네 개의 영역
다음은 아키텍처를 설계할 때 출현하는 전형적인 네 가지 영역에 해당한다.
| 영역 | 역할 |
|---|---|
| Presentation | 사용자의 요청을 받아 응용 영역에 전달하고, 응용 영역의 처리 결과를 다시 사용자 (= 웹 브라우저의 사용자, REST API를 호출하는 외부 시스템) 에게 보여주는 역할을 한다. |
| Application | 시스템이 사용자에게 제공해야 할 기능 (= 주문 등록, 주문 취소) 을 도메인 영역의 도메인 모델에게 로직 수행을 위임함으로써 구현한다. |
| Domain | 도메인의 핵심 로직 (= 배송지 변경, 결제 완료) 을 갖는 도메인 모델을 구현한다. |
| Infrastructure | RDBMS 연동 처리, 메시징 큐에 메시지 송수신 등의 실제 구현 기술에 대한 것을 다룬다. |
계층 구조 아키텍처
아키텍처를 설계하는 전형적인 네 가지 영역은 일반적으로 계층 구조를 갖는다.
계층 구조는 특성상 상위 계층에서 하위 계층으로의 의존만 존재하며, 하위 계층은 상위 계층에 의존하지 않는다.
계층 구조를 엄격하게 적용한다면 상위 계층은 바로 아래의 계층에만 의존을 가져야 하지만, 구현의 편리함을 위해 계층 구조를 유연하게 적용하기도 한다.
Application 과 Domain 은 DB나 외부 시스템 연동을 위해 Infrastructure 기능을 사용하므로 계층 구조를 사용하는 것은 직관적으로 이해하기 쉽다.
하지만 표현 · 응용 · 도메인이 상세한 구현 기술을 다루는 Infrastructure 계층에 종속된다는 점은 꼭 짚고 넘어가야 한다.
도메인의 가격 계산 규칙을 예로 들어보자.
Application 로직에서 가격 계산을 위해 Infrastructure 영역의 DroolsRuleEngine 을 사용하고 있다.
코드만 보면 Drools 가 제공하는 타입을 직접 사용하지 않으므로 Drools 자체에 의존하지 않는다고 생각할 수 있다.
하지만 'discountCalculation' 문자열은 Drools 의 세션 이름을 의미하기 때문에, 세션 이름이 변경되면 Application 코드도 변경되어야 한다.
public class DroolsRuleEngine {
private KieContainer kContainer;
public DroolsRuleEngine() {
kisServices ks = KieService.Factory.get();
kContainer = ks.getKieClasspathContainer);
}
public void evaluate(String sessionName, List<?> facts) {
KieSession kSession = kContainer.newKieSession(sessionName);
try {
facts.forEach(x -> kSession.insert(x));
kSession.fireAllRules();
} finally {
kSession.dispose();
}
}
}public class CalculateDiscountService {
private DroolsRuleEngine ruleEngine;
public CalculateDiscountService() {
ruleEngine = new DroolsRuleEngine();
}
public Money calculateDiscount(List<OrderLine> orderLines, String customerId) {
Customer customer = findCustomer(customerId);
MutableMoney money = new MutableMoney(0);
List<?> facts = Arrays.asListcustomer, money);
facts.addAll(orderLines);
ruleEngine.evaluate("discountCalculation", facts);
return money.toImmutableMoney();
}
...
}
CalculateDiscountService는 다음과 같은 두 가지의 문제점을 가진다.
1. 서비스 로직만을 테스트하기 어렵다.
2. 구현 방식을 변경하기 어렵다.
이처럼 응용 영역이 Infrastructure 에 의존하면 '테스트 어려움'과 '기능 확장의 어려움' 라는 두 가지 문제가 발생하게 된다.
이러한 문제를 해결할 수 있는 해답은 바로 DIP 에 있다!
DIP
가격 할인을 계산하기 위해서는 다음과 같은 두 개의 로직이 반드시 수행되어야 한다.
- 고객의 정보 구하기
- 구한 고객 정보와 주문 정보를 이용해 룰을 실행하기
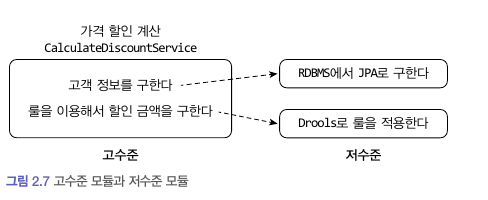
의미 있는 단일 기능을 제공하는 모듈을 고수준 모듈이라고 하며, 고수준 모듈의 기능을 구현하기 위해서는 여러 하위 기능이 필요하다.
