고려하여 pre-training 과정에서 타겟 예시를 보지 않고도 로버스트 해야 한다. 시간 기반,및 주파수 기반의 representations는 시간-주파수 도메인에서 근처에 위치해 있을 것이다. 결국 시간-주파수 consistency(TF-C)를 사용하는 것이 pre-training 과정에서 합리적이다. 이는 시간 기반의 이웃과 가까운 주파수 기반의 이웃을 임베딩한다. TF-C에 의해 decomposable pre-training 모델을 만들었고, self-supervised signal 이 시간과 주파수 컴포넌트 사이에서 제공되었다. 각각은 contrastive estimation을 통해 개별적으로 학습되었다. 이러한 새로운 방법을 8개의 데이터셋으로 평가하였다. TF-C 가 8개의 SOTA 방법보다 더 높은 수치를 보였다. 이는 여러 실제 세상 application의 시나리오에 반영가능하다.
1. Introduction
Representation Learning 은 시계열 분석에 많은 발전을 이뤘지만, temporal data의 표현을 학습하는 것은 챌린지로 남아 있다. 그러한 표현을 생성하는 것은 많은 이점이 있지만, Pre-training이 가능하다는 것이 가장 실용적인 이점이다. PRe-training에서 중요한 것은 어떤 시계열 데이터가 들어왔을 때 범용성을 보이는 프로세스 과정을 거칠 수 있냐는 것이다. 이는 데이터셋을 neural network로 학습하고 파인튜닝을 통해 새로운 데이터셋에 transfer 하는 것을 포함한다. 즉, target data에 대해 새로 학습하는 것이 아니어도 퍼포먼스가 SOTA모델만큼 나와야 한다.
그러나, 퍼포먼스가 그렇게 좋지 못함을 알고 있다. 이는 시계열의 복잡성 때문이다. 일시적인 다이나믹스와 다양한 semantic meaning, irregular sampling, system factors 등으로 인하여 나타난다. 이러한 복잡성은 pre-training의 전이에 방해 요소가 된다. 이러한 문제는 어떤 inductive biases 가 시계열의 generalizable 표현을 학습할 수 있는지에 대한 문제가 된다.
본 논문은 novel time-frequency consistency principle을 제시한다.
게다가, 타겟 데이터셋들은 pre-training 과정에서 주어지지 않는다. 이는 pre-traning 모델이 unseen target dataset에 대해 latent property 를 캡쳐해야 한다는 의미이다. 컴퓨터 비전에서는 pre-training이 초기 신경망 층에서 universal visual elements를 잡고(엣지, 쉐입) 이것은 이미지 스타일이나 태스크에 영향이 없기 떄문이다. NLP에서는 pre-training이 semantics 와 문법이 언어와 상관없이 베이스가 되기 때문이다. 그러나 시계열은 아직 이러한 베이스라인이 잡히지 않았다. 게다가 supervised pre-training은 더 큰 annotated datasets를 요구하는데 라벨된 데이터셋이 많은 도메인이 적기 때문에 도메인의 제한을 두게 된다. 이러한 이슈를 다루기 위해 self-supervised learning이 라벨된 데이터셋의 제한을 극복하는 대안으로 제시되고 있다.
Present Work
TF-C 모델링 기반으로 시간 기반 및 주파수 표현을 특정하는 것으로, 표현간의 거리가 가깝다. 특별히, 시간 도메인에서는 contrastive learning을 통해 time-based representation을 만든다. frequency spectrum의 특성을 이용하여 주파수도메인에서는 augmentation을 진행하는데, contrastive instance discrimination을 통해 embedding을 진행한다. 이것의 첫 번째는 주파수 기반의 대조 augmentation 을 develop하여 spectral 정보를 사용하고 타임도메인에서의 시간-주파수 consistency를 찾게 된다. pre-training 목적은 time-based 와 frequency based의 embeddings의 거리를 줄이는 것이다. 이는 novel consistency loss를 통해 가능하다. self-supervised loss는 pre-training model을 최적화 하는데 사용되고, latent space의 시간 - 주파수 도메인의 consistency를 강화하는데 사용된다. 이렇게 학습된 관계는 모델 파라미터들에 인코드되어 fine-tuning 모델을 시작하는데 사용되며 새로운 데이터셋이 들어왔을 때 성능을 높이게 된다.
