TextRank로 중요한 키워드와 문장을 추출해보자.
TextRank로 실습을 한 것을 설명하기에 앞서 왜 TextRank를 사용하는지 밝히기 위해 프로젝트에 대한 설명과 TextRank에 대한 전반적인 설명을 하고자 합니다.
먼저 저희의 프로젝트 <백지 테스트 생성기>는
- 원텍스트에서 주요 단어를 추출하고 이를 빈 칸으로 만들어 빈 칸 문제를 제공합니다.
- 원텍스트에서 중요한 문장을 추출하고 이를 빈 칸으로 만들어 빈 칸 문제를 제공합니다.
- 원텍스트와 사용자가 답안으로 적은 텍스트, 이 둘을 비교하여 사용자가 원텍스트의 내용을 얼마나 정확하게 알고 있는지 채점을 하여 정답률을 제공합니다.
이 프로젝트를 기획하고 구현하는데 도움이 된 책과 링크들입니다.
- 자연어처리 바이블(임희석)
- 예제로 배우는 자연어 처리 기초(쇼홈 고시, 드와이트 거닝)
- TextRank 패키지 제공
- TextRank를 이해하기 위한 간단 설명 영상
1,2 단계에서 빈 칸으로 뚫어야할 중요한 단어, 문장을 텍스트에서 추출하기 위해 저희는 TextRank를 사용하기로 했습니다.
<TextRank란 무엇인가?>
- 문서 내 핵심 단어 혹은 문장을 추출하는 그래프 기반 랭킹 알고리즘으로 키워드 추출과 문서 요약(문장 추출)을 합니다.
- 비지도 학습 기반으로 학습과정이 따로 존재하지 않고 주어진 text 정보에만 의존하여 키워드, 문장을 추출합니다.
- 모든 도메인, 언어에 적용 가능하며, 모든 문장과 단어의 중요도를 산출합니다.
- vertex 집합과 edge 집합으로 이루어진 자료구조로, 두 vertex 간 연결인 voting을 바탕으로 중요도 점수를 산출합니다. 이때 vertex의 중요도 점수를 반복적으로 연산하여 순위를 매기기 때문에 그래프 기반 랭킹 알고리즘이라 하는 것입니다.
- 앞서 나온 PageRank(1998)의 원리를 텍스트문서에 적용한 방식입니다.
-기본 전처리 단계(토큰화, 품사태깅) / Syntactic Filtering을 ㅣ용한 vertex 생성 단계(특정 품사만 남겨두고 나머지 제거하는 필터링) / Co-occurrence relation에 따라 edge 생성하는 단계 등으로 나뉩니다.
키워드 추출을 하기 위해 먼저 단어 그래프를 만들어야 하는데 그 때 사용하는 함수입니다.
counter: 원 텍스트에서 min_count 이상 등장한 단어들
sents: list of str 형식의 문장들
tokenize: str 형식의 문장을 list of str 형식의 단어열로 나누는 토크나이저
from collections import Counter
def scan_vocabulary(sents, tokenize=None, min_count=2):
counter = Counter(w for sent in sents for w in tokenize(sent))
counter = {w:c for w,c in counter.items() if c >= min_count}
idx_to_vocab = [w for w, _ in sorted(counter.items(), key=lambda x:-x[1])]
vocab_to_idx = {vocab:idx for idx, vocab in enumerate(idx_to_vocab)}
return idx_to_vocab, vocab_to_idx
scan_vocabulary()는 원 텍스트에서 min_count = 2 이상 등장한 단어를 추출하고, string으로 들어온 문장을 쪼개 list로 만들고 Counter 클래스를 이용해 단어의 갯수(빈도수)를 셉니다.
두 단어의 co-occurrence(동시 출현 횟수)를 계산 합니다.
Co-occurrence: 문장 내에서 두 단어의 간격이 window인 횟수
결과는 dict_to_mat함수로 이 함수는 dict of dict 형식의 그래프를 scipy 의 sparse matrix 로 변환합니다.
from collections import defaultdict
def cooccurrence(tokens, vocab_to_idx, window=2, min_cooccurrence=2):
counter = defaultdict(int)
for s, tokens_i in enumerate(tokens):
vocabs = [vocab_to_idx[w] for w in tokens_i if w in vocab_to_idx]
n = len(vocabs)
for i, v in enumerate(vocabs):
if window <= 0:
b, e = 0, n
else:
b = max(0, i - window)
e = min(i + window, n)
for j in range(b, e):
if i == j:
continue
counter[(v, vocabs[j])] += 1
counter[(vocabs[j], v)] += 1
counter = {k:v for k,v in counter.items() if v >= min_cooccurrence}
n_vocabs = len(vocab_to_idx)
return dict_to_mat(counter, n_vocabs, n_vocabs)from scipy.sparse import csr_matrix
def dict_to_mat(d, n_rows, n_cols):
rows, cols, data = [], [], []
for (i, j), v in d.items():
rows.append(i)
cols.append(j)
data.append(v)
return csr_matrix((data, (rows, cols)), shape=(n_rows, n_cols))TextRank에서는 주로 명사, 동사, 형용사로만 단어 그래프를 만듭니다. 모든 종류의 단어를 이용하면 '와,과,은,는' 과 같은 조사나 의미가 없지만 자주 나오는 단어들이 다른 단어들과 압도적인 co-occurrence를 지니기 때문입니다.
