금일 강의를 들으면서 velog에 주요내용을 정리하다보니
javaScript의 객체를 정리하면서
객체지향이다 key 와 value의 구조이다
명확하게 구분짓기에는 글이 산만해지므로
해당 글의 내용은 거기서 마무리 짓고
자료구조형을 따로 정리하고지 합니다.
어떠한 언어이든간의 자료구조형이라고 하는 것은 동일하며
크게 배열과 튜플의 구조를 가지고 있습니다.
배열이라는 것은
데이터의 집합으로 다음과 같은 구조를 띄고 있습니다.
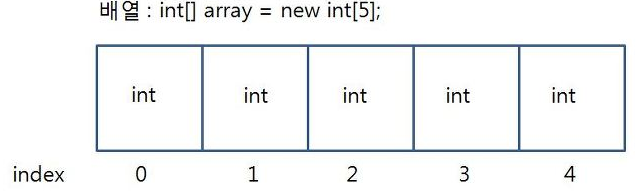
자료구조의 가장 기본적인 형태이고
전통적인 형태의 배열은
DataType [Array Lenty] 구조이며
배열이 정수형이면 정수만 배열안에 집어넣을 수 있게 되어 있습니다.
Tuple의 정의는 각 언어마다 다르긴 한데
데이터베이스에서 Tuple이라고 하면 Column이 포함된 개별적 Row를 말하며
Python에서 Tuple이라고 함은 배열과 같지만 수정할 수 없는 자료형을 의미하고 있습니다.
배열은 주소값을 기반으로 찾는 구조이기 때문에
기존 절차지향적인 C 언어에서 과거 많이 사용되었으나 길이가 길어지게 되면 주소값만 가지고 찾기가 어렵고 데이터가 방대해지면서
Dictionary 구조의 자료형태가 나타나게 되었고
Java 에서는 HashMap 이라고 하는 형태를 띄게 되었습니다.
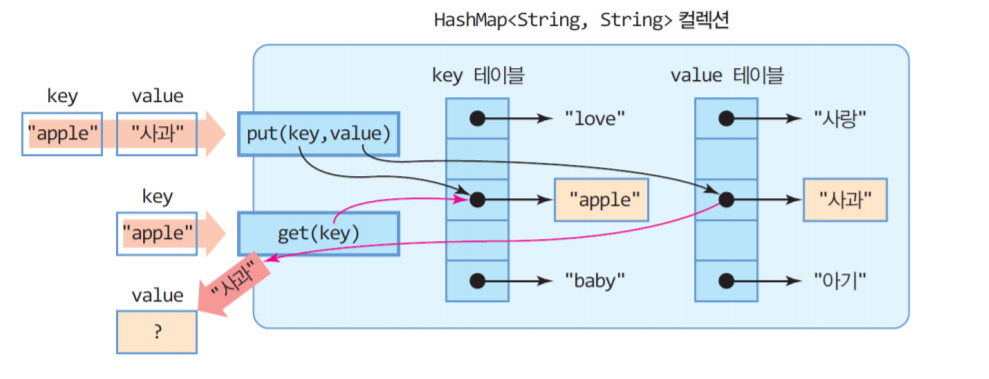
key와 value로 구분되는 구조기 때문에 자료검색에 있어 주소값으로 찾을 때보다 명시적이고 용이한 검색구조이지만 key value 반환만을 하므로
결과반환에 있어 제약적인 부분이 없지 않아 있고
Dictionary 구조 역시 <Iteger,String> 혹은 <String,String>
구조로 다른 자료형의 입력이
예를들어 <Iteger,String> 형태의 Map에 <String,String>이 입력될 수 없는 구조입니다.
그렇다면 Hash 구조의 자료형이 왜 자료검색에 용이한 구조인가?
이를 알기 위해서는 먼저 Hash라는 것이 무엇인지 알아야 합니다.
Hash라는 것은 임의의 길이의 데이터를 고정된 길이의 데이터로 매핑하는 함수를 의미하는데 가변이 아닌 고정 길이의 고유의 값이 도출되기때문에
암호화 기술 관련 분야에서도 Hash를 체크섬을 통한 검증 수단으로 사용하고 있습니다.
기존의 배열에 경우 빈번한 입력 삭제가 일어날 경우
인덱스가 늘어나고 줄어들면서 데이터가 많아질 경우 순회검색에 의하여
효율성이 떨어지게 되는데
Hash맵이나 Hash테이블은 값이 추가될 경우 새로운 Hash 도출값을
인덱스로 사용하므로 빈번히 데이터의 입력 및 수정 삭제가 일어나도
데이터의 이동이 일어나지 않기때문에 검색 성능이 떨어지지 않게 도비니다.
전에 C#의 DataTable이라고 하는 구조의 자료형만을 가지고
데이터를 찾거나 할 경우 처음부터 순회검색을 할 수밖에 없어
성능적인 문제가 많았는데 이 때 DataTable을 사용한 이유는
코드 작성이 상대적으로 용이하고 데이터베이스에서 조회해온 튜플구조의 데이터를 가지고 처리해야 했기 때문에 사용했었습니다.
데이터의 처리보다는 조회한 결과를 한번에 보여주어야 했기 때문에 사용한 것이고 Hash맵은 당연히 Key Value만을 반환하는 구조이므로
이러한 형태의 구조로 데이터를 한번에 가져오기에는 적합하지는 않다고 생각합니다.
검색해보니 Java에서는 JTable이라고 하는 것을 통해 DataTable과 같은 형태의 조회하면을 구현할수 있다고 하니 확인해봐야 하겠습니다.
JavaScrip에서 객체라고 하는 것은 이러한 Hash Map 형태도 포함되지만
객체 자기 자신이 될 수도 있고 객체 안에 객체라던가 fucntion이 포함될 수도 있어 JavaScript의 객체는 Key와 Value의 구조이다라고
단언할 수는 없습니다.
따로 자료구조형을 정리하면서
자료구조에 대한 예시자료를 찾아보자면 한도 끝도 없이 나오겠지만
굳이 일일이 옮겨적지 않은 것은
본인이 이해한 내용이 우선이지 받아쓰기만 해서는
남의 블로그에 대한 미러링 밖에 되지 않으므로
여기서 정리를 마칩니다.