우리는 TF-C 모델을 8개의 시계열 데이터셋에 2가지 평가 세팅에 적용하였다. 결과는 TF-C의 전이가 긍정적이었으며, 모든 베이스라인 모델들모다 F1 스코어에서 마진이 높은 것으로 나타났다. TF-C 접근 방식이 이전의 방법보다 8.4% 정확도가 높아 하나의 pre-trained model로 많은 fine-tuning dataset을 적용하는데에 이전 연구보다 성능이 좋음을 보였다.
2. Relased Work
Pre-training for time series
시계열의 self-supervised representation learning 에 대한 시도는 시계열 및 이미지에 있어왔다. 하지만 시계열에 대한 pre-traning 과정은 아직 성숙하지 못해서 어떤 합리적인 가정이 pre-training 과 타겟 데이터셋을 연결해주는지 알려지지 않았다. 따라서, CV와 MLP에서의 pre-training model은 직접적으로 사용이 불가하다. shi et al은 explictly self-supervised 시계열 pre-training에 대해 모델을 디자인하였다. 모델이 local 그리고 global 패턴을 학습하였지만, 이렇게 design된 pretext task가 왜 generalizable representation을 캡쳐하는지 잘 알려지지 않았다. 다른 연구에서도 마찬가지로 transfer learning을 시계열에 적용해 보았지만, 아직 어떡 conceptual 특성이 시계열에서 효과적인지 알려진 것이 없다. 이 갭을 극복하기 위해 우리는 TF-C를 도입하여 다른 time-series에 invariant하며 generalizable pre-training models 를 만든다.
도메인 adaptation과 다르게 pre-training 모델은 fine-tuning datasets에 access 할 수 없다. 결과적으로 generalizable 시계열 특성을 특징하는 것이 필요하다. 게다가, self-supervised domain adaptation은 타겟 데이터셋이 라벨될 필요 없지만 모델 트레이닝에서는 필요하다. 하지만 TF-C에서는 pre-training 과정에서 라벨이 전혀 필요 없다.
Contrastive learning with tiem seris
대조 학습은 self-supervised learning 에서 아주 유명한 방법이다. encoder를 학습하고 inputs을 embedding space로 넣는 방법으로 이것을 통해 positive sample pairs가 가까워지며, negative sample pairs가 멀어진다. 시계열의 대조학습은 comparison에서는 덜 조사되었는데 이는 시계열에서 capture key invariance properties 때문이다. 예를들어 CLOCS 는 근접한 시간 세그먼트를 positive pair로 둔다. TNC는 겹치는 temporal 이웃들을 비슷한 representations로 본다. 이러한 방법은 temporal invariance를 positive pairs를 정의하고 constrastive loss를 계산하는데 사용된다. transformation invariance와 같은 변환 및 contextial invariance, augmentations 가 가능할때 이야기이다. 이 work에서는 우리는 augmentation bank가 다양한 invariances를 사용하여 diverse augmentations를 generate하는 것을 제안한다. 이는 pre-training 모델에 richness를 주며 우리는 frequency-based augmentations(frequency spectrum의 component를 추가하거나 빼거나 amplitude를 변환) 하는 방식으로 better representation을 진행한다. 이전의 work에서는 CoST 과정이 sequential signals가 fr domain에서 신호 처리를 진행했지만 augmentation이 시계열에서 이루어졌었다. 비슷하게 BTSF가 주파수 도메인을 포함하고 있지만 데이터 변환이 완전히 시간 도메인에서 instance-level dropout으로만 이루어졌다. 따라서 우리의 지식으로는 주파수 스펙트럼의 변형을 통해 augmentation을 주파수 도메인에서 진행한 것이 처음이며 contrastive learning 을 진행한 것이 contribution이 될 것이다. 게다가 우리는 pre-training model을 develop하여 TF-C가 2개의 individual contrastive encoder에 대응되게 하였다.