위의 조사와 같은 stopwords(불용어)를 지정하여 정말로 중요한 키워드 후보만 그래프에 남겨둘 수 있게 함수를 만들어야 합니다.
그러므로 tokenize 함수는 불필요한 단어(불용어)를 모두 걸러내고, 필요한 단어 혹은 품사만 return하는 함수로 구현합니다.
이러한 사항들을 고려하면 단어 그래프를 만드는 word_graph 함수를 만들 수 있습니다.
def word_graph(sents, tokenize=None, min_count=2, window=2, min_cooccurrence=2):
idx_to_vocab, vocab_to_idx = scan_vocabulary(sents, tokenize, min_count)
tokens = [tokenize(sent) for sent in sents]
g = cooccurrence(tokens, vocab_to_idx, window, min_cooccurrence, verbose)
return g, idx_to_vocab그 뒤 만들어진 그래프에 PageRank를 학습하는 함수를 만듭니다.
TextRank는 PageRank의 원리를 텍스트에 적용하는 것이므로 텍스트를 분류한 뒤 PageRank의 원리를 이에 적용 시키는 함수가 필요합니다.
import numpy as np
from sklearn.preprocessing import normalize
def pagerank(x, df=0.85, max_iter=30):
assert 0 < df < 1
# initialize
A = normalize(x, axis=0, norm='l1')
R = np.ones(A.shape[0]).reshape(-1,1)
bias = (1 - df) * np.ones(A.shape[0]).reshape(-1,1)
# iteration
for _ in range(max_iter):
R = df * (A * R) + bias
return R이를 모두 정리하면 우리가 드디어 원하는 TextRank의 키워드 추출 함수를 만들 수 있습니다.
def textrank_keyword(sents, tokenize, min_count, window, min_cooccurrence, df=0.85, max_iter=30, topk=30):
g, idx_to_vocab = word_graph(sents, tokenize, min_count, window, min_cooccurrence)
R = pagerank(g, df, max_iter).reshape(-1)
idxs = R.argsort()[-topk:]
keywords = [(idx_to_vocab[idx], R[idx]) for idx in reversed(idxs)]
return keywords제가 담당한 부분은 키워드 추출이 아닌 문장 추출이므로 문장 추출을 위한 함수를 마저 이야기 하겠습니다.
TextRank를 이용하여 핵심 문장을 추출하기 위해서는 문장 그래프를 만들어야 합니다.
각 문장이 마디가 되며, edge weight 는 문장 간 유사도 입니다.
문장 간 유사도를 측정하기 위하여 TextRank는 해당 논문에서 아래와 같은 문장 간 유사도 척도를 사용합니다.
이 식은 두 문장에서 공통으로 등장한 단어의 개수를 각 문장의 단어 개수의 log 값의 합으로 나눈 것 입니다.
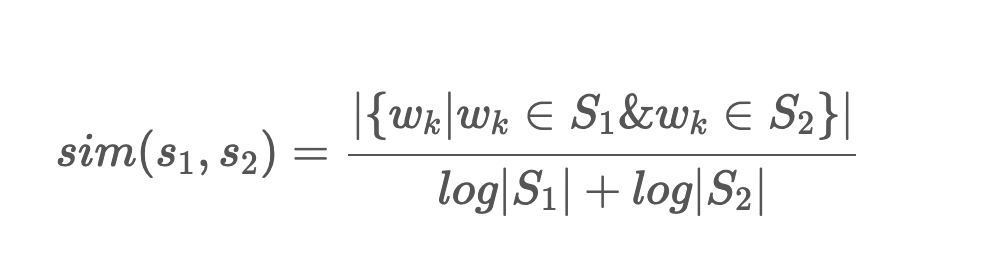
한 문장이 여러 문장과 높은 유사도를 지니기 위해서는 주어진 텍스트에서 자주 등장한 단어들을 여러 개 포함해야 합니다. tokenize 함수에서 관사와 같은 문법 기능의 단어들을 제거하고, 명사나 형용사와 같이 의미를 지니는 단어만 남겨 두었기 때문에 여러 문장들고 높은 유사도를 지니는 문장은, 주어진 문서 집합에서 자주 등장한 명사 / 동사 / 형용사들로 이뤄진 문장입니다. 문서 집합에서 반복적으로 사용되는 의미있는 단어들을 여러 개 지닌 문장은 핵심 문장일 가능성이 높습니다.