가격 할인 계산 기능을 구현하기 위해 수행되어야 하는 두 로직이 바로 하위 기능에 해당한다.
고수준 모듈이 제대로 동작하기 위해서는 저수준 모듈을 사용해야 하는데, 이 과정에서 구현 변경과 테스트가 어렵다는 문제가 발생한다.
DIP 는 이 문제점을 해결하기 위해 저수준 모듈이 고수준 모듈에 의존하도록 의존 방향을 바꾼다.
의존 방향을 바꾸는 마법은 바로 추상화한 인터페이스에 있다.
public interface RuleDiscounter {
Money applyRules(Customer customer, List<OrderLine> orderLines;
} public class CalculateDiscountService {
private RuleDiscounter ruleDiscounter;
public CalculateDiscountService(RuleDiscounter ruleDiscounter) {
this.ruleDiscounter = ruleDiscounter; // 생성자를 통해 인터페이스의 구현체를 주입받음
}
public Money CalculateDiscount(List<OrderLine> orderLines, String customerId) {
Customer customer = findCustomer(customerId);
return ruleDiscounter.applyRuoles(customer, orderLines);
}
...
} 다음과 같이 RuleDiscounter 인터페이스를 적용하도록 코드를 수정했다.
이제 CalculateDiscoutService 에는 Drools 에 의존하는 코드가 존재하지 않는다.
단지 RuleDiscounter 가 룰을 적용한다는 사실만을 알 뿐이고, 인터페이스 구현 객체는 생성자를 통해서 주입받는다.
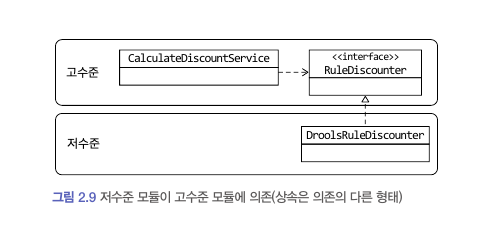
CalculateDiscountService 는 더 이상 구현 기술 Drools 에 의존하지 않는다.
'룰을 이용한 할인 금액 계산'을 추상화한 RuleDiscounter 인터페이스를 의존할 뿐이다.
이처럼 인터페이스를 적용함으로써 저수준 모듈이 고수준 모듈에 의존하도록 의존 방향이 바뀌었다.
이를 가능하게 하는 것을 Dependency Injection Principle, 의존 역전 원칙이라고 부른다.
DIP를 적용함으로써 앞의 두 가지 문제점이 어떻게 해결되었는지를 확인해보자.
- 구현 기술 교체 문제
고수준 모듈은 더 이상 저수준 모듈에 의존하지 않고 구현을 추상화한 인터페이스에 의존한다.
실제로 사용할 저수준의 구현 객체는 의존성 주입을 통해 전달받을 수 있기 때문에 구현 기술을 변경하더라도 Service 를 수정할 필요가 없다.
// RuleDiscounter ruleDiscounter = new DroolsRuleDiscounter();
RuleDiscounter ruleDiscounter = new SimpleRuleDiscounter(); // 사용할 저수준 구현 객체만을 변경
CalculateDiscountService disService = new CalculateDiscountService(ruleDiscounter); // 고수준 모듈은 수정할 필요가 없다!Service자체 테스트의 어려움
Service 가 제대로 동작하는지 테스트하기 위해서 CustomerRepository 와 RuleDiscounter 구현체가 필요하다.
기존에는 고수준 모듈인 Service 가 저수준 모듈에 직접 의존했기 때문에 저수준 모듈이 만들어지기 전까지 테스트를 수행할 수 없었다.
그러나 인터페이스를 도입함으로써 대역 객체를 사용해서 테스트를 진행할 수 있게 되었다.
public class CalculateDiscountServiceTest {
@Test
public void noCustomer_thenExceptionShouldBeThrown() {
// 테스트 목적의 대역 객체
CustomerRepository stubRepo = mock(CustomerRepository.class);
when(stubRepo.findById("noCustId")).thenReturn(null);
RuleDiscounter stubRule = (cust, lines) -> null;
// 대용 객체를 주입받아 테스트 진행
CalculateDiscountService calDisSvc = new CalculateDiscountService(stubRepo, stubRule);
assertThrows(NoCustomerException.class, () -> calDisSvc.calculateDiscount(someLines, "noCustId"));
}
} 이렇게 실제 구현 없이 테스트를 할 수 있게 된 것은 DIP 를 적용해 고수준 모듈이 저수준 모듈에 의존하지 않도록 했기 때문이다.
이 때, DIP 를 단순히 '인터페이스와 구현 클래스를 분리하면 되겠네!' 정도로 받아들여서는 안 된다.
