Abstract
반도체 제품의 품질을 보장하고, 올리기 위해 많은 방법이 적용되어 왔음
하지만 기술의 진화와 제품의 다양성으로 인해 defect은 점점 더 다양해지며 컨트롤 하기 힘듬
본 연구에서는 단위 공정별로 생성된 데이터로 최종 반도체 생산품 품질을 예측함
퍼포먼스를 높이기 위해 failure occurrence environment 및 data characteristics 고려
기술의 복잡성 때문에 같은 유형의 defect도 다른 원인으로 나타남
Unsupervised learning (K-means, Self-Organized Map)을 통해 defect 타입을 특징과 품질 예측으로 나누는 시스템 제안
퍼포먼스를 AUC(Area Under ROC Curve)에서 4.4%p 향상, partial AUC에서 6.8% 향상함
1. 서론
불량의 발생은 다음과 같이 흐름
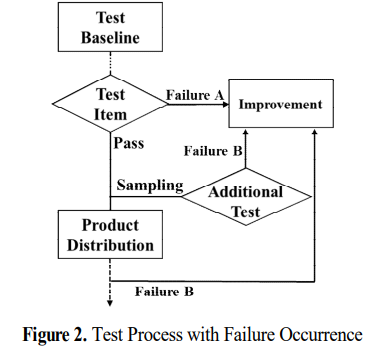 불량 A는 테스트 항목에서 불량으로 식별이 가능하지만, 불량B는 정상 물량에 대한 추가 품질 불량
불량 A는 테스트 항목에서 불량으로 식별이 가능하지만, 불량B는 정상 물량에 대한 추가 품질 불량
불량 B는 A와 성격이 다른 불량 유형으로 이전에 진행된 테스트 데이터를 통계 분석을 하여 다음 단계에서 발생할 품질을 예측하고 향상시킴
웨이퍼 Bin Map 에 군집화를 적용하고 패턴 추출하여 제조 결함과 연관시키는 연구(Hsu and Chine,2007)
-> 패키지 수율을 예측하고 개선했지만, 칩 단위 품질 예측에는 비적합하며 2진 데이터 Bin Map 만 처리
반도체 FBC(Fail Bit Count) 정보에서 OPTICS 기법을 통해 특질 추출하여 칩 단위의 품질 예측 연구 (Kim and Baek, 2014)
-> 프로브 테스트의 FBC 데이터만을 통해 추출된 2가지 특질 정보를 활용하여 FBC 특성을 따르는 품질 문제에만 적용
프로브 테스트의 FBC 데이터를 이용해 패키지 칩 단위 품질 예측(Park and Kim, 2015)
-> 마찬가지로 프로브 테스트의 FBC 데이터만을 활용하여 품질예측
앞선 연구들은 프로브 테스트 데이터를 통해 이후의 패키지 수율이나 품질을 예측하였으나,
1. 칩 단위에서 불량의 종류를 식별하지 못함