3. Problem Formulation
Problem (Self-Supervised Contrastive Pre-Training For Time Series)
라벨이 되어 있지 않은 pre-training dataset이 N samples와 target dataset 이 M samples가 있다면, 우리의 목표는 pretrained model F를 사용하여 파인튜닝 모델이 generalizable representations를 모든 인풋 시계열 데이터에 나타내는 것이다.
Rationale for Time-Frequency Consistency (TF-C)
중심 아이디어는 general property 를 identify하여 전이 학습이 가능케 하는 것이다. 현재 존재하는 대조학습 방법은 시간 도메인에서 집중하고 주파수 도메인을 무시한다. 두 도메인의 관계를 통해 시계열 분포와 상관없이 invariance 를 주어 pre-traning 에 inductive bias를 주는 것이 좋다. 이러한 invariance 를 통해 TF-C를 도입하는데 이는 모든 샘플 xi에 대해 ziT,ziF 표현을 가지는 latent time-frequency space가 존재한다는 것이다. local augmentation을 통해 각각 가깝게 된다.
Representational Time-Frequency Consistency (TF-C)
우리의 접근은 데이터셋을 통해 TF-C F모델 파라미터를 추론한다. 이를 통해 타겟 모델을 initialize하고 또한 generalizable representations를 제공한다. 이런 invariant nature of TF-C 는 Dpret 과 Dtune을 연결해주며 큰 불일치가 있다해도 가능하다. TF-C를 실현하기 위해 모델 F는 4가지 component가 있다. 타임 인코더 GT, 주파수 인코더 GF, two cross-space progectors RT & RF(이들은 같은 time-frequency space로 project 시켜준다.) 4개의 컴포넌트들은 인풋을 임베드한다.
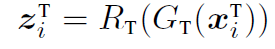