DIP 원칙의 핵심은 고수준 모듈이 저수준 모듈에 의존하지 않도록 하기 위함이다.
적용 결과와 구조만을 보고 저수준 모듈에서 인터페이스를 추출하는 잘못된 사용을 하지 않도록 주의하자!
DIP를 적용할 때 하위 기능을 추상화한 인터페이스는 고수준 모듈 관점에서 도출해야 한다.
DIP를 항상 적용할 필요는 없다! 추상화 대상이 잘 떠오르지 않을 수도 있다!
이럴 때에는 무조건 적용하려고 시도하기보다DIP의 이점을 얻는 수준에서 적용 범위를 검토해보자.
도메인 영역의 주요 구성요소
도메인 영역은 도메인의 핵심 모델을 구현한다고 했다.
도메인 영역의 모델은 도메인의 주요 개념을 표현하며 핵심 로직을 구현해야 하고, 이 과정에서 Entity 와 Value 타입을 활용할 수 있다.
| 요소 | 설명 |
|---|---|
| Entity | 고유의 식별자를 갖는 객체로, 자신의 라이프 사이클을 갖는다. 도메인의 고유한 개념을 표현한다. 도메인 모델의 데이터를 포함하며 해당 데잍와 관련된 기능을 함께 제공한다. |
| Value | 고유의 식별자를 갖지 않는 객체로, 주로 개념적으로 하나인 값을 표현할 때 사용한다. Entity의 속성 뿐만 아니라 다른 Value 타입의 속성으로도 사용할 수 있다. |
| Aggregate | 연관된 Entity 와 Value 객체를 개념적으로 하나로 묶은 것을 말한다. |
| Repository | 도메인 모델의 영속성을 처리한다. DBMS 테이블에서 Entity 객체를 로딩하거나 저장하는 기능을 제공한다. |
| Domain Service | 특정 Entity 에 속하지 않은 도메인 로직을 제공한다. 즉, 도메인 로직이 여러 Entity 와 Value 를 필요로 하는 경우 도메인 서비스에서 로직을 구현한다. |
도메인 모델의 Entity 와 데이터베이스 모델의 Entity 는 같다고 볼 수 있을까?
정답은 같지 않다! 이다.
두 모델의 가장 큰 차이점은 도메인 모델의 엔티티는 데이터와 함께 도메인 기능을 제공한다는 점이다.
도메인 모델의 엔티티는 단순히 데이터를 담고 있는 데이터 구조가 아닌, 데이터와 함께 기능을 제공하는 객체이다.
도메인 관점에서 기능을 구현하고 기능 구현을 캡슐화해서 데이터가 임의로 변경되는 것을 막는다.
public class Order {
// 주문 도메인 모델의 데이터
private OrderNo number;
private Orderer orderer;
private ShippingInfo shippingInfo;
...
// 도메인 기능도 함께 제공
public void changeShippingInfo(ShippingInfo shippingInfo) {
...
}
} 또 다른 차이점은, 도메인 모델의 엔티티는 두 개 이상의 데이터가 하나의 개념적 의미를 가질 때 Value 타입을 이용해서 표현할 수 있다는 점이다.
관계형 데이터베이스는 Value 타입을 제대로 표현하기 힘들다.
반면 도메인 모델은 Value 타입을 사용함으로써 도메인을 보다 잘 이해할 수 있도록 돕는다.
Aggregate
도메인이 커질수록 개발할 도메인 모델도 커지면서 많은 Entity 와 Value 가 출현하게 되고, 모델은 점점 더 복잡해진다.
도메인 모델이 복잡해지면 개발자가 전체 구조가 아닌, 한 개의 Entity 와 Value 에만 집중하는 상황이 발생할 수 있다.
때문에 큰 수준에서 모델을 이해하지 못해 큰 틀에서 모델을 관리할 수 없는 상황에 빠지기 쉽다.
이런 상황에 빠지지 않도록 도메인 모델의 전체 구조를 이해하는 데 도움이 되는 Aggregate 를 활용하자!
Aggregate
[사전적 의미] 합계, 총액
관련 객체를 하나로 묶은 군집을 말한다.
대표적인 예로 주문이 있다.
'주문' 도메인 개념은 주문, 배송지 정보, 주문자, 주문 목록, 총 결제 금액 등의 하위 모델로 구성된다.
이러한 하위 개념을 표현한 모델을 하나로 묶어서 주문 이라는 상위 개념으로 표현할 수 있다.
애그리거트를 사용하면 개별 객체가 아닌 관련 객체를 묶어 객체 군집 단위로 모델을 바라볼 수 있게 된다.
