문자열
2010년도 이후, 우리는 유니코드라고 불리는 인코딩 방식이 통일된 시대를 살아가고 있다. 문자열을 다루는 디테일한 방식에 대해 전부 알 필요는 없지만, 프로그래밍 언어마다 문자열을 다루는 자료형의 차이를 이해하기 위해 문자열을 다루는 기본적인 방식은 알고 있어야 한다.
문자열 하나는 몇 바이트인가?
영어의 경우 알파벳 하나가 1 바이트(byte)를 차지하는 시절이 있었다. 그러나 글로벌 시대에는 유니코드를 사용해야 텍스트를 정확하게 저장할 수 있다. 프로그래밍 언어마다 문자열을 저장하는 자료형이 다 다르므로, "문자열 하나가 몇 바이트인가?"에 대한 답변은 이 자료형이 차지하고 있는 바이트를 이해할 때 답변할 수 있다.
유니코드는 무엇인가?
유니코드(Unicode)는 유니코드 협회(Unicode Consortium)가 제정하는 전 세계의 모든 문자를 컴퓨터에서 일관되게 표현하고 다룰 수 있도록 설계된 산업 표준이다. 이 표준에는 ISO 10646 문자 집합, 문자 인코딩, 문자 정보 데이터베이스, 문자를 다루기 위한 알고리즘 등을 포함하고 있다.
유니코드의 목적은 현존하는 문자 인코딩 방법을 모두 유니코드로 교체하는 이다.
인코딩(부호화)이란?
인코딩이란 어떤 문자나 기호를 컴퓨터가 이용할 수 있는 신호로 만드는 것이다.
이 신호를 입력하는 인코딩과 문자를 해독하는 디코딩을 하기 위해서는 미리 정해진 기준을 바탕으로 입력과 해독이 처리되어야 한다.
이렇게 인코딩과 디코딩의 기준을 문자열 세트 또는 문자셋(charset)이라고 한다. 이 문자셋의 국제 표준이 유니코드이다.
ASCII 문자는 무엇인가?
영문 알파벳을 사용하는 대표적인 문자 인코딩으로 7 비트로 모든 영어 알파벳을 표현할 수 있다. 52개의 영문 알파벳 대소문자와, 10개의 숫자, 32개의 특수 문자, 그리고 하나의 공백 문자를 포함한다.
유니코드는 ASCII를 확장한 형태이다.
UTF-8과 UTF-16의 차이점은 무엇인가?
UTF-8과 UTF-16은 인코딩 방식의 차이를 의미한다. UTF-8은 Universal Coded Character Set + Transformation Format – 8-bit의 약자로, UTF- 뒤에 등장하는 숫자는 비트(bit)이다.
1. UTF-8 특징: 가변 길이 인코딩
UTF-8은 유니코드 한 문자를 나타내기 위해 1 byte(= 8 bits)에서 4 bytes까지 사용한다.
- 원리
예를 들어, 코 라는 문자의 유니코드는 U+CF54 (16진수, HEX)로 표현된다. 이 문자를 이진법(binary number)으로 표시하면, 1100-1111-0101-0100 이 된다. 이 문자를 UTF-8로 표현하면, 다음과 같이 3byte의 결과로 표현된다.
# [데이터] UTF-8로 표현된 '코'
1110xxxx 10xxxxxx 10xxxxxx # x 안에 순서대로 값을 채워넣는다.
11101100 10111101 10010100# [코드] '코'라는 문자를 UTF-8로 표현할 수 있다.
let encoder = new TextEncoder(); // 기본 인코딩은 'utf-8'
encoder.encode('코') // Uint8Array(3) [236, 189, 148]
(236).toString(2) // "11101100"
(189).toString(2) // "10111101"
(148).toString(2) // "10010100"ASCII 코드는 7비트로 표현되고, UTF-8에서는 다음과 같이 1 byte의 결과로 만들 수 있다. 다음 예제는 b 라는 문자를 UTF-8로 인코딩한 결과이다.
# [데이터] UTF-8로 표현된 'b'
0xxxxxxx
01100010 [코드] 'b'라는 문자를 UTF-8로 표현할 수 있다.
encoder.encode('b') // Uint8Array [98]
(98).toString(2) // "1100010"이처럼, UTF-8은 1 byte에서 4 bytes까지의 가변 길이를 가지는 인코딩 방식이다. 네트워크를 통해 전송되는 텍스트는 주로 UTF-8로 인코딩된다. 사용된 문자에 따라 더 작은 크기의 문자열을 표현할 수 있기 때문이다. ASCII 문자는 1 바이트만으로 표현 가능한 것처럼 말이다.
UTF-8은 ASCII 코드의 경우 1 byte, 크게 영어 외 글자는 2byte, 3byte, 보조 글자는 4byte를 차지한다. 이모지는 보조 글자에 해당하기 때문에 4byte가 필요하다.
2. UTF-8 특징: 바이트 순서가 고정됨
UTF-16에 비해 바이트 순서를 따지지 않고, 순서가 정해져 있다.