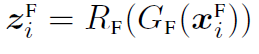
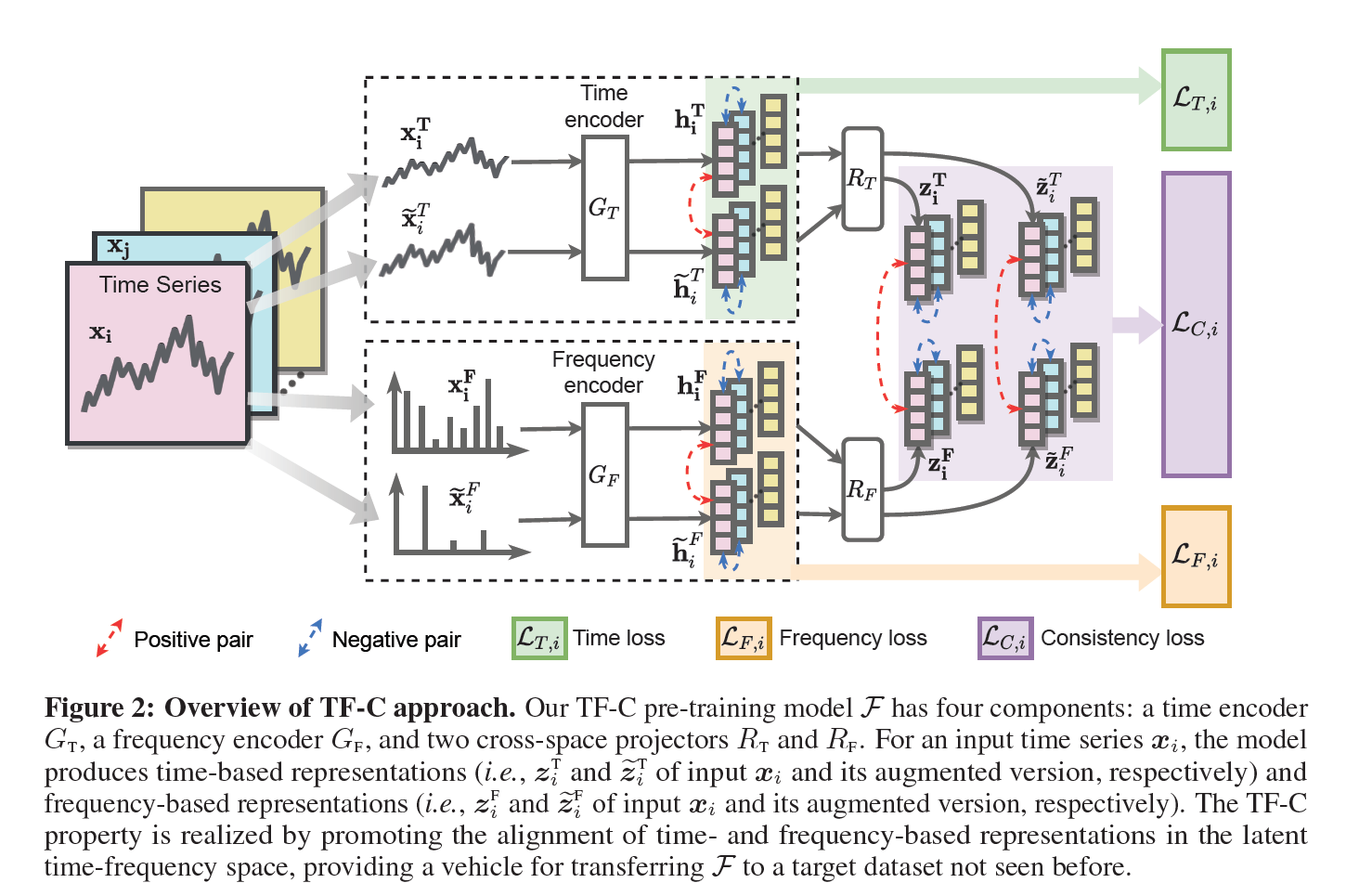
4. Our Approach
다음으로, self-supervised contrastive pre-training model F를 develop한다.
4.1 Time-Based Contrastive Encoder
인풋 xi가 들어오면 augmentation을 생성한다. 이전에 구축되어진 augmentation bank를 통해 jittering, scaling, time-shifts, neighborhood segments 를 사용한다. augmented sample은 contrastive encoder에 들어가 positive pair와 negative pair를 정한다. 같은 데이터인데 augmentation이 진행된 경우 positive pair, 다른 시점에서 augmentation된 것은 negative pair가 된다. Contrastive time loss는 negative pair의 similarity를 줄이고, positive pair의 similarity를 높인다. 이는 NT-Xent를 도입하여 다음과 같은 식이 산출된다.
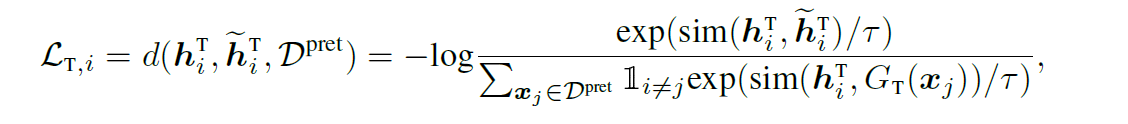
4.2 Frequency-based Contrastive Encoder
Frequency specturm을 변형하는데, 이는 주파수 컴포넌트를 추가하거나 제거함으로써 나타난다. 주파수 component의 작은 변화도 시계열 입장에서는 큰 변화를 이어진다. 따라서 이런 변화가 일어나도 시계열 도메인에서는 변화가 거의 없게 하기 위해 small budget E를 사용하는데 이는 변화한 주파수 component 수 이다. Component 삭제는 E개 만큼 0으로 amplitude를 만들면 된다. 반면에 frequency component를 추가하는 경우 E개 만큼 스펙트럼에서의 max값에 일정한 비율을 곱해서 추가한다. 이 연구에서는 0.5만을 앞에 계수로 곱해 추가하였다.