개별 객체 간의 관계가 아닌, 애그리거트 간의 관계로 도메인 모델을 이해하고 구현하게 되며, 이를 통해 큰 틀에서 도메인 모델을 관리할 수 있다.
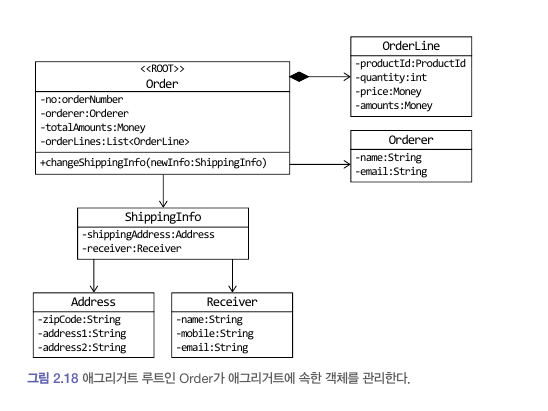
애그리거트는 군집에 속한 객체를 관리하는 root 엔티티를 갖는다.
루트는 애그리거트에 속해 있는 엔티티와 밸류 객체를 이용해서 구현해야 할 기능을 제공한다.
애그리거트를 사용하는 코드는 루트가 제공하는 기능을 실행하고 루트를 통해서 간접적으로 애그리거트 내의 다른 엔티티나 밸류 객체에 접근한다.
이것은 애그리거트의 내부 구현을 숨겨서 애그리거트 단위로 구현을 캡슐화할 수 있도록 돕는다.
public class Order {
public void changeShippingInfo(ShippingInfo newInfo) {
checkShippingInfoChangable(); // 배송지 변경 가능 여부 확인
this.shippingInfo = newInfo;
}
private void checkShippingInfoChangable() {
... // 배송지 정보를 변경할 수 있는지 엽를 확인하는 도메인 규칙 구현
}
} 주문 애그리거트는 Order 를 통하지 않고 ShippingInfo 를 변경할 수 있는 방법을 제공하지 않는다.
배송지를 변경하려면 루트 엔티티를 사용해야 하므로 배송지 변경 시에 Order 가 구현한 도메인 로직을 항상 따르게 된다.
애그리거트를 구현할 때는 고려해야 할 점이 많다.
어떻게 구성했느냐에 따라 구현이 복잡해지기도, 트랜잭션 범위가 달라지기도 한다.
선택한 구현 기술에 따라 애그리거트 구현에 제약이 생기기도 한다.
Repository
도메인 객체를 지속적으로 사용하려면 RDBMS와 같은 물리적인 저장소에 도메인 객체를 보관해야 한다.
이를 위한 도메인 모델이 바로 Repository 이다.
Entity 와 Value 가 요구사항에서 도출되는 도메인 모델이라면 Repository 는 구현을 위한 도메인 모델이다.
Repository
애그리거트 단위로 도메인 객체를 저장하고 조회하는 기능을 정의한다.
public interface OrderRepository {
Order findByNumber(OrderNumber number);
void save(Order order);
void delete(Order order);
} OrderRepository 메서드를 보면 대상을 찾고 저장하는 단위가 애그리거트 루트인 Order 인 것을 알 수 있다.
Order 는 애그리거트에 속한 모든 객체를 포함하고 있으므로 결과적으로 애그리거트 단위로 저장하고 조회하는 셈이다.
도메인 모델을 사용해야 하는 코드는 Repository 를 통해서 도메인 객체를 구한 뒤 도메인 객체의 기능을 실행한다.
도메일 모델 관점에서 OrderRepository 는 도메인 객체를 영속화하는 데 필요한 기능을 추상화한 것으로, 고수준 모듈에 해당한다.
기반 기술을 이용해서 OrderRepository 의 구현 클래스는 저수준 모듈로, Infrastructure 레이어에 속한다.
public class CancelOrderService {
private OrderRepository orderRepository;
public void cancel(OrderNumber number) {
Order order = orderRepository.findByNumber(number);
if (order == null) throw new NoOrderException(number);
order.cancel();
}
} 요청 처리 흐름
사용자 입장에서 봤을 때 웹 애플리케이션이나 데스크탑 애플리케이션과 같은 소프트웨어는 기능을 제공한다.