2. 사용된 독립 변수가 FBC 혹은 2진 Bin Map으로 다양한 종류의 품질 문제 대표하지 못함
3. 성능 평가에서 예측 모델의 전반적인 정확도를 성능 척도로 사용하여 반도체 데이터의 범주 불균형이 극심하여 성능의 왜곡을 가져옴
본 연구에서는
1. 칩 단위의 반도체 품질을 예측하며 불량의 종류를 특성별로 나누어 식별
2. 최종 품질 예측 성능 향상
프로브 테스트, 패키지 테스트 전압 및 전류, BBC(Bad Block Count), FBC, 동작 신호 측정값 사용
BBC : 낸드 플래시 block 문제 발생 시 결점으로 나옴
FBC : 비트 정보를 저장하는 셀 영역에 결점이 있을 때 결점을 비트 수로 나타낸 값
발생 불량에 대해 군집화를 진행하여 특성별로 군집화된 불량을 사용하여 품질 예측 모델 구축
ROC(Receiver Operating Characteristic)의 AUC(Area Under the ROC Curve)를 비교하여 전반적인 영역에서 비교하고 결과 왜곡 방지
민감도 향상을 확인하기 위해 Partial AUC를 통해 결과 추가 비교
2. 군집화 적용 및 품질 예측
다음과 같은 반도체 품질 불량을 특성별로 분류 및 품질 예측 진행하는 시스템 구축
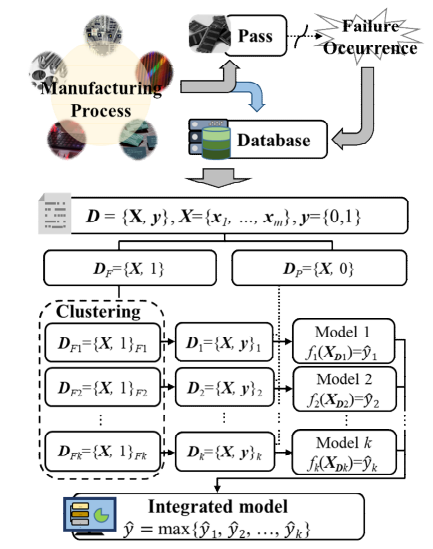 불량을 특성별로 나누어 구축한 품질 예측 결과로 확률 값 출력
불량을 특성별로 나누어 구축한 품질 예측 결과로 확률 값 출력
하나 이상의 품질 예측 모델이 불량이라 판별하면 불량으로 판별 및 불량 종류 판단
데이터세트 D 중, y = 0인 경우 정상, y=1인 경우 불량
불량 데이터셋인 DF에 대해 군집화를 선행하여 불량 특성에 따라 나눔
k개로 군집화 된 불량 데이터세트에 각각 정상 데이터세트를 추가하여 k개의 데이터세트 만듦
각각의 예측모델에 들어가게 되고, k개의 예측치를 확률로써 출력함
가장 불량 확률을 높게 예측한 모델의 예측값을 취하고, 불량 여부 판별 및 k개의 군집 중 가장 높게 예측한 군집으로 할당하여 불량 종류에 대해 판단
2.1 데이터 불균형
SMOTE(Synthetic Minority Over-sampling Technique) 기법을 통해 데이터 불균형 해결
k-nearist Neighbor 기반의 오버샘플링
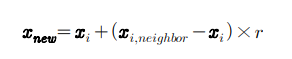