GF의 frequency encoder를 통해 frequency-based enbedding을 진행하였고 그러므로 시계열과 마찬가지로 pos pair과 negative pair를 두었다.
Contrastive frequency loss
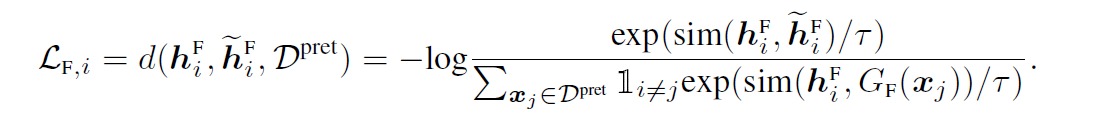
4.3 Time-Frequency Consistency
consistency loss item을 develop하였는데, 이것은 TF-C 임베딩을 만족한다. Time-based 와 Frequency-based frequency embedding은 각각 가까워지도록 한다. 임베딩 사이의 거리가 측정 가능하게, joint-frequency space 를 프로젝터 Rt와 Rf로 만든다.
Consistency Loss식을 만드는데, 이것은 time-frequency space 이므로 ZiT와 생성된 ZiT 2개의 embedding들 사이의 거리는 비교하지 않는다.
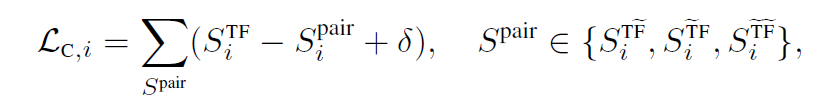
ZiT는 ZiF에 ZiF생성된것보다 더 가까워야 한다. 따라서 이 로스식을 세우는데 델타값은 pre-defined constant로 negative samples 가 가져야할 최소 거리를 나타낸다.