3. UTF-16 특징: 코드 그대로 바이트로 표현 가능, 바이트 순서가 다양함
UTF-16은 유니코드 코드 대부분(U+0000부터 U+FFFF; BMP) 을 16 bits로 표현한다.
대부분에 속하지 않는 기타 문자는 32 bit(4 bytes)로 표현하므로 UTF-16도 가변 길이라고 할 수 있으나, 대부분은 2 바이트로 표현한다.
U+ABCD라는 16진수를 있는 그대로 이진법으로 변환하면 1010-1011-1100-1101 이다. 이 이진법으로 표현된 문자를 16 bits(2 bytes)로 그대로 사용하며, 바이트 순서(엔디언)에 따라 UTF-16의 종류도 달라진다.
UTF-8에서는 한글은 3 바이트, UTF-16에서는 2 바이트를 차지한다.
그래픽
비트맵(Bitmap)과 벡터(Vector)는 디지털 이미지의 종류이다. 디지털 이미지, 또는 이미지라고 불리는 용어는 디지털 카메라를 이용하여 현실세계의 사물을 촬영하거나 스캐너를 이용하여 사진이나 그림을 디지털 형태로 받아들인 것을 가리킨다. 서로 상반된 방식으로 이미지를 표현하기 때문에 비트맵(Bitmap)과 벡터(Vector)는 큰 차이점이 있다.
비트맵
비트맵(Bitmap)은 웹 상에서 디지털 이미지를 저장하는 데에 가장 많이 쓰이는 이미지 파일 포맷 형식이다. 일반적으로는 래스터 그래픽(점 방식)이라고 한다. 이미지의 각 점들을 격자형의 픽셀 단위로 구성되며, 한 지역을 차지하는 셀은 위치에 따라 다른 값을 갖는다.
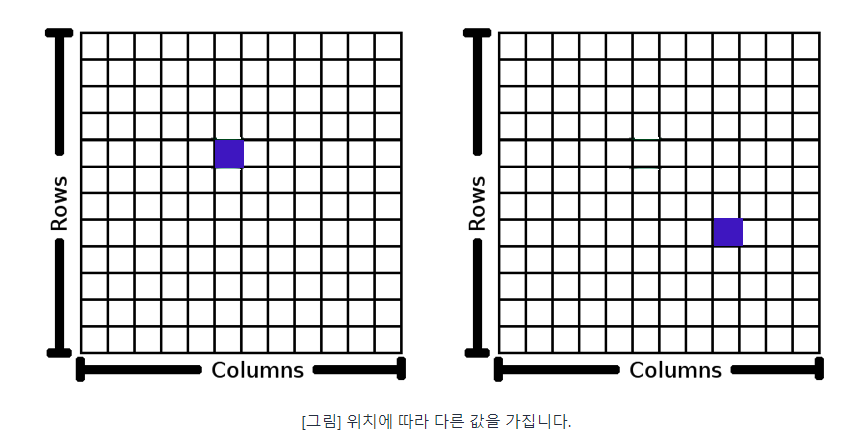
이런 비트맵은 사각의 픽셀 형태로 모여 있기 때문에 확대를 하면 ‘계단현상’ 또는 ‘깨짐 현상’이 발생하며, 경계가 뚜렷하지 않다는 특징이 있다.
이런 식으로 픽셀 단위로 이미지를 표현하는 방식은 컴퓨터에게 부담을 덜 주는 구조로 되어 있다. 또한 픽셀 하나 당 모두 색상 값을 가지고 있습니다. 따라서 이미지의 사이즈가 커질수록 용량 또한 무거워진다는 특징이 있다.
벡터
벡터(Vector)는 비트맵과는 완전히 다른 방식으로 이미지를 표현한다. 비트맵이 격자형의 픽셀 단위로 이미지를 구성한다면 벡터는 이미지를 수학적인 공식으로 표현한다.
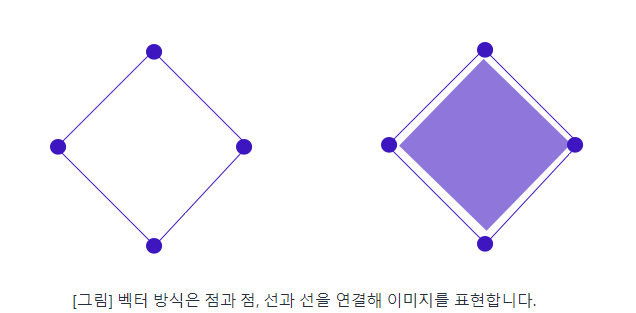
점과 점을 연결해 선을 표현하고 선과 선을 연결해 면을 표현하는 식의 수학적 원리로 그림을 그리기 때문에 비트맵과는 달리 아무리 확대를 해도 ‘계단현상’ 또는 ‘깨짐 현상’이 발생하지 않는다.
그러나 그렇기 때문에 벡터 방식으로 이미지를 표현하는 것은 비트맵에 비해 컴퓨터에게 부담을 가하는 방식이므로 주로 도형, 글자 등을 그리는 작업에 사용된다. 또한 수학적인 연산으로 만들어진 이미지이기 때문에 사이즈를 키워도 용량에는 변화가 없다는 특징 또한 있다.