Xi와 Xi,neighbor 간의 Hyperplane 상 직선 내에 새로운 관측치를 생성
2.2 군집화
(1) K-Mean 군집화
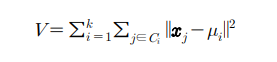
각 군집별로 부터 관측치 간 거리의 제곱합을 최소로 하는 군집 C를 찾는 것
(2) 자기조직화지도 군집화
인공신경망을 통해 관측치 간 상호 비교를 하여 경쟁 학습 바탕의 승자 독점 방식 사용
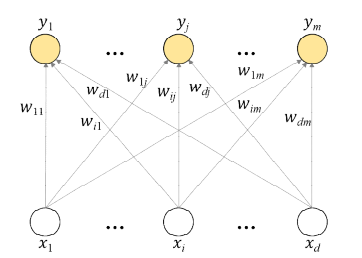
두개의 층으로 구성된 신경망에서 관측치 특질 벡터 x 와 가장 가까운 노드가 경쟁에서 승리하면 해당 가중치 벡터를 업데이트
2.3 품질 예측 모델
AIC : 데이터를 가장 잘 나타내는 분포와 모수를 결정
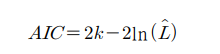
가장 값이 작은 모델을 적합한 모델로 사용
최대우도 함수의 파라미터집합은 정규분포를 따른다면 평균벡터와 공분ㅂ산 행렬로 이루어짐
2K는 패널티 항으로 독립변수 증가에 따른 과적합을 방지
3. 데이터 및 성능 척도
(1) 데이터
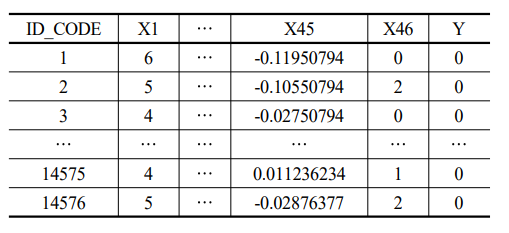
다음과 같은 데이터를 사용하였으며 독립변수는 46개, 종속변수는 최종불량여부
(2) 성능 척도
이진 분류에서 많이 사용되는 ROC커브의 AUC 사용
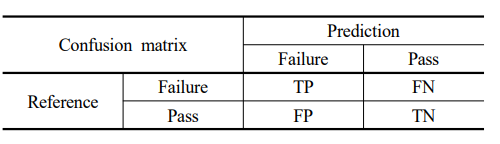

실제 값과 예측 값에 따라 Confustion Matrix는 다음과 같음
제 1종 오류를 허용 한도 범위로 정한 후 민감도를 높여야 함
특이도 허용 범위에 따라 성능이 변화하므로 Partial AUC 사용하여 예측모델 간에 동일한 특이도 값에 대한 민감도 성능 차이 비교
4. 실험 결과
(1) 군집화 결과
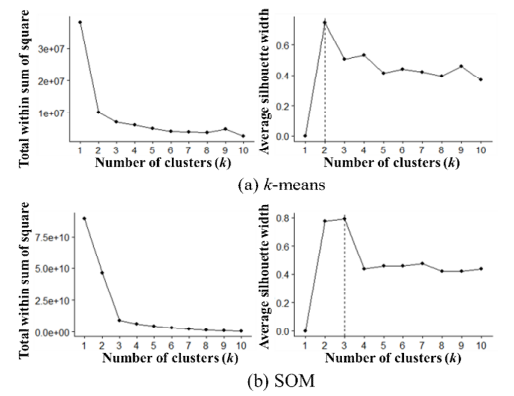
군집화 기법별 평가 *총 제곱합, 평균 실루엣 사용
k-means는 군집수 2가 최적
자기조직화지도는 군집수 3이 최적
-> 해당 불량이 2,3 종류의 특성을 보이며 현장의 경험을 토대로 군집화 수를 확장해나가며 품질예측 모델 간 성능 비교
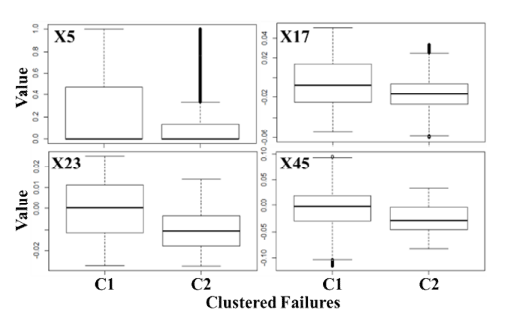
군집 간 변수들의 평균, 표준편차 특성을 통해 현업에서 불량의 종류를 구분하고 특성 분석 단서로 활용