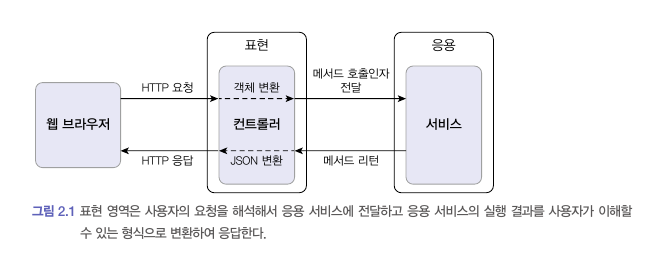
사용자가 애플리케이션에 기능 실행을 요청하면 그 요청을 처음 받아들이는 계층이 바로 표현 Presentation 계층이다.
표현 영역은 사용자가 전송한 데이터 형식이 올바른지 검사하고 문제가 없다면 데이터를 이용해서 Application 에게 기능 실행을 위임한다.
이 때, 사용자가 전송한 데이터를 Application 가 요구하는 형식으로 변환해서 전달한다.
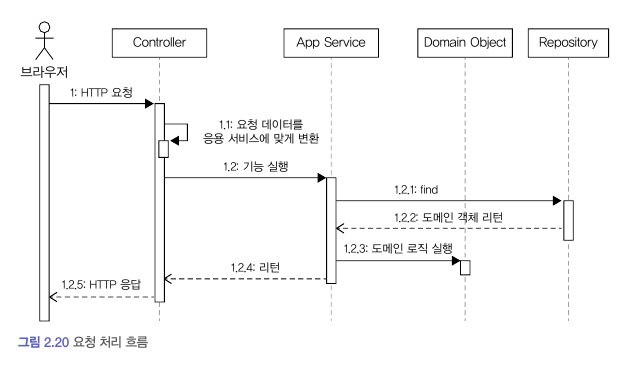
표현 영역에 해당하는
Controller는 HTTP 요청 파라미터를Application에서 필요로 하는 데이터로 변환해서 서비스를 실행할 때 인자로 전달한다.
Application 은 도메인 모델을 이용해서 기능을 구현한다.
기능 구현에 필요한 도메인 객체를 Repository 에서 가져와 실행하거나 새로 생성해서 저장한다.
서비스 로직은 도메인의 상태를 변경하기 때문에 변경 상태가 물리 저장소에 올바르게 반영되도록 트랜잭션으로 관리해야 한다.
public class CancelOrderService {
private OrderRepository orderRepository;
@Transactional // 응용 서비스는 트랜잭션으로 관리
public void cancal(OrderNumber number) {
Order order = orderRepository.findByNumber(number);
if (order == null) throw new NoOrderException(number);
order.cancel(); // 도메인 핵심 로직은 도메인 모델에게 위임
}
...
} 인프라스트럭처 개요
Infrastructure 영역은 Presentation , Application , Domain 영역을 지원한다.
도메인과 응용 영역에서 구현 기술에 직접 의존하는 것보다 두 영역에 정의한 인터페이스를 Infrastructure 영역에서 구현하는 것이 시스템을 더 유연하고 테스트하기 쉽게 만들어진다.
무조건 Infrastructure 에 대한 의존을 없앨 필요는 없다.
예를 들어, Spring 환경에서 Application 은 트랜잭션 처리를 위해 @Transactional을 사용하는 것이 편리하다.
구현의 편리함은 DIP가 주는 장점만큼 중요하기 때문에 장점을 해치지 않는 범위에서 Application 과 Domain 영역에서 구현 기술에 대한 의존을 가져가는 것도 나쁘지 않다.
모듈 구성
아키텍처의 각 영역은 별도 패키지에 위치한다.
도메인이 크면 하위 도메인을 나누고, 각 하위 도메인마다 별도의 패키지를 구성하는 방식을 채택한다.
도메인 모듈은 도메인에 속한 aggregate 를 기준으로 다시 패키지를 구성한다.
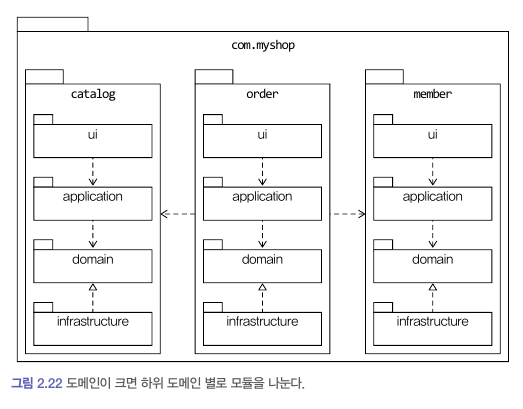
모듈 구조를 얼마나 세분화해야 하는지에 대해 정해진 규칙은 없다.
한 패키지에 너무 많은 타입이 몰리지 않도록 하고, 정해진 개수가 넘어가면 패키지를 분리하는 시도를 해보자!