4.4 Implementation and Technical Details
전체적인 loss function은 3가지 텀으로 나타내진다. 이것들의 가중치를 주기 위해 총 loss식의 텀은 다음과 같이 주어진다.
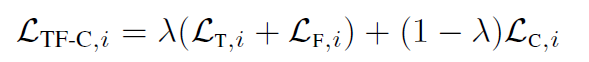
람다를 통해 contrastive & consistency loss의 중요도를 컨트롤 한다. 토탈 로스를 구한다.
5. Experiments
5.1 One-to-One Pre-Training Evaluation
TF-C 모델을 10개의 baselines 와 8개의 diverse dataset을 비교하였다. 시계열 분류 태스크에 one to one & one to many 전이학습을 세팅하였다. TF-C의 다운스트림 task로 클러스터링과 이상탐지를 포함하였다.
Dataset : SLEEPEEG, EPILEPSY, FD-A, FD-B, HAR, GESTURE, ECG, EMG
Baseline : SOTA TS-SD, TS2vec, CLOCS, Mixing-up, TS-TCC, SimCLR, TNC, CPC
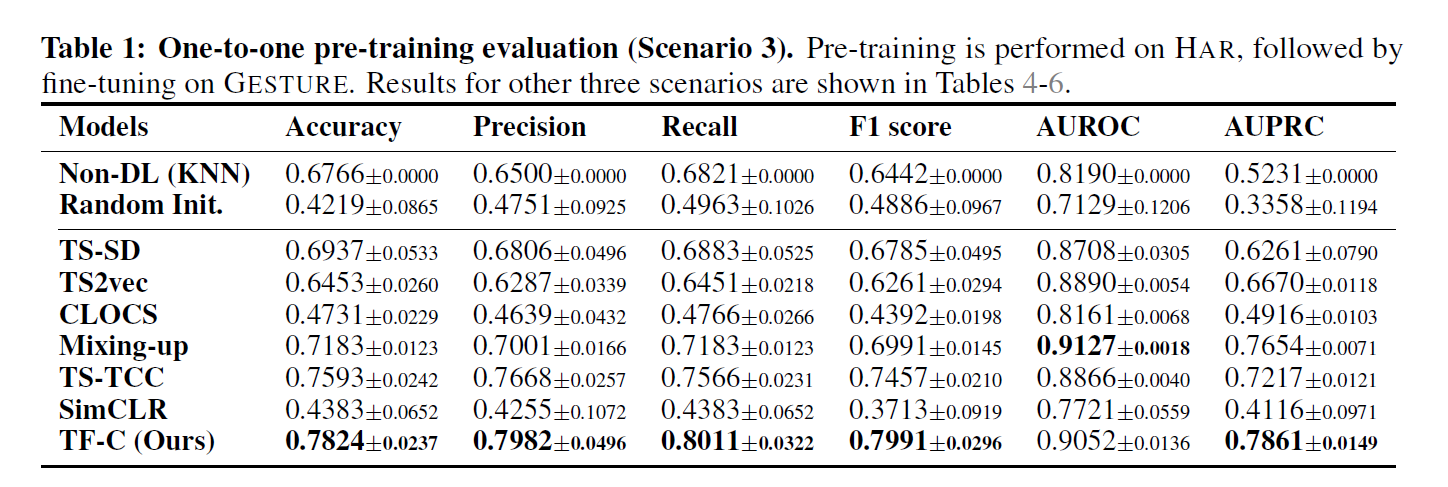
전체적으로 제안한 TF-C 모델의 성능이 높게 나타났음. 전체 모델보다 15.4% 향상을 보였다.