(2) 품질 예측 성능 비교
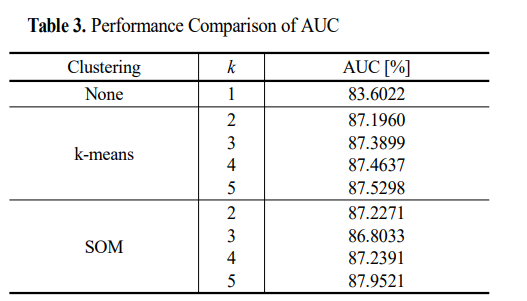
비군집 예측 모델에 비해 군집화 적용 시 평균적으로 3.75%의 AUC 개선
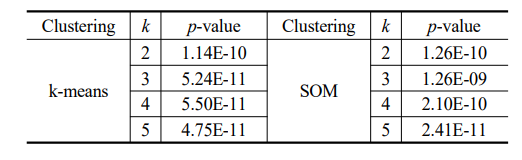
이표본 t-검정에 따른 유의차를 보면, 비군집과 군집화 적용 모델의 차이의 p value가 작아 성능 차이 유의함을 알 수 있음
군집화를 적용한 방법들 내에서는 p value가 큰 차이가 없어 차이가 유의하지는 않음
군집화가 큰 예측 모델의 경우에는 각 군집에 할당되는 불량의 수가 줄어들어 과적합의 가능성이 있어 군집수는 2가 적합하다 판단
(3) ROC 커브 비교
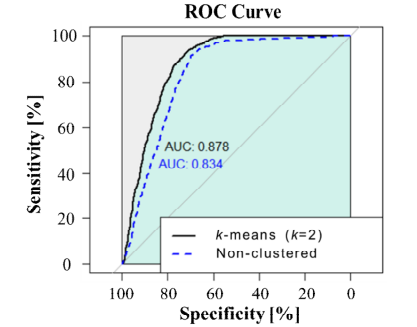
비군집과 군집수 2의 k-mean 적용 예측 모델의 ROC Curve 비교 시 모든 범위에서 민감도 성능이 우수하며, AUC는 4.4% 향상
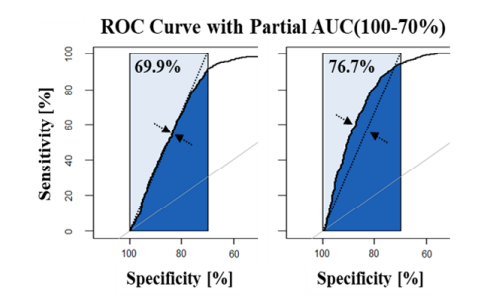
현실적으로, 1종 오류를 허용 한도로 정한 후 민감도를 높여야 함
-> 특이도 허용 한도 100~70%내 성능인 partial AUC를 ROC커브로 비교 시 성능이 더 우수하며, AUC는 6.8% 향상
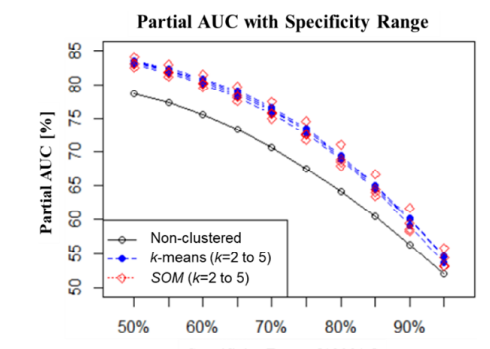
비군집 및 군집화 적용 모델 특이도 95%~50% 범위에서 Partial AUC를 10겹 교차 검증 평균값
-> 모든 범위에서 군집화 예측 모델이 우수함. 특이도 70~75% 구간에서 가장 많은 성능 차이를 나타냄
민감도를 높이기 위해 1종 오류의 허용 기준을 높게 가져갈 수 없기 때문에 전체 특이도 범위의 AUC보다는 허용 범위의 partial AUC를 설정하는 것이 현실적임
5. 결론
불량 발생 환경 및 데이터의 특성을 반영한 군집화를 통해 품질 불량 분류 및 예측 방법 제시하고 일반적인 방법과 성능을 비교
ROC커브의 AUC 및 partiacl AUC를 통해 제안된 예측 모델의 성능개선 확인
-> 불량의 종류와 관련 인자의 간접적인 단서를 찾을 수 있을 것으로 기대
불량의 종류가 더욱 다양하고 복잡도가 높은 공정 데이터에 더 큰 수의 군집수가 나올 수 있으며, 데이터의 특성을 여러 방향으로 분석하고 추가 기법들을 탐색하는 연구가 필요할 것