from collections import Counter
from scipy.sparse import csr_matrix
import math
def sent_graph(sents, tokenize, similarity, min_count=2, min_sim=0.3):
_, vocab_to_idx = scan_vocabulary(sents, tokenize, min_count)
tokens = [[w for w in tokenize(sent) if w in vocab_to_idx] for sent in sents]
rows, cols, data = [], [], []
n_sents = len(tokens)
for i, tokens_i in enumerate(tokens):
for j, tokens_j in enumerate(tokens):
if i >= j:
continue
sim = similarity(tokens_i, tokens_j)
if sim < min_sim:
continue
rows.append(i)
cols.append(j)
data.append(sim)
return csr_matrix((data, (rows, cols)), shape=(n_sents, n_sents))
def textrank_sent_sim(s1, s2):
n1 = len(s1)
n2 = len(s2)
if (n1 <= 1) or (n2 <= 1):
return 0
common = len(set(s1).intersection(set(s2)))
base = math.log(n1) + math.log(n2)
return common / base
def cosine_sent_sim(s1, s2):
if (not s1) or (not s2):
return 0
s1 = Counter(s1)
s2 = Counter(s2)
norm1 = math.sqrt(sum(v ** 2 for v in s1.values()))
norm2 = math.sqrt(sum(v ** 2 for v in s2.values()))
prod = 0
for k, v in s1.items():
prod += v * s2.get(k, 0)
return prod / (norm1 * norm2)def textrank_keysentence(sents, tokenize, min_count, similarity, df=0.85, max_iter=30, topk=5)
g = sent_graph(sents, tokenize, min_count, min_sim, similarity)
R = pagerank(g, df, max_iter).reshape(-1)
idxs = R.argsort()[-topk:]
keysents = [(idx, R[idx], sents[idx]) for idx in reversed(idxs)]
return keysents이렇듯 필요한 모든 함수를 알아보았으니 직접 문장을 추출해볼 것입니다.
AI 허브에서 받아둔 도서요약자료에서 도서 본문을 변수로 설정하고 문서요약 함수를 돌려보았습니다.
sents =['선거개혁도 유사한 문제가 있다.', '유권자들은 1979년 현급 지방인대 직접선거 개혁 –제한적 경쟁선거의 도입, 유권자의 후보추천권 보장 – 이후 좀 더 적극적이고 능동적으로 선거에 참여한다.', '그래서 1990년대에 들어 직접선거는 정치교육과 사회화를 통해 국민의 정권에 대한 정통성과 수용성을 높이려는 공산당의 동원수단에서 벗어나 점차로 국민의 의지와 요구를 실현하는 수단으로 발전하였다.', '그렇지만 중국의 모든 선거는 공산당 일당지배 체제하에 진행된다는 근본적 한계 외에도, 성급 지방인대 대표와 전국인대 대표선거는 여전히 간접선거로 실시되고 있으며, 중앙정부는 말할 것도 없고 지방정부 수장들도 모두 의회에서 간접선거로 선출된다는 문제점이 있다.', '이 때문에 선거를 통한 국민의 정치참여 확대도 전보다 나아지기는 했지만 여전히 많은 한계를 갖는다.']
summarizer = KeysentenceSummarizer(
tokenize = lambda x:x.split(),
min_sim = 0.3,
verbose = False
)
keysents = summarizer.summarize(sents, topk=3)
for _, _, sent in keysents:
print(sent)결과는
이 때문에 선거를 통한 국민의 정치참여 확대도 전보다 나아지기는 했지만 여전히 많은 한계를 갖는다.
그렇지만 중국의 모든 선거는 공산당 일당지배 체제하에 진행된다는 근본적 한계 외에도, 성급 지방인대 대표와 전국인대 대표선거는 여전히 간접선거로 실시되고 있으며, 중앙정부는 말할 것도 없고 지방정부 수장들도 모두 의회에서 간접선거로 선출된다는 문제점이 있다.
그래서 1990년대에 들어 직접선거는 정치교육과 사회화를 통해 국민의 정권에 대한 정통성과 수용성을 높이려는 공산당의 동원수단에서 벗어나 점차로 국민의 의지와 요구를 실현하는 수단으로 발전하였다.
이 3문장이 중요하다는 결과가 나왔습니다.(topk=3으로 해두었기 때문에 3문장이 결과로 나온 것입니다.)
그리고 summarizer의 R 에는 각 문장 별 중요도 (PageRank값) 가 저장되어 있습니다.
summarizer.R결과: array([0.15 , 0.15 , 0.79469195, 0.90454963, 1.30075842])
결과적으로 어느 문장이 가장 중요한지 중요도도 체크할 수 있었습니다.
저희의 서비스는 원텍스트에서 중요한 문장을 뽑아 해당 문장의 위치를 빈 칸으로 만들어서 문제형태로 제공하는 것이므로 어떤 문장을 뽑아내야할지에 대한 실습을 이 글에서 적은 것과 같이 진행할 수 있었습니다.