5.2 One-to-Many Pre-Training Evaluation
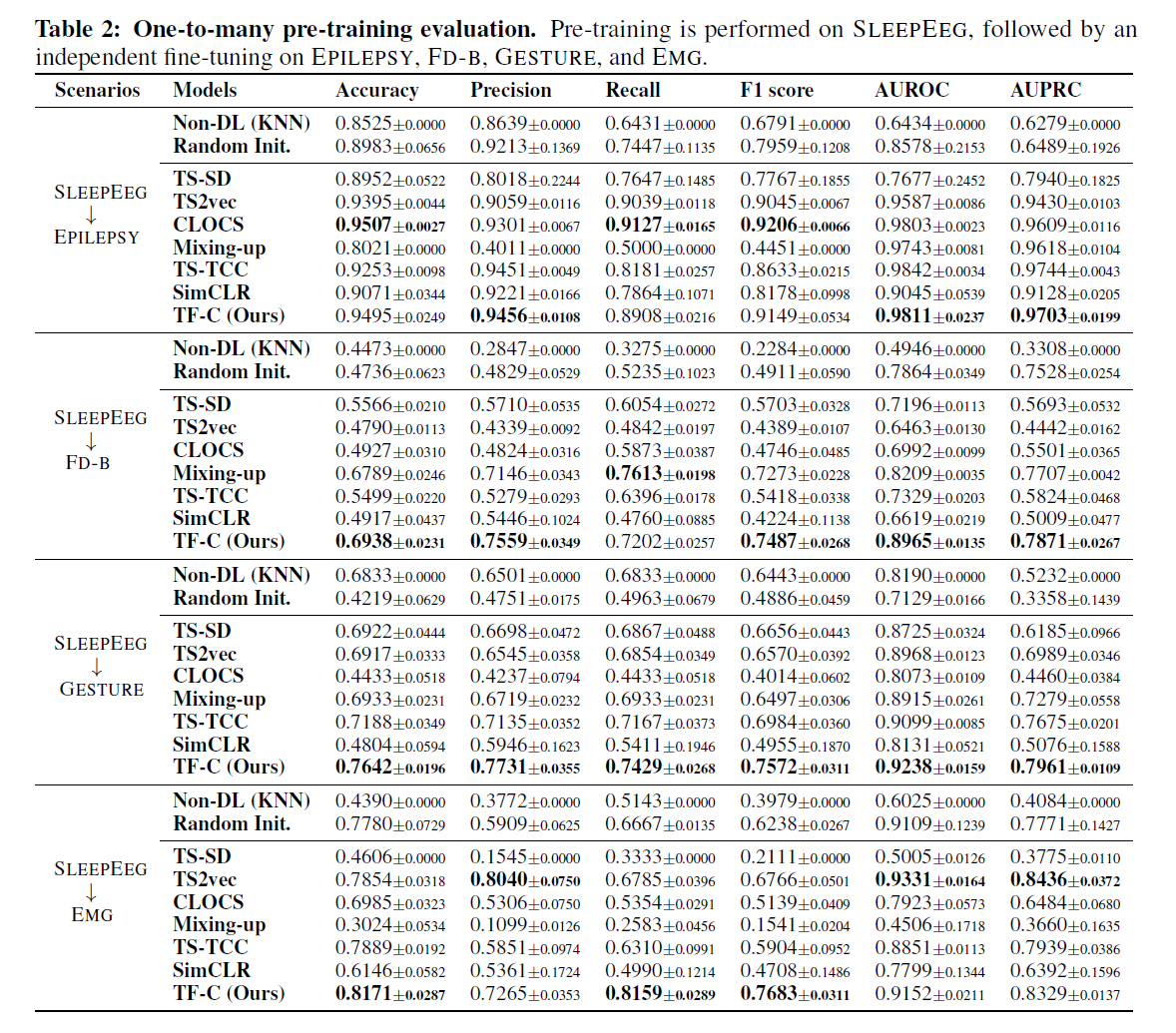
Pre-training 을 one dataset으로 진행한 뒤 multiple 전이학습을 진행하였다. 8개의 데이터셋 중에 SLEEPEEG가 temporal dynamics가 복잡하고 데이터 양이 많기 때문에 이를 메인으로 학습을 진행하였다. EEG와 진동, 가속 데이터는 commonnalities가 적기 때문에 one-to-one 보다는 정확도가 떨어질 것으로 예측하였다. 우리의 데이터는 이러한 large - gap에도 불구하고 다른 모델들보며 높은 tolerance를 보였다. 또한 18개의 세팅 중 14개나 최고의 성능을 나타내었다.
5.3 Additional Downstream Tasks : Clustering and Anomaly Detection
Clustering Task
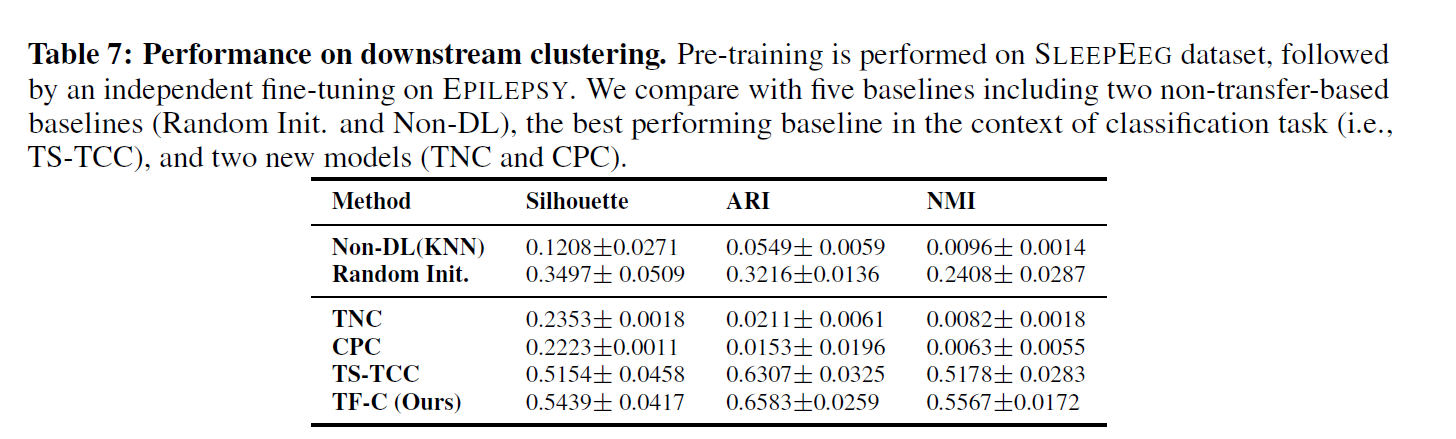
best clustering sbaseline(TS-TCC)를 앞섬을 보여준다. TF-C가 더 distinctive representations를 pre-training 에서 좀 더 가져옴을 알 수 있다.
Anomaly Detection Task
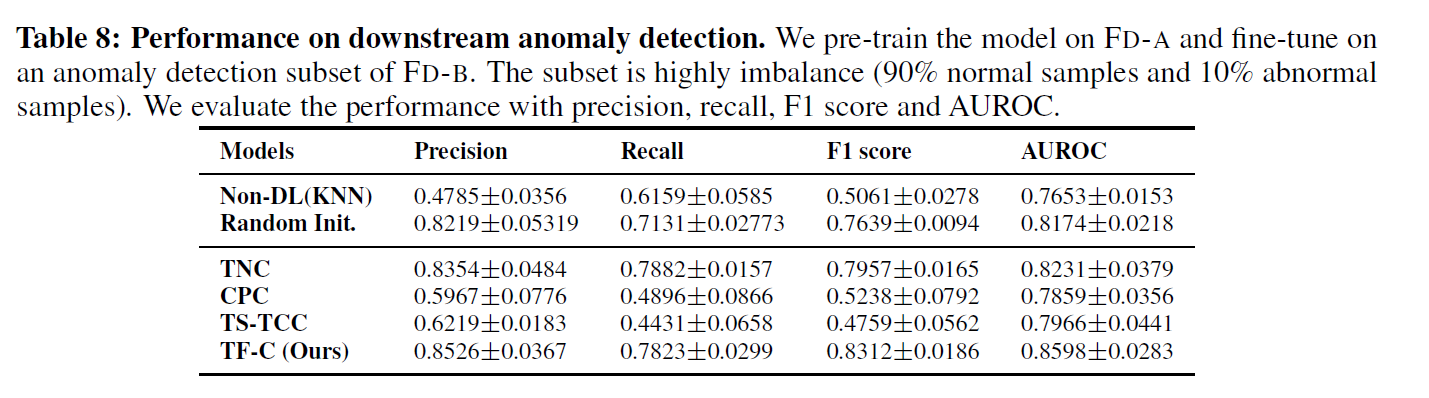
우리는 sample-level 에 집중하였고, obsevation level은 집중하지 않았다. 전자는 outlier observation 보다는 샘플 단에서 abnormal을 찾아내는 것으로 local context를 강조하는 BTSF, USAD 등이 있다. TF-C가 결과적으로 다른 baseline 보다 outperform 하다는 것을 보여준다.
6. ConClusion
pre-trained approach를 통해 TF-C 의 개념을 도입하였고, 시계열 데이터셋의 knowledge 전이 매커니즘을 정립하였다. 이 방식은 self-supervised 대조 예측 방법론으로 pre-training 과정ㅇ에서 TF-C를 도입하고 time-based & frequency based representations를 학습한뒤 그들의 local neigborhoods를 latent space에 넣는다.
Limitations and future directions.
TF-C 특성은 pre-training on diverse time seires datasets에 적합하다. 또한 추가적인 generaliable 특성은 시계열 pre-training에 적합함을 보였다. 게다가 우리의 방법이 irregularly sampled 시계열에 인코더를 통해 embed 할 수 있음을 보였다. 게다가 TF-C의 embedding 전략과 로스 펑션은 classification에 적합하며, 이는 글로벌 정보를 local context에서 추출할 수 있기 때문이다. 결과는 클러스터링, 분류, 이상탐지를 포함한 downstream task에도 좋은 성능을 보임을 알 수 있었다.